Sección 5 Análisis de Conglomerados
5.1 Distancias y disimilitudes
Antes de entrar al tema de análisis de clústers es importante introducir los conceptos de distancias y disimilitudes o similitudes.
Una medida de disimilitud o distancia entre dos sujetos muy distintos será grande y por el contrario, una medida de similitud entre ellos será pequeña.
Una distancia es una función \(d: \mathcal{X}\times \mathcal{X}\to \mathbb{R}\) que cumple las siguientes propiedades:
Para cualesquiera \(x,y\in\mathcal{X}\) se tiene que \(d(x,y)\geq 0\).
Se cumple que \(d(x,y)=0\) si y sólo si \(x=y\).
Para cualesquiera \(x,y\in\mathcal{X}\) se cumple que \(d(x,y) = d(y,x)\) (condición de simetría).
Para cualesquiera \(x,y,z\in\mathcal{X}\) se cumple la desigualdad del triángulo: \[ d(x,y)\leq d(x,z) + d(z,y). \]
Dos de las distancias más comunes en estadística para variables aleatorias multivariadas cuantitativas son la distancia euclidiana y la distancia de Mahalanobis:
Si \(\bar{x},\bar{y}\in\mathbb{R}^n\), entonces la distancia euclidiana \(d_E\) entre \(\bar{x}\) y \(\bar{y}\) está dada por \[ d_E\left( \bar{x}, \bar{y} \right) = \left[ \left(\bar{x} - \bar{y}\right)'\cdot \left( \bar{x}- \bar{y} \right) \right]^{\frac{1}{2}} \]
Si \(\bar{x},\bar{y}\in\mathbb{R}^n\), entonces la distancia de Mahalanobis \(d_M\) entre \(\bar{x}\) y \(\bar{y}\) está dada por \[ d_E\left( \bar{x}, \bar{y} \right) = \left[ \left(\bar{x} - \bar{y}\right)' \Sigma^{-1} \left( \bar{x}- \bar{y} \right) \right]^{\frac{1}{2}} \] donde \(\Sigma^{-1}\) denota a la matriz inversa de la matriz de covarianzas de \(\bar{x}\) y \(\bar{y}\).
Existen otras distancias, como la distancia de Gower que puede ser utilizada para estudiar variables aleatorias con entradas cuantitativas y/o cualitativas.
Informalmente, una similitud es una medida entre dos objetos de que tanto se parecen. Por lo cual entre más parecidos sean los dos objetos su medida de similitud será más grande. Usualmente toma valores positivos entre 0 y 1.
Formalmente, una similitud es una función \(s: \mathcal{X}\times \mathcal{X} \to \mathbb{R}\) que típicamente satisface las siguientes dos condiciones:
\(s(x,y)=1\) si y sólo si \(x=y\). Además \(0\leq s\leq 1\).
\(s(x,y)=s(y,x)\) para todo \(x\) y \(y\) (condición de simetría).
Usualmente, la función de similitud satisface \(s(x,y)\geq 0\) pero existen ejemplos de similitudes que no lo satisfacen, por ejemplo: el coeficiente de correlación y los productos escalares. Sin embargo, si la función de similitud no es positiva y está acotada siempre es posible transformarla en una función de similitud positiva añadiendo una constante, es decir, podemos escribir nuestra nueva función de similitud \(\tilde{s}\) como \(\tilde{s}(x,y)=s(x,y)+c\), donde \(c\) es una constante positiva lo suficientemente grande.
A diferencia de una distancia o una disimilitud, no existe un análogo para la desigualdad del triángulo para la similitud.
Informalmente, una disimilitud entre dos objetos es una medida del grado en el cual dos objetos son diferentes. Como es de esperarse, una disimilitud debe ser baja si se consideran pares de objetos que son similares.
De manera precisa, una disimilitud es una función \(d: \mathcal{X}\times \mathcal{X} \to \mathbb{R}\) que satisface las siguientes dos condiciones:
Para cualquier \(x\in\mathcal{X}\) se tiene que \(d(x,x) = 0\).
Para cualesquiera \(x,y \in \mathcal{X}\) se cumple que \(d(x,y)\geq 0\) (condición de no negatividad).
Para cualesquiera \(x,y\in\mathcal{X}\) se cumple que \(d(x,y) = d(y,x)\).
Es importante mencionar que, en la literatura de análisis de datos como data mining y algunos textos de estadística, a las disimilitudes también se les nombra distancias, lo cual es incorrecto. Lo que si ocurre es que toda distancia (o métrica) es una disimilitud, pero no toda disimilitud es una distancia.
Algunas disimilitudes usuales de acuerdo al tipo de dato que se esté trabajando son las siguientes:
Tipo nominal: La disimilitud más sencilla es \[ d(x,y) = \left\{ \begin{matrix} 0 & \text{ si } x= y \\ 1 & \text{ si } x\neq y \end{matrix} \right. \]
Tipo ordinal: La disimilitud más sencilla es \[ d(x,y) = \frac{|x-y|}{n-1} \] donde suponemos que hay \(n\) datos, y a cada uno de ellos se les ha asignado un valor entero de \(0\) a \(n-1\).
Tipo intervalo: La disimilitud más sencilla es \[ d(x,y) = \| x- y\| \] donde \(\| \cdot \|\) denota la distancia euclidiana usual.
A continuación se describen algunas de las distancias y disimilitudes más usuales entre individuos con datos numéricos, binarios, categóricos y mixtos.
5.1.1 Distancia euclidiana
Es la distancia usual entre dos puntos en el espacio Euclidiano \(\mathcal{X}\). Cumple las siguientes propiedades:
- \(d(X,Y)\geq 0\) para todo \(X,Y\in \mathcal{X}\) y \(d(X,Y)=0\) si y sólo si \(X=Y\)
- \(d(X,Y)=d(Y,X)\) para todo \(X,Y\in\mathcal{X}\) (Simetría)
- $d(X,Z)d(X,Y) + d(Y,Z) $ para todo \(X,Y,Z\in\mathcal{X}\)(Desigualdad del triángulo)
Tipos de datos: Numéricos
Fórmula y explicación: Sea \(\mathcal{X}\) el espacio euclidiano de dimensión \(n\) y sean \(X,Y\in\mathcal{X}\) dos puntos en el espacio con coordenadas \(X=(x_1,...,x_{n})\) y \(Y=(y_{1},...,y_{n})\). Entonces su distancia euclidiana esta dada por: \[ d(X,Y)=\sqrt{\sum_{i=1}^{n}(x_{i}-y_{i})^{2}}\]
5.1.2 Distancia de Minkowski
Es una generalización de la distancia euclidiana. Se llama así en honor al matemático Hermann Minkowski.
Tipos de datos: Numéricos.
Fórmula y explicación:Sean \(X,Y\in\mathcal{X}\) dos puntos en el espacio con coordenadas \(X=(x_1,...,x_{n})\) y \(Y=(y_{1},...,y_{n})\) y sea \(p\) un entero. Entonces su distancia Minkowski esta dada por: \[ d(X,Y)=\left( \sum_{i=1}^{n} |\ x_{i}-y_{i}\ |^{p}\right)^{\frac{1}{p}}\] Para \(p\geq 1\) esta distancia es una métrica. Si \(p<1\) no se satisface la desigualdad del triángulo y por lo tanto no es una métrica. Si \(p=2\) es la distancia euclidiana y si \(p=1\) es la distancia de Manhattan(o city block).
5.1.3 Distancia City block
También se conoce como la distancia del taxista o distancia de Manhattan. Esta distancia no es única en el sentido de que hay más de un camino de distancia mínima para llegar de un punto a otro. Se le conoce como distancia del taxista o distancia de Manhattan porque hace referencia a la forma en que un automovil puede ir de un punto a otro en un diseño cuadricular de las calles de Manhattan. En la figura siguiente, podemos la distancia City block entre los puntos \(X,Y\) esta representada con los colores rojo, azul y verde, los tres caminos tienen la misma longitud, mientras que la distancia en morado es la distancia euclidiana entre los puntos.
Tipos de datos: Numéricos
Fórmula y explicación: Sean \(X,Y\in\mathcal{X}\) dos puntos en el espacio con coordenadas \(X=(x_1,...,x_{n})\) y \(Y=(y_{1},...,y_{n})\). Entonces su distancia city block esta dada por: \[ d_{1}(X,Y) = \parallel X - Y \ \parallel = \sum_{i=1}^{n} |\ x_{i} - y_{i}\ | \] En el caso de la figura, la distancia de city block (en color azul, rojo o verde) sería \(15\) si consideramos que cada cuadrito tiene longitud \(1\).
5.1.4 Disimilitud calculando Simple Matching
El coeficiente de concordancia simple, llamado coeficiente simple matching (\(\mathrm{SMC}\)) o coeficiente de Rand se trata de la razón de coincidencias respecto al número total de valores. Se ofrece una ponderación igual a las coincidencias y a las no coincidencias. Toma valores entre \(0\) y \(1\). La disimilitud calculada vía simple matching o distancia simple matching, que mide la disimilitud entre las muestras, se calcula restando el \(\mathrm{SMC}\) a \(1\).
Tipos de datos: Binarios
Fórmula y explicación: Consideremos \(A\) y \(B\) dos objetos con \(n\) atributos binarios, esto es, cada atributo vale \(0\) o \(1\). El número total para cada combinación de atributos para \(A\) y \(B\) se obtiene como sigue:
Denotamos \(M_{11}\) al número total de atributos donde \(A\) y \(B\) tienen un valor de \(1\).
Denotamos \(M_{01}\) al número total de atributos donde \(A\) vale \(0\) y \(B\) vale \(1\).
Denotamos \(M_{10}\) al número total de atributos donde \(A\) vale \(1\) y \(B\) vale \(0\).
Denotamos \(M_{00}\) al número total de atributos donde \(A\) y \(B\) tienen un valor de \(0\).
Entonces \(M_{00}+ M_{01} + M_{10} + M_{11} = n\). La distancia simple matching \(\mathrm{SMD}\) entre \(A\) y \(B\) se define como \[ \mathrm{SMD} = 1 - \mathrm{SMC}, \] donde \(\mathrm{SMC}\) es el coeficiente simple matching dado por \[ \mathrm{SMC} = \frac{M_{00} + M_{11}}{M_{00} + M_{01} + M_{10} + M_{11}}. \]
5.1.5 Disimilitud calculando el coeficiente de Jaccard
El coeficiente de Jaccard fue presentado como coefficient de communauté por Paul Jaccard en 1912 y posteriormente fue formulado de manera independiente por T. Tanimoto en 1958, y toma valores entre \(0\) y \(1\). Se trata de un índice en el que no se toman en cuenta las ausencias conjuntas. Se ofrece una ponderación igual a las coincidencias y a las no coincidencias. Se conoce también como razón de similaridad.
La disimilitud de Jaccard (habitualmente conocida como distancia de Jaccard) se calcula restando el coeficiente de Jaccard a \(1\). La distancia de Jaccard suele usarse para calcular una matriz \(n\times n\) para la agrupación y el escalamiento multidimensional de \(n\) conjuntos de muestras.
Tipos de datos: Binarios
Fórmula y explicación: Consideremos \(A\) y \(B\) dos objetos con \(n\) atributos binarios, esto es, cada atributo vale \(0\) o \(1\). El número total para cada combinación de atributos para \(A\) y \(B\) se obtiene como sigue:
Denotamos \(M_{11}\) al número total de atributos donde \(A\) y \(B\) tienen un valor de \(1\).
Denotamos \(M_{01}\) al número total de atributos donde \(A\) vale \(0\) y \(B\) vale \(1\).
Denotamos \(M_{10}\) al número total de atributos donde \(A\) vale \(1\) y \(B\) vale \(0\).
Denotamos \(M_{00}\) al número total de atributos donde \(A\) y \(B\) tienen un valor de \(0\).
Entonces \(M_{00}+ M_{01} + M_{10} + M_{11} = n\). La distancia de Jaccard \(d_{J}\) se define como \[ d_{J} = \frac{M_{01} + M_{10}}{M_{01} + M_{10} + M_{11}}. \]
Se cumple que \(d_{J} = 1- J\) donde \(J\) es el índice (o coeficiente) de Jaccard dado por \[ J = \frac{M_{11}}{M_{01} + M_{10} + M_{11}}. \]
También, para fines del diseño, si \(A\) y \(B\) son conjuntos vacíos, entonces \(d_{J} = 0\) (o equivalentemente, \(J(A,B) = 1\)).
5.1.6 Disimilitud calculando el coeficiente de Czekanowski
El coeficiente Czekanowski es uno en el que no se toman en cuenta las ausencias conjuntas y donde las coincidencias se ponderan doblemente en datos binarios. También se conoce como coeficiente de Dice, coeficiente de S{}rensen o coeficiente de S{}rensen–Dice (quienes los derivaron de manera independiente en 1948). Fue desarrollado en 1913 por Jan Czekanowski para establecer relaciones entre dialectos y lenguas, pero realmente se puede aplicar a cualquier comparación entre individuos calificados por múltiples atributos, por ejemplo, razas, especies de plantas o de animales, biocenosis, biotopos y hábitats, culturas, etc. La calificación puede ser cualitativa o cuantitativa y se basa en la comparación atributo por atributo de cada par de individuos de una colección. Este índice toma valores entre \(0\) y \(1\).
La disimilitud asociada al coeficiente de Czekanowski se obtiene restando dicho índice a \(1\). Contrario a la distancia de Jaccard, esta disimilitud no cumple la desigualdad del triángulo y por ello no es una distancia verdadera.
Tipos de datos: Binarios
Fórmula y explicación: Consideremos \(A\) y \(B\) dos objetos con \(n\) atributos binarios, esto es, cada atributo vale \(0\) o \(1\). El número total para cada combinación de atributos para \(A\) y \(B\) se obtiene como sigue:
Denotamos \(M_{11}\) al número total de atributos donde \(A\) y \(B\) tienen un valor de \(1\).
Denotamos \(M_{01}\) al número total de atributos donde \(A\) vale \(0\) y \(B\) vale \(1\).
Denotamos \(M_{10}\) al número total de atributos donde \(A\) vale \(1\) y \(B\) vale \(0\).
Denotamos \(M_{00}\) al número total de atributos donde \(A\) y \(B\) tienen un valor de \(0\).
La disimilitud asociada al coeficiente de Czekanowski se calcula como \[ d_{Cz} = 1 - \frac{2M_{11}}{2M_{11} + M_{10} + M_{01}} \]
De manera equivalente, al considerar la formulación dada por S{}ren y Dice, la disimilitud anterior se puede formular como \[ d_{Cz} = 1 - \frac{2 |A\cap B|}{|A| + |B|} \] donde \(|\cdot|\) denota la cardinalidad de los respectivos conjuntos.
5.1.7 Disimilitud de \(1\)-coincidencias de Sneath
Medida de disimilitud propuesta en 1958 por Sneath y Sokal para variables binarias. Cumple las propiedades de simetría entre \(a\) y \(d\) (atributos en que las unidades coinciden), mientras que su rango está entre 0 y 1.
Tipos de datos: Binarios
Fórmula y explicación: \[ d_{ij} = 1 - c_{ij} \] con \[ c_{ij} = \frac{a+d}{a+b+c+d} \] donde \(a\) y \(d\) son los atributos en que las unidades coinciden mientras el denominador es la suma de todos los valores de la tabla de contingencia.
5.1.8 Distancia de Gower
El coeficiente de similitud de Gower propuesto por Gower en 1971 permite la manipulación simultánea de variables cuantitativas y cualitativas en una base de datos, mediante la aplicación de este coeficiente se logra hallar la similitud entre individuos a los cuales se les han medido una serie de características en común. Una similaridad alta, es decir cercana a 1, indicara gran homogeneidad entre los individuos; por el contrario, una similaridad cercana a cero indica que los individuos son diferentes.
Tipos de datos: Mixtos: variables cuantitativas y cualitativas
Fórmula y explicación:
\[
d_{ij}^{2} = 1-s_{ij}
\]
donde
\[
s_{i j} = \frac{\sum\limits_{h=1}^{p_1}\left(1-\frac{\left|x_{ih}-x_{jh}\right|}{G_h}\right) + a + \alpha}{p_{1}+p_{2}-d+p_{3}}
\]
con \(p_1\) es el número de variables cuantitativas, \(a\) y \(d\) son el número de coincidencias en 1 (presencia de la característica) y el número de coincidencias en 0 (ausencia de la caracteristica) respectivamente para las \(p_2\) variables binarias, \(\alpha\) es el número de coincidencias para las \(p_3\) variables cualitativas y \(G_h\) es el rango de la \(h\)-ésima variable cuantitativa.
5.2 Clustering jerárquico
En muchos problemas no es factible examinar todas las posibles particiones de un conjunto de objetos, incluso con computadoras muy rápidas. Por ello se han desarrollado algoritmos de agrupamiento que permiten obtener grupos razonables sin evaluar todas las configuraciones posibles. Entre ellos destacan los métodos de clustering jerárquico.
Estos métodos generan una estructura en forma de árbol, llamada dendrograma, que muestra cómo se agrupan o dividen los objetos progresivamente, y el nivel (distancia) en el que lo hacen.
Existen dos enfoques principales:
- Métodos jerárquicos aglomerativos: Comienzan con cada objeto como un grupo individual. El proceso es:
- Cada objeto constituye inicialmente un cluster.
- Se calculan las distancias entre todos los clusters.
- Se fusionan los dos clusters más similares.
- Se repite el proceso hasta obtener un único cluster.
Es decir, el algoritmo va desde varios clusters hasta uno solo.
- Métodos jerárquicos divisivos: Funcionan de forma inversa:
- Se inicia con un único cluster que contiene a todos los objetos.
- Se divide el conjunto en dos subgrupos lo más disímiles posible.
- Se continúa dividiendo hasta llegar a clusters individuales.
Este enfoque desciende desde un solo cluster hacia muchos.
En este capítulo nos concentraremos en los métodos jerárquicos aglomeraticos, incluyendo:
- Single linkage agglomerative clustering o método de la liga sencilla o del vecino más cercano.
- Complete linkage agglomerative clustering o método de la liga completa o del vecino más lejano.
- Average linkage agglomerative clustering o métdod de la liga promedio.
- Ward’s minimum variance clustering o método Ward.
El algoritmo aglomerativo paso a paso, se puede entender como sigue:
Dado un conjunto de \(N\) objetos:
Iniciar con \(N\) clusters individuales y construir una matriz de distancias \[ D = (d_{ij}). \]
Buscar el par de clusters \((U,V)\) cuya distancia \(d_{UV}\) sea mínima.
Fusionar los clusters \(U\) y \(V\) formando un nuevo cluster \((UV)\).
Actualizar la matriz de distancias eliminando filas y columnas correspondientes a \(U\) y \(V\), y añadiendo la distancia del nuevo cluster con respecto a los restantes.
Repetir los pasos anteriores hasta obtener un único cluster.
El resultado final se representa en un dendrograma, donde se observan las uniones entre clusters y los niveles (distancias) a los que estas ocurren.
5.2.1 Clustering aglomerativo de la liga sencilla
El método de single linkage (enlace simple o vecinos más cercanos) utiliza como criterio de similitud entre clusters la distancia mínima entre cualquiera de los elementos de los grupos involucrados, es decir, se toma la mínima de todas las posibles distancias entre los objetos que pertenecen a distintos conglomerados. Inicialmente, debemos encontrar la distancia más pequeña \(D = \{d_{ik}\}\) y unir los objetos correspondientes, es decir \(U\) y \(V\) para obtener el cluster \((UV)\). Después, para el paso 3 del algoritmo general, la distancia entre \((UV)\) y cualquier otro cluster \(W\) se calcula como: \[ d_{(UV),W} = \min\{d_{UW},d_{VW}\}, \]
donde \(d_{UW}\) y \(d_{VW}\) representan las distancias entre los vecinos más cercanos del cluster \(U\) con respecto a los elementos de \(W\), y del cluster \(V\) con respecto a los elementos de \(W\), respectivamente.
El proceso de aglomeración bajo este criterio se puede visualizar en un dendrograma. En dicho diagrama, las ramas representan clusters, y los nodos donde estas ramas se unen representan fusiones. La altura a la que se unen indica la distancia a la cual se fusionaron los clusters.

El resultado de la agrupación puede visualizarse como un dendrograma. El inconveniente del dendrograma resultante de un clustering de liga sencilla a menudo muestra el encadenamiento de las muestras. Los clústeres formados se ven forzados a unirse debido a que los elementos individuales están cerca unos de otros, mientras que muchos elementos de cada clúster pueden estar muy alejados entre sí. Otro inconveniente relevante del clustering de la liga sencilla es que podría ser difícil de interpretar en términos de particiones de los datos. Es una desventaja real del clustering de la liga sencilla porque estamos interesados en las particiones de los datos. Este método se tiende a desempeñar bien cuando hay grupos de forma elongada, conocidos como tipo cadena.
Veamos un ejemplo.
Ejemplo 1: Consideremos la siguiente matriz de distancias \[ D = (d_{ik}) = \begin{pmatrix} 0 & 9 & 3 & 6 & 11 \\ 9 & 0 & 7 & 5 & 10 \\ 3 & 7 & 0 & 9 & 2 \\ 6 & 5 & 9 & 0 & 8 \\ 11 & 10 & 2 & 8 & 0 \end{pmatrix} \]
Inicialmente cada objeto se considera un cluster individual. Buscamos la menor distancia en la matriz \(D\):
\[ \min_{i,k}(d_{ik}) = d_{53} = 2. \]
Por lo tanto, los objetos \(5\) y \(3\) se fusionan y forman el cluster \((35)\).
Ahora se debe actualizar la matriz de distancias para este nuevo cluster. La distancia entre \((35)\) y los restantes objetos se calcula tomando el mínimo de las distancias existentes. Por ejemplo:
\[ d_{(35)1} = \min\{d_{31}, d_{51}\} = \min\{3, 11\} = 3, \]
\[ d_{(35)2} = \min\{d_{32}, d_{52}\} = \min\{7, 10\} = 7, \]
\[ d_{(35)4} = \min\{d_{34}, d_{54}\} = \min\{9, 8\} = 8. \]
Eliminando filas y columnas correspondientes a \(3\) y \(5\), obtenemos una nueva matriz de distancias:
\[ \begin{array}{c|cccc} N & (35) & 1 & 2 & 4 \\ \hline (35) & 0 & 3 & 7 & 8 \\ 1 & 3 & 0 & 9 & 6 \\ 2 & 7 & 9 & 0 & 5 \\ 4 & 8 & 6 & 5 & 0 \end{array} \]
La distancia mínima entre estos clusters es ahora
\[ d_{(35)1} = 3. \]
Entonces se fusiona el objeto \(1\) con el cluster \((35)\), formando así \((135)\).
Se actualizan nuevamente las distancias:
\[ d_{(135)2} = \min\{d_{(35)2}, d_{12}\} = \min\{7, 9\} = 7, \]
\[ d_{(135)4} = \min\{d_{(35)4}, d_{14}\} = \min\{8, 6\} = 6. \]
La nueva matriz queda:
\[ \begin{array}{c|ccc} N & (135) & 2 & 4 \\ \hline (135) & 0 & 7 & 6 \\ 2 & 7 & 0 & 5 \\ 4 & 6 & 5 & 0 \end{array} \]
La mínima distancia es ahora \(d_{42} = 5\), por lo que los objetos \(4\) y \(2\) se fusionan formando \((24)\).
Finalmente, sólo quedan dos clusters: \((135)\) y \((24)\). Su distancia es:
\[ d_{(135)(24)} = \min\{d_{(135)2}, d_{(135)4}\} = \min\{7, 6\} = 6. \]
De esta manera se obtiene la última fusión, y el clustering final reúne a los cinco individuos:
\[ (13524). \]
Nota: Realicemos el dendrograma a mano primero, nos daremos cuenta de que muestra claramente las distancias a las que se produjeron las fusiones: primero a nivel \(2\), luego a \(3\), después a \(5\) y finalmente a \(6\).
En aplicaciones reales, es frecuente detener el proceso en un nivel intermedio del dendrograma, cuando el número de clusters resultante es interpretativamente significativo.
Veamos ahora el ejemplo en R.
A <- c(0,9,3,6,11)
B <- c(9,0,7,5,10)
C <- c(3, 7, 0, 9, 2)
D <- c(6, 5, 9, 0, 8 )
E <- c(11, 10, 2, 8, 0)
df <- data.frame(A,B,C,D,E, row.names = c("A","B","C","D","E"))
df %>% knitr::kable(format = "html")| A | B | C | D | E | |
|---|---|---|---|---|---|
| A | 0 | 9 | 3 | 6 | 11 |
| B | 9 | 0 | 7 | 5 | 10 |
| C | 3 | 7 | 0 | 9 | 2 |
| D | 6 | 5 | 9 | 0 | 8 |
| E | 11 | 10 | 2 | 8 | 0 |
dist <- as.dist(df, diag= TRUE)
cluster_single <- hclust (d = dist, method = 'single')
plot(cluster_single)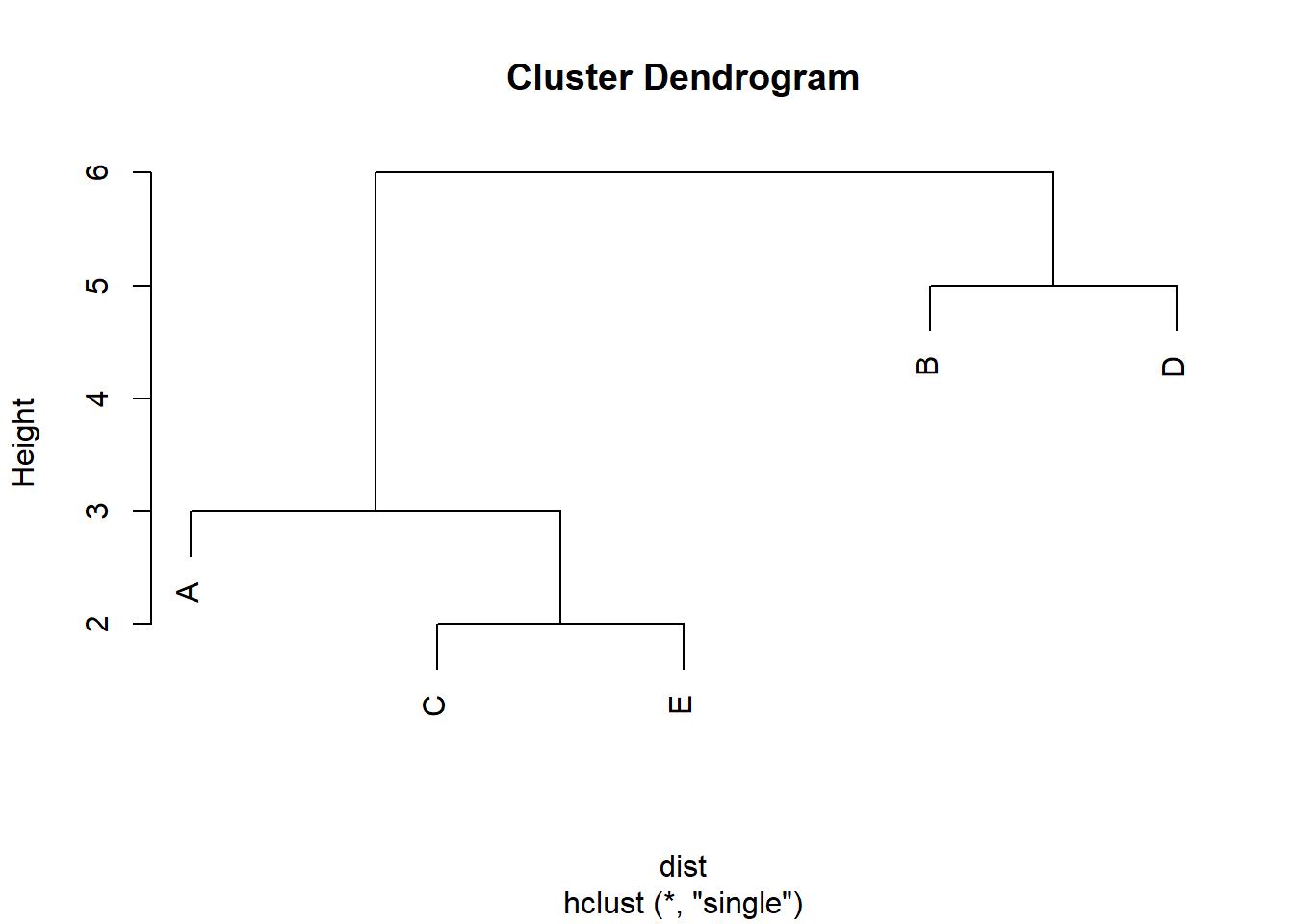
Figure 5.1: Cluster con el método single.
5.2.2 Clustering aglomerativo de la liga completa
El método de complete linkage (o enlace completo o clustering del vecino más lejano) sigue el mismo procedimiento general que el método de enlace simple. Sin embargo, existe una diferencia fundamental: en cada etapa del algoritmo, la distancia entre dos clusters se define como la distancia (o disimilitud) máxima entre sus elementos.
Iniciamos de nuevo encontrando la distancia más pequeña y creando el primer clúster \(UV\), de ahí calculamos la distancia entre un cluster formado por dos objetos \(U\) y \(V\) y otro cluster \(W\), como:
\[ d_{(UV),W} = \max\{d_{UW},\,d_{VW}\}. \]
Esto significa que la similitud entre dos clusters está determinada por el par de elementos más alejados entre ellos. De esta manera, el método de enlace completo garantiza que los objetos dentro de cada cluster no difieran entre sí más allá de una distancia máxima preestablecida.

La agrupación de la liga completa evita el inconveniente de encadenar las muestras por el método de la liga simple. El encadenamiento completo tiende a encontrar muchos pequeños grupos separados. Este método se desempeña bien cuando los conglomerados son de forma circular.
Ejemplo 2: Consideremos la misma matriz del ejemplo anterior:
\[ D = (d_{ik}) = \begin{pmatrix} 0 & 9 & 3 & 6 & 11 \\ 9 & 0 & 7 & 5 & 10 \\ 3 & 7 & 0 & 9 & 2 \\ 6 & 5 & 9 & 0 & 8 \\ 11 & 10 & 2 & 8 & 0 \end{pmatrix} \]
Identificamos los objetos más cercanos. Como antes,
\[ \min_{i,k}(d_{ik}) = d_{53} = 2, \]
se fusionan los objetos \((3)\) y \((5)\) formando el cluster \((35)\).
Calculamos la distancia entre el cluster \((35)\) y los restantes objetos, ahora usando máximos:
\[ d_{(35),1} = \max\{d_{31}, d_{51}\} = \max\{3, 11\} = 11, \]
\[ d_{(35),2} = \max\{d_{32}, d_{52}\} = \max\{7, 10\} = 10, \]
\[ d_{(35),4} = \max\{d_{34}, d_{54}\} = \max\{9, 8\} = 9. \]
Al eliminar filas y columnas de \(3\) y \(5\), la matriz queda:
\[ \begin{array}{c|cccc} N & (35) & 1 & 2 & 4 \\ \hline (35) & 0 & 11 & 10 & 9 \\ 1 & 11 & 0 & 9 & 6 \\ 2 & 10 & 9 & 0 & 5 \\ 4 & 9 & 6 & 5 & 0 \end{array} \]
La mínima distancia ahora es entre \((2)\) y \((4)\):
\[ d_{42} = 6. \]
Se fusionan para formar el nuevo cluster \((24)\).
Calculamos distancias entre \((35)\) y \((24)\):
\[ d_{(24),(35)} = \max\{d_{2,(35)}, d_{4,(35)}\} = \max\{10, 9\} = 10. \]
Queda además comparar con el objeto \((1)\):
\[ d_{(24),1} = \max\{d_{21}, d_{41}\} = \max\{9, 6\} = 9, \]
La nueva matriz queda:
\[ \begin{array}{c|ccc} N & (35) & (24) & 1 \\ \hline (35) & 0 & 10 & 11 \\ (24) & 10 & 0 & 9 \\ 1 & 11 & 9 & 0 \end{array} \]
La menor distancia es \(9\), entre \((24)\) y \(1\), de modo que se forma el cluster \((124)\).
Finalmente se compara con \((35)\):
\[ d_{(124),(35)} = \max\{ d_{1,(35)}, d_{(24),(35)}\} = \max\{11, 10\} = 11. \]
Se obtiene el cluster total:
\[ (12345). \]
Nota: Representamos este resultado en el dendrograma correspondiente.
Al comparar el dendrograma generado por enlace simple con el de enlace completo, se observa que la asignación del objeto \((1)\) a los grupos previos difiere entre métodos. Esto se debe a que:
- Single linkage prioriza la cercanía mínima entre pares de objetos.
- Complete linkage prioriza la máxima distancia entre elementos al agrupar.
Por ello, complete linkage tiende a formar clusters más compactos y homogéneos.
Realicemos el ejemplo en R.

Figure 5.2: Cluster con el método complete.
5.2.3 Clustering aglomerativo de la liga promedio
El método de average linkage (enlace promedio) define la distancia entre dos clusters como el promedio de las distancias entre todos los pares de objetos donde un miembro del par pertenece a cada cluster.
Supongamos que tenemos un cluster \((UV)\) y otro cluster \(W\). La distancia entre ellos se define como
\[ d_{(UV)W} = \frac{\displaystyle\sum_{i \in (UV)} \sum_{k \in W} d_{ik}} {N_{(UV)}\,N_W}, \]
donde \(d_{ik}\) es la distancia entre el objeto \(i\) del cluster \((UV)\) y el objeto \(k\) del cluster \(W\), mientras que \(N_{(UV)}\) y \(N_W\) son las cardinalidades de los clusters \((UV)\) y \(W\), respectivamente.
El algoritmo aglomerativo procede igual que antes:
Cada objeto es inicialmente un cluster.
Se busca el par de clusters con menor distancia.
Se fusionan esos clusters y se actualiza la matriz de distancias usando la fórmula de promedio anterior.
Se repiten los pasos 2 y 3 hasta que todos los objetos formen un solo cluster.
El clúster resultante del dendrograma tiene un aspecto intermedio entre una agrupación de enlace simple y una completa.
Ejemplo 3: Consideremos la matriz de los ejemplos anteriores.
\[ D = (d_{ik}) = \begin{pmatrix} 0 & 9 & 3 & 6 & 11 \\ 9 & 0 & 7 & 5 & 10 \\ 3 & 7 & 0 & 9 & 2 \\ 6 & 5 & 9 & 0 & 8 \\ 11 & 10 & 2 & 8 & 0 \end{pmatrix}. \]
Buscamos la distancia mínima (fuera de la diagonal). La menor entrada es
\[ \min_{i,k} d_{ik} = d_{35} = 2. \]
Por tanto, fusionamos los objetos \(3\) y \(5\) para formar el cluster \((35)\).
Calculamos ahora las distancias entre el cluster \((35)\) y los objetos restantes \(1,2,4\). Como cada uno de éstos es un cluster de tamaño \(1\), tenemos:
\[ d_{(35),1} = \frac{d_{31} + d_{51}}{2} = \frac{3 + 11}{2} = 7, \]
\[ d_{(35),2} = \frac{d_{32} + d_{52}}{2} = \frac{7 + 10}{2} = \frac{17}{2} = 8.5, \]
\[ d_{(35),4} = \frac{d_{34} + d_{54}}{2} = \frac{9 + 8}{2} = \frac{17}{2} = 8.5. \]
La nueva matriz de distancias (con clusters \((35)\), \(1\), \(2\), \(4\)) es
\[ \begin{array}{c|cccc} N & (35) & 1 & 2 & 4 \\\hline (35) & 0 & 7 & 8.5 & 8.5 \\ 1 & 7 & 0 & 9 & 6 \\ 2 & 8.5 & 9 & 0 & 5 \\ 4 & 8.5 & 6 & 5 & 0 \end{array} \]
La mínima distancia ahora es
\[ d_{24} = 5, \]
así que fusionamos los objetos \(2\) y \(4\) para obtener el cluster \((24)\).
Calculamos las distancias entre \((24)\) y los demás clusters \((35)\) y \(1\). Recordando que \(N_{(24)} = 2\), \(N_{(35)} = 2\) y \(N_1 = 1\):
\[ d_{(24),1} = \frac{d_{21} + d_{41}}{2} = \frac{9 + 6}{2} = \frac{15}{2} = 7.5, \]
\[ d_{(24),(35)} = \frac{1}{2\cdot 2} \left( d_{23} + d_{25} + d_{43} + d_{45} \right) = \frac{7 + 10 + 9 + 8}{4} = \frac{34}{4} = 8.5. \]
Ya habíamos calculado \(d_{(35),1} = 7\) en la etapa anterior. La matriz de distancias para los clusters \((35)\), \((24)\) y \(1\) es
\[ \begin{array}{c|ccc} N & (35) & (24) & 1 \\ \hline (35) & 0 & 8.5 & 7 \\ (24) & 8.5 & 0 & 7.5 \\ 1 & 7 & 7.5 & 0 \end{array} \]
La menor distancia es
\[ d_{(35),1} = 7, \]
por lo que se fusionan el objeto \(1\) con el cluster \((35)\), obteniendo el cluster \((135)\), de tamaño \(N_{(135)}=3\).
Ahora sólo quedan dos clusters: \((135)\) y \((24)\). Calculamos su distancia:
\[ d_{(135),(24)} = \frac{1}{3\cdot 2} \sum_{i \in \{1,3,5\}} \sum_{k \in \{2,4\}} d_{ik}. \]
Las distancias relevantes son
\[ d_{12}=9,\quad d_{14}=6,\quad d_{32}=7,\quad d_{34}=9,\quad d_{52}=10,\quad d_{54}=8. \]
Por lo tanto,
\[ \sum d_{ik} = 9 + 6 + 7 + 9 + 10 + 8 = 49, \]
y
\[ d_{(135),(24)} = \frac{49}{6} \approx 8.17. \]
Al ser el único par de clusters restante, \((135)\) y \((24)\) se fusionan en el nivel de distancia \(49/6\), produciendo el cluster final \((12345)\).
El dendrograma resultante muestra fusiones sucesivas a los niveles de distancia \[ 2,\quad 5,\quad 7,\quad \frac{49}{6}\approx 8.17, \] correspondientes, respectivamente, a las fusiones \[ (3,5),\quad (2,4),\quad (1,(35)),\quad ((135),(24)). \]
Este ejemplo ilustra cómo el criterio de average linkage utiliza el promedio de todas las distancias entre pares de objetos de dos clusters, lo cual suele producir grupos con un compromiso entre la compacidad de complete linkage y la tendencia a cadenas de single linkage.
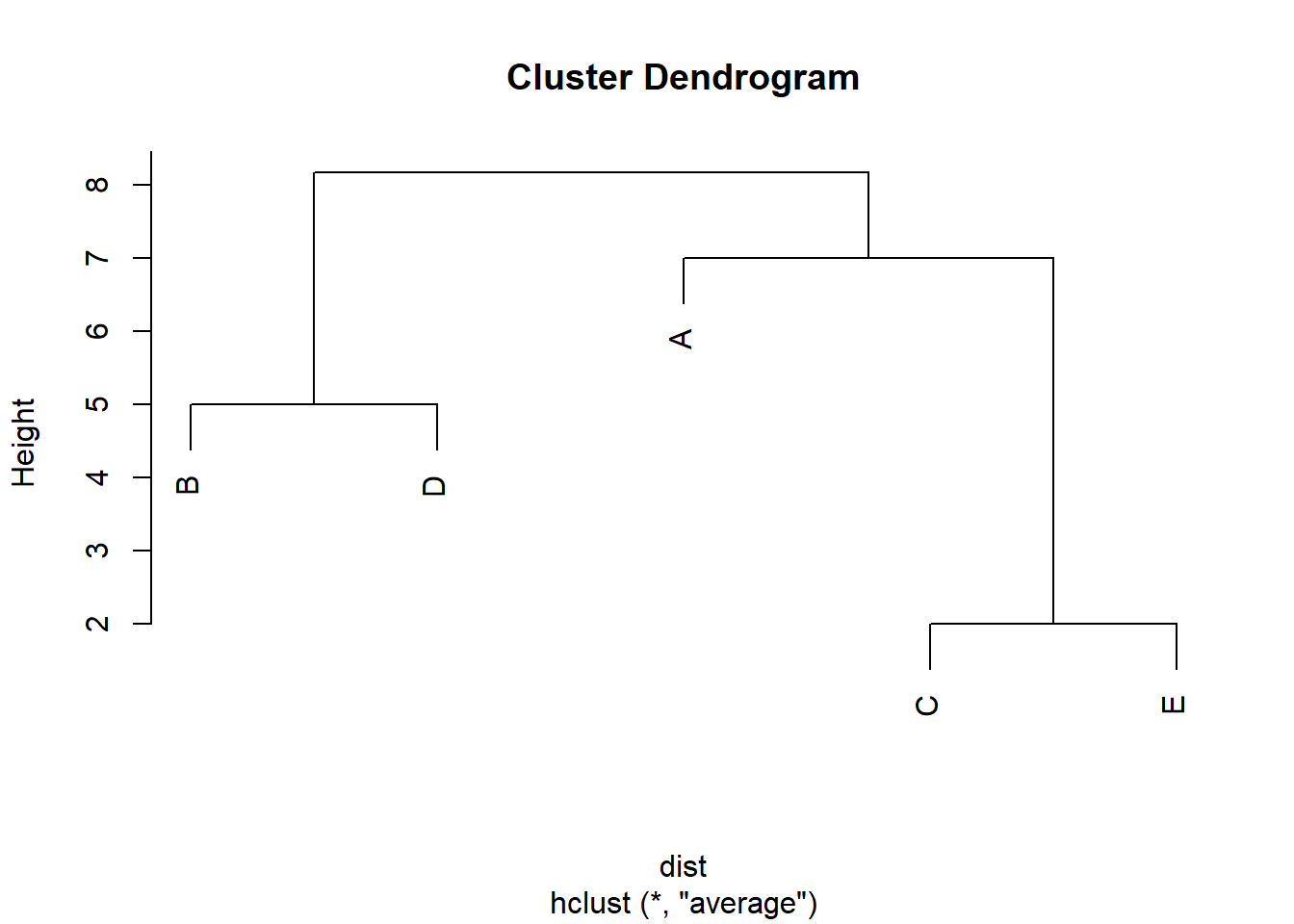
Figure 5.3: Cluster con el método average.
5.2.4 Agrupación de varianza mínima de Ward
El método jerárquico propuesto por Ward (1963) se basa en minimizar la pérdida de información que ocurre cuando se fusionan dos clusters. Dicha pérdida de información se mide normalmente como el aumento en la suma de cuadrados del error (Error Sum of Squares, ESS). Este método sea conceptualmente análogo a un análisis de la varianza.
Sea \(k\) un cluster cualquiera, y definamos
\[ ESS_k = \sum_{x_j \in k} (x_j - \bar{x}_k)'(x_j - \bar{x}_k), \]
es decir, la suma de las desviaciones cuadráticas de los elementos del cluster con respecto a su centroide \(\bar{x}_k\).
Si actualmente existen \(K\) clusters, definimos
\[ ESS = ESS_1 + ESS_2 + \cdots + ESS_K. \]
En cada etapa del algoritmo jerárquico se considera la posible unión de todos los pares de clusters, evaluando el incremento que dicha unión produciría en el valor total de \(ESS\). El par de clusters que se fusiona es aquel cuya unión genera el menor incremento en \(ESS\). De esta forma se garantiza que cada fusión produzca la mínima pérdida de información posible.
Valores extremos del algoritmo:
- Inicialmente, cada objeto es un cluster de tamaño uno, por lo que \(ESS_k = 0\) para todos los clusters.
- En el otro extremo, cuando todos los objetos se encuentran en un único cluster, el valor final es \[ ESS = \sum_{j=1}^N (x_j - \bar{x})'(x_j - \bar{x}), \] donde \(\bar{x}\) es el vector promedio de todos los elementos.
Interpretación geométrica: El método de Ward está fundamentado en la idea de que los clusters resultantes deben ser aproximadamente de forma elíptica y compacta, pues la suma de cuadrados mide dispersiones alrededor de centros promedios. Por esta razón, Ward:
- tiende a producir grupos balanceados en tamaño;
- evita formar cadenas largas de puntos (como ocurre con single linkage);
- penaliza la incorporación de puntos alejados del centro del cluster.
Representación gráfica: Los resultados de Ward pueden visualizarse mediante un dendrograma. El eje vertical actúa como escala del incremento en \(ESS\) asociado a cada fusión. Las alturas de los nodos indican el costo de unión de los clusters.
En resumen, el método de Ward es una versión jerárquica de técnicas de partición que buscan optimizar compactación dentro de los grupos. Es precursor directo de métodos no jerárquicos, tales como k-means, que minimizan variaciones internas utilizando centros promedio como referencia.
Este enfoque es particularmente adecuado para variables cuantitativas, ya que opera a partir de medidas basadas en medias y varianzas. Por ello, el método de Ward no resulta tan natural cuando las variables son binarias o categóricas sin transformar. Además, en su formulación clásica, la distancia inicial entre objetos corresponde a la distancia euclidiana al cuadrado, pues bajo dicha métrica la variación intra–grupo coincide estrictamente con la suma de cuadrados dentro del cluster.
Al final del proceso jerárquico, el dendrograma generado tiene como eje vertical los incrementos sucesivos en \(ESS\), ilustrando el costo de cada fusión. Debido a su criterio de minimización de varianza, Ward tiende a producir clusters más compactos y equilibrados que los derivados de criterios basados en distancias mínimas (single linkage) o máximas (complete linkage).

Figure 5.4: Cluster con el método Ward.
Comparando los cuatro métodos:
# Correrlo en consola para visualizarlo mejor
par (mfrow = c(2,2))
plot(cluster_single)
plot(cluster_complete)
plot(cluster_average)
plot(cluster_ward)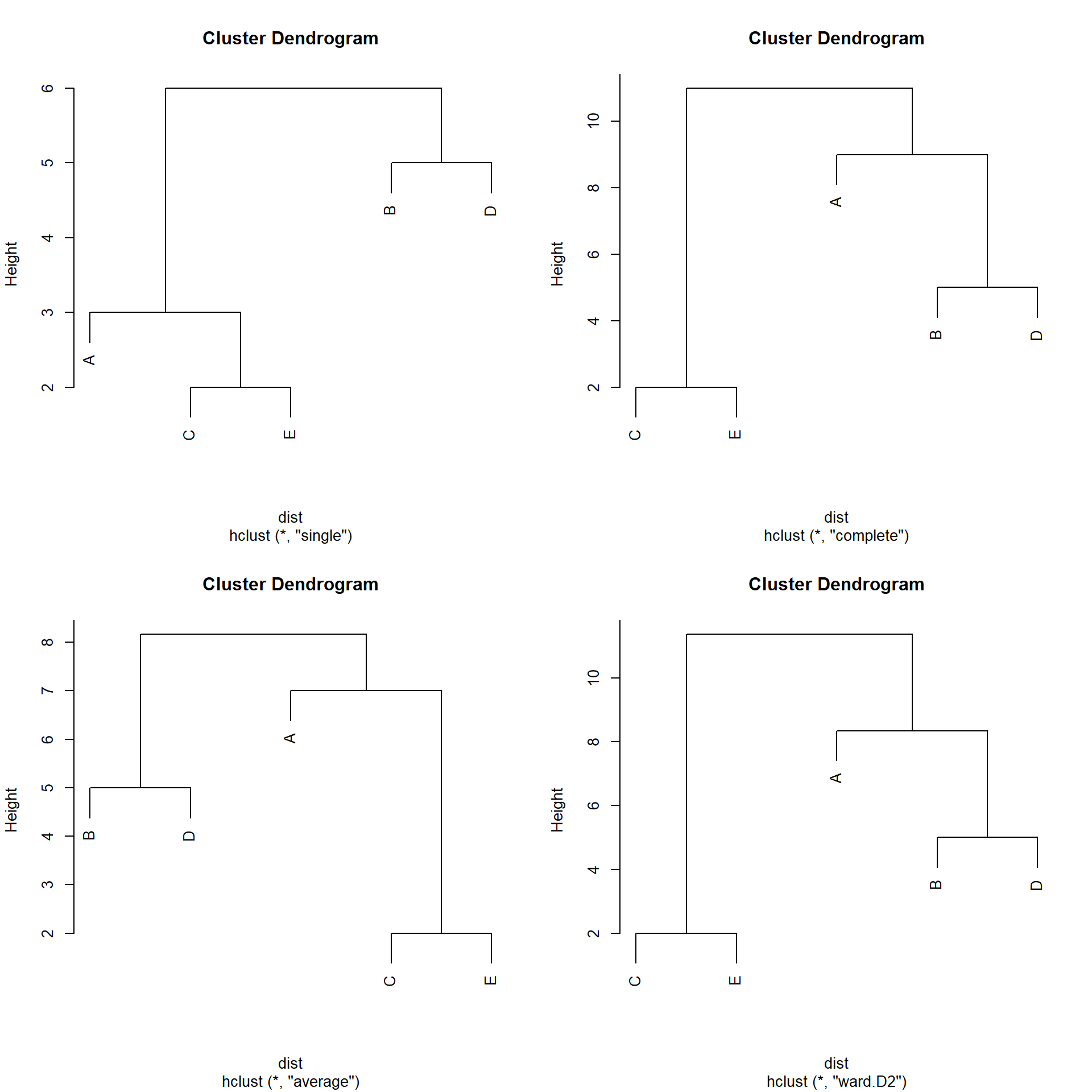
Figure 5.5: Comparación de los clusters con los 4 métodos.
¿Qué puedes decir al respecto si comparas el desempeño de estos 4 métodos?
5.2.5 Mismos gráficos usando el paquete factoextra
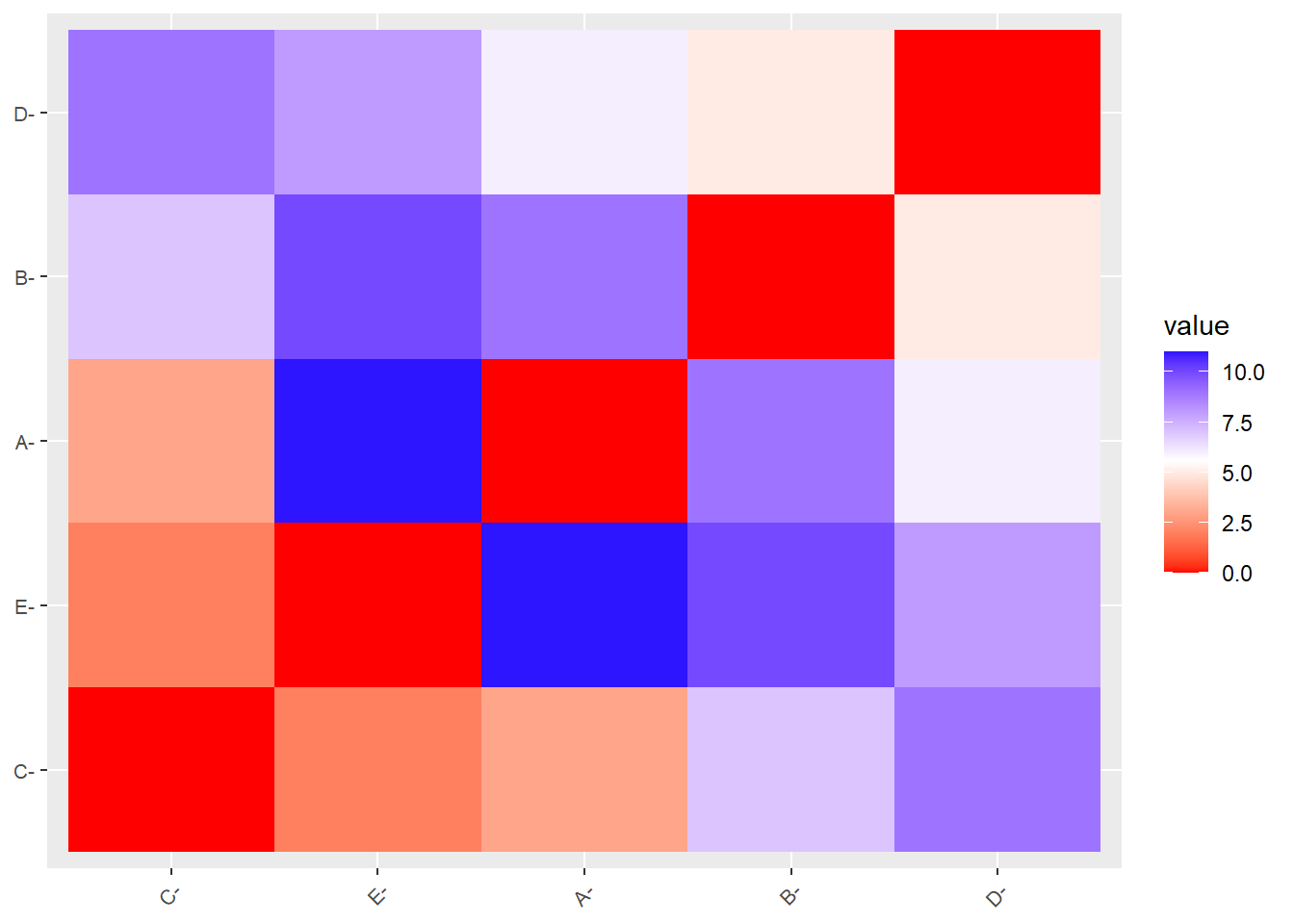
Figure 5.6: Heatmap de la matriz de distancias
set.seed(12345)
hc_single <- hclust(d=dist, method = "single")
hc_average <- hclust(d=dist, method = "average")
hc_complete <- hclust(d=dist, method = "complete")
hc_ward <- hclust(d=dist, method = "ward.D2")
## Otros dos métodos
hc_median <- hclust(d=dist, method = "median")
hc_centroid <- hclust(d=dist, method = "centroid")fviz_dend(x = hc_single, k=3,
cex = 0.7,
main = "",
xlab = "Samples",
ylab = "Distance",
sub = "",
horiz = TRUE)+
geom_hline(yintercept = 2.5, linetype = "dashed")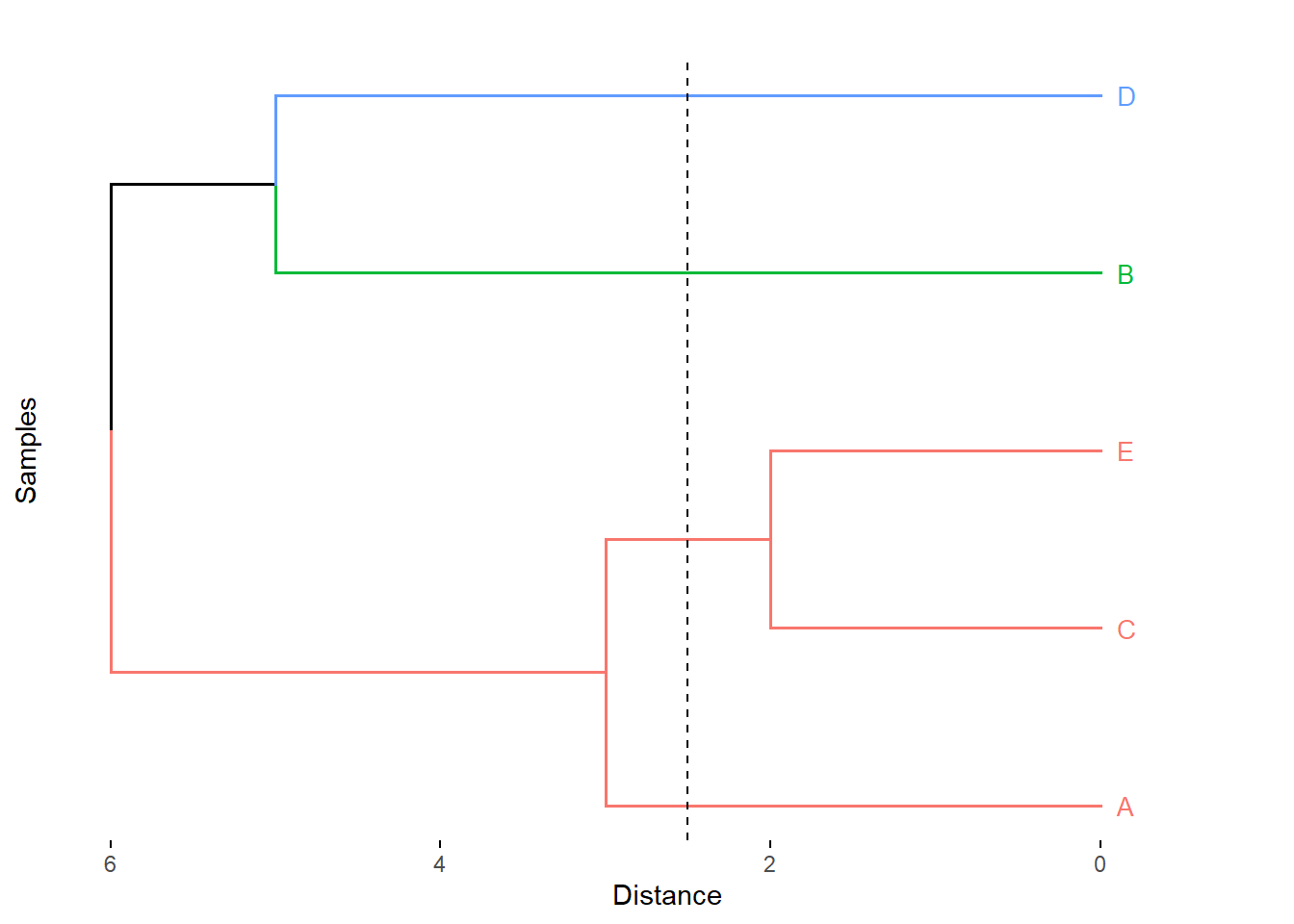
Figure 5.7: Cluster con el método de la liga más sencilla.
fviz_dend(x = hc_complete, k=3,
cex = 0.7,
main = "",
xlab = "Samples",
ylab = "Distance",
sub = "",horiz = TRUE)+
geom_hline(yintercept = 6, linetype = "dashed")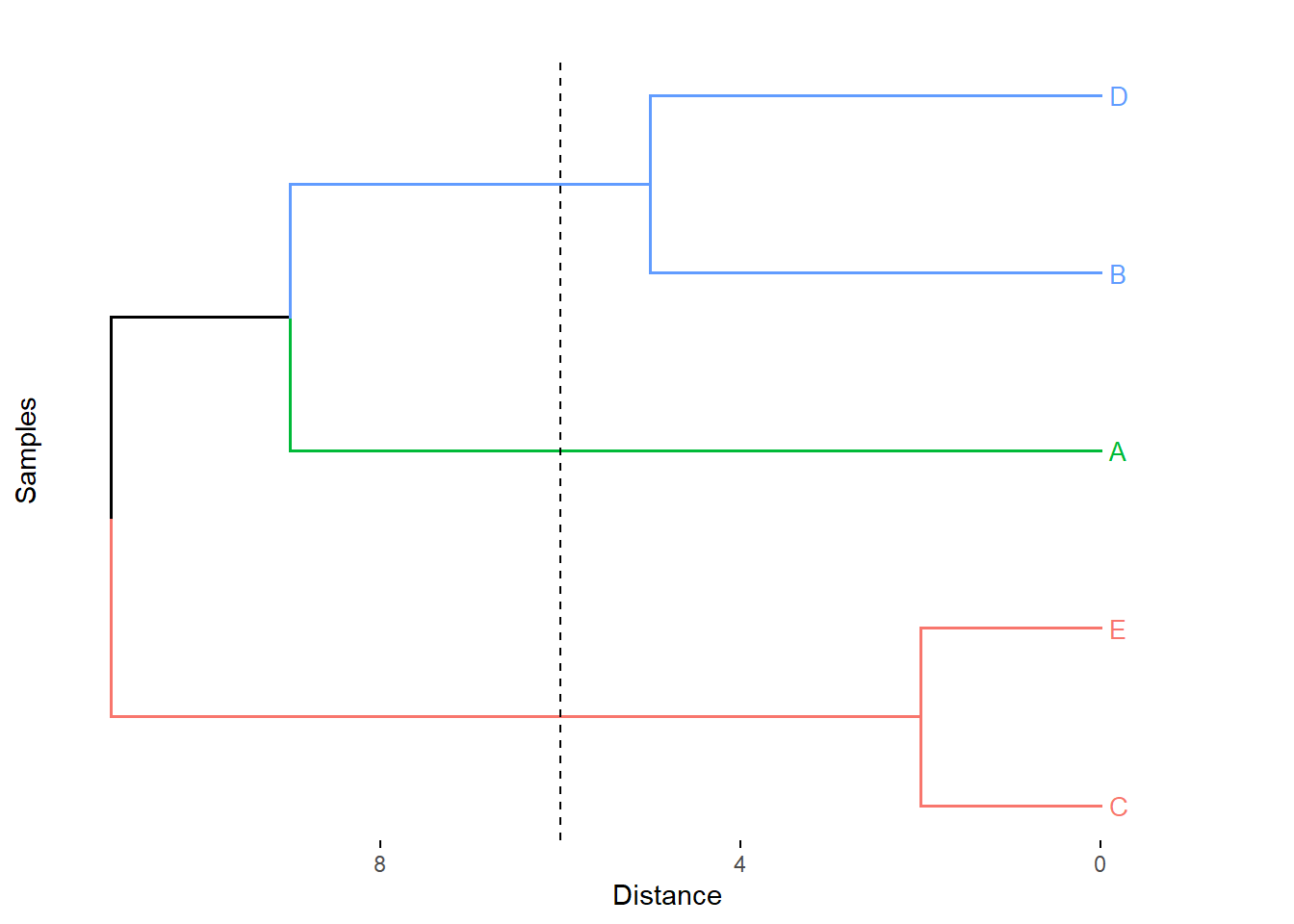
Figure 5.8: Cluster con el método de la liga completa.
fviz_dend(x = hc_average, k=3,
cex = 0.7,
main = "",
xlab = "Samples",
ylab = "Distance",
sub = "",
horiz = TRUE) +
geom_hline(yintercept = 4, linetype = "dashed") 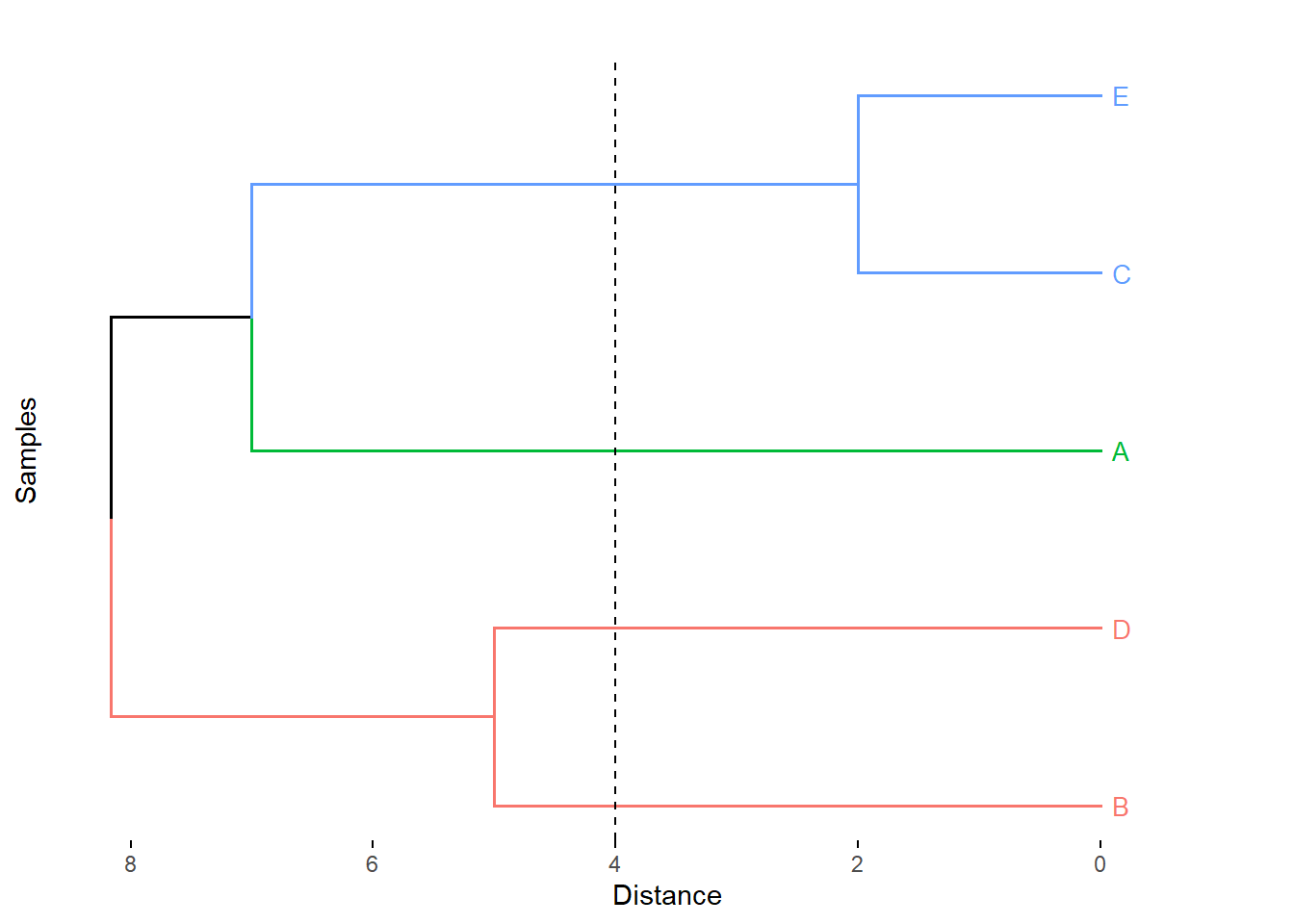
Figure 5.9: Cluster con el método del promedio.
fviz_dend(x = hc_ward, k=3,
cex = 0.7,
main = "",
xlab = "Samples",
ylab = "Distance",
sub = "",
horiz = TRUE)+
geom_hline(yintercept = 6, linetype = "dashed")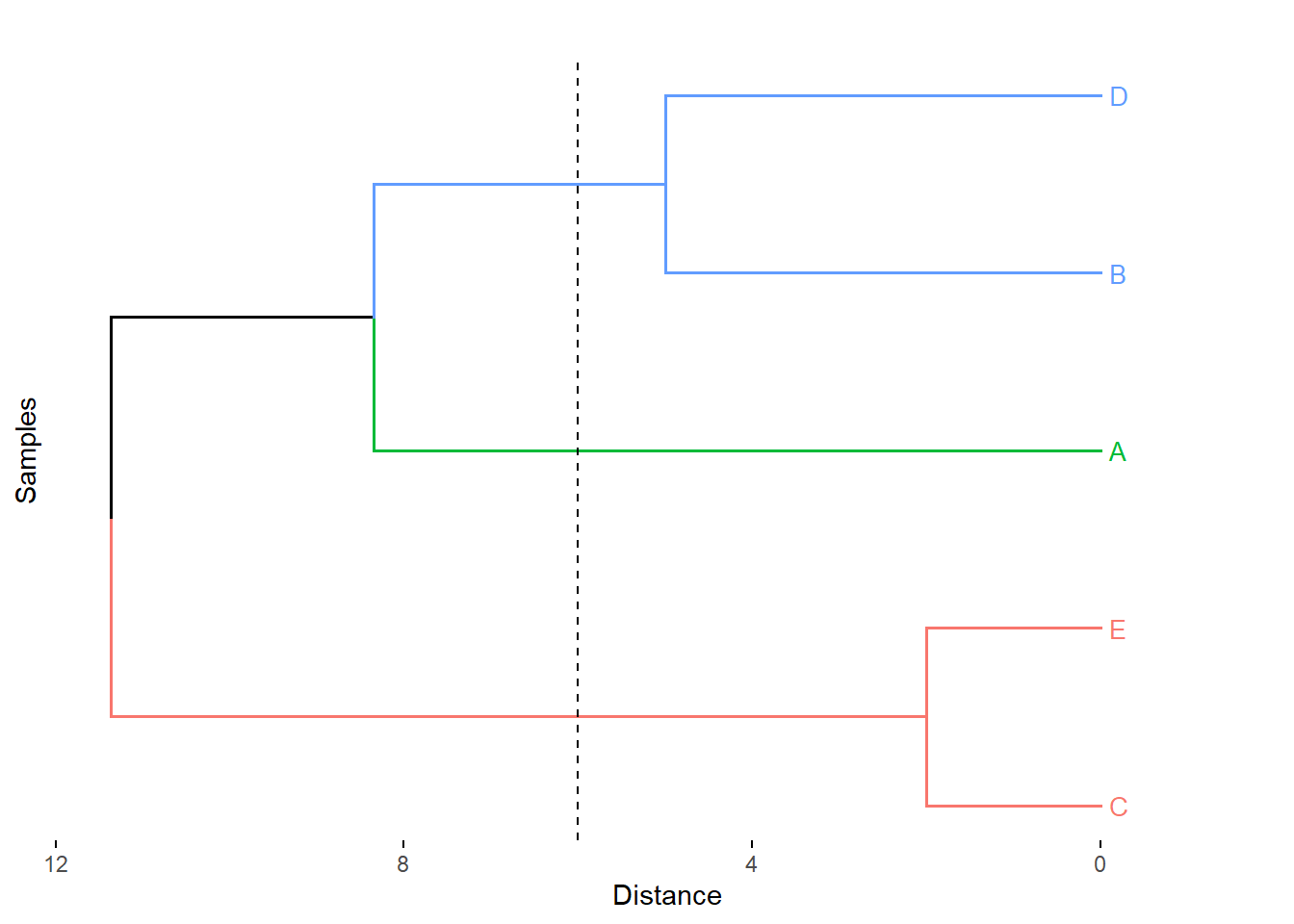
Figure 5.10: Cluster con el método Ward.
fviz_dend(x = hc_median, k=3,
cex = 0.7,
main = "",
xlab = "Samples",
ylab = "Distance",
sub = "",
horiz = TRUE)+
geom_hline(yintercept = 5, linetype = "dashed")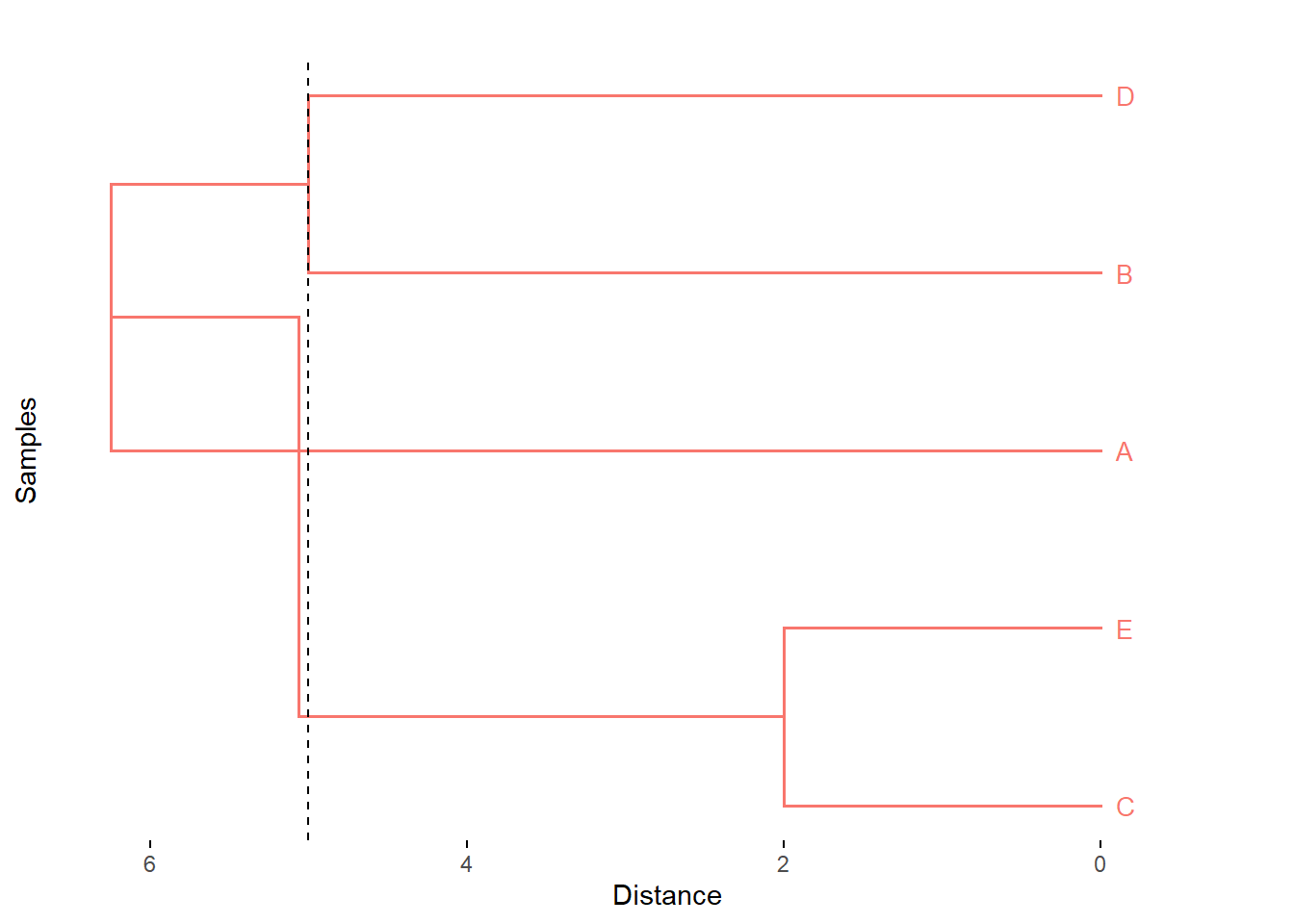
Figure 5.11: Cluster con el método mediana.
fviz_dend(x = hc_centroid, k=3,
cex = 0.7,
main = "",
xlab = "Samples",
ylab = "Distance",
sub = "",
horiz = TRUE)+
geom_hline(yintercept = 4.7, linetype = "dashed")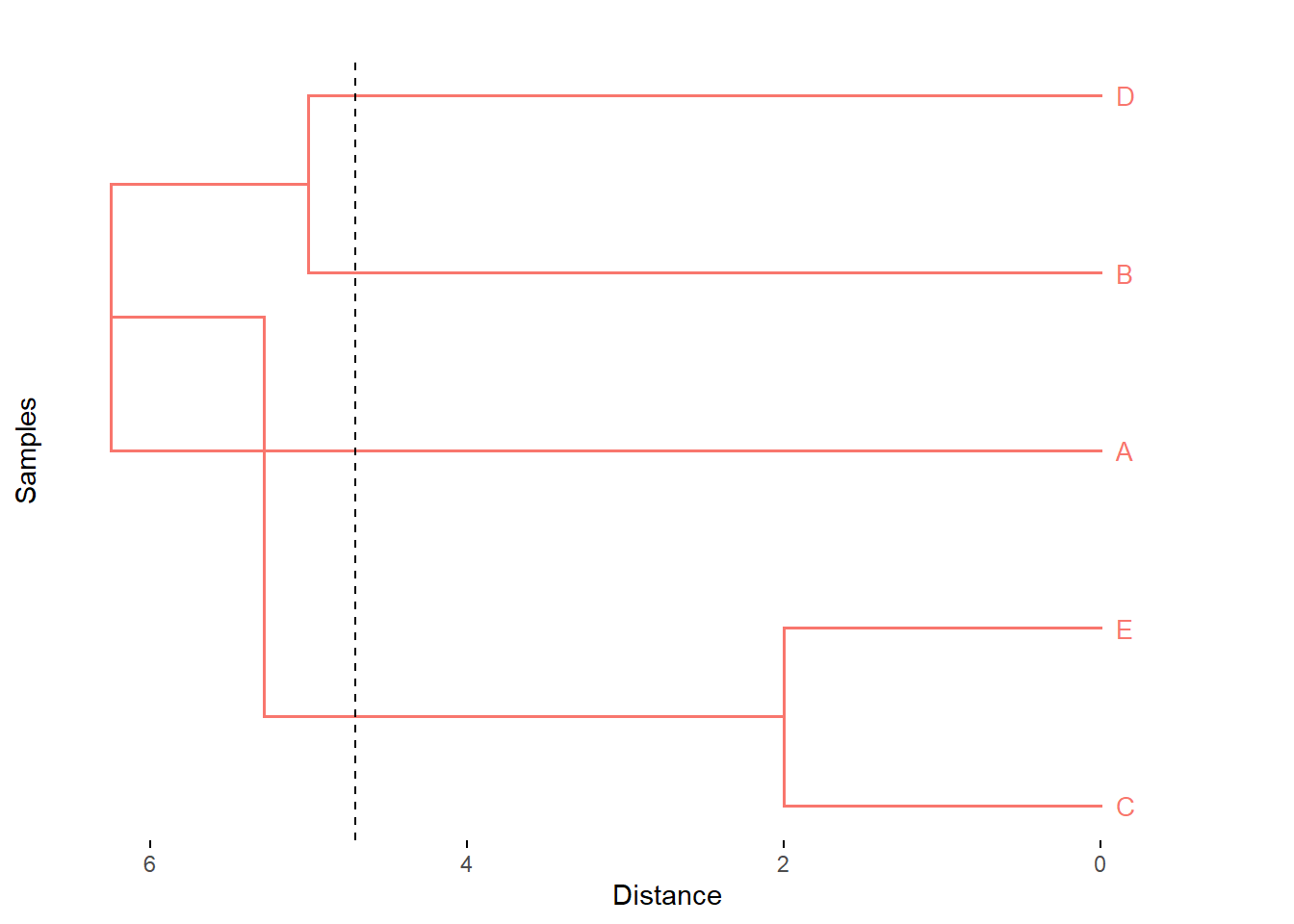
Figure 5.12: Cluster con el método del centroide.
Comentarios finales sobre los procedimientos jerárquicos
Además de los métodos basados en enlace simple, completo o promedio, existen muchas otras variantes de clustering jerárquico aglomerativo; sin embargo, todas siguen esencialmente el algoritmo general descrito anteriormente: partir de \(N\) grupos individuales y fusionar iterativamente los más similares.
Al igual que en otros procedimientos de clustering, los métodos jerárquicos pueden verse afectados por errores en los datos o por variabilidad no controlada. Esto implica que el resultado puede ser sensible a la presencia de valores atípicos o puntos ruidosos.
Una característica importante del clustering jerárquico es que no existe un mecanismo explícito de reubicación de elementos una vez que se han fusionado. Si un objeto se incorpora erróneamente a un cluster en una etapa temprana, dicho error persistirá hasta el final del proceso. Por esta razón, la interpretación del dendrograma debe realizarse cuidadosamente, evaluando si la estructura de grupos es razonable.
En la práctica, es recomendable aplicar diferentes métodos de clustering o utilizar distintos criterios de distancia dentro del mismo método. Si los resultados obtenidos son consistentemente similares, se puede argumentar con mayor confianza la presencia de grupos “naturales”.
La estabilidad de una solución jerárquica puede evaluarse mediante pequeñas perturbaciones a los datos (por ejemplo, añadiendo ruido controlado o repitiendo mediciones). Si los grupos son bien definidos, el dendrograma resultante debe permanecer similar después de la perturbación.
Finalmente, es posible que existan empates en valores de distancia entre pares de clusters, lo cual puede conducir a soluciones múltiples válidas. En estos casos, diferentes dendrogramas pueden representar distintas decisiones de fusión en niveles inferiores del árbol. Esto no necesariamente indica un problema metodológico, sino que refleja ambigüedad legítima en la estructura de similitudes del conjunto de datos. El usuario debe estar consciente de ello para interpretar adecuadamente las posibles estructuras de agrupamiento.
5.2.6 Número óptimo de clústers
Para seleccionar la partición más adecuada de los datos, primero comparamos distintos métodos de agrupamiento jerárquico a partir de la calidad del dendrograma que generan. Dicha calidad se evaluó calculando el coeficiente de correlación cofenético entre la matriz de distancias original y las distancias cofenéticas derivadas del dendrograma correspondiente (véase Cuadro 5.1). Valores cercanos a 1 indican que la estructura jerárquica preserva adecuadamente las relaciones de proximidad originales entre las observaciones, por lo que el dendrograma constituye una buena representación de los datos.
Una vez seleccionado el dendrograma que mejor reproduce la estructura de distancias, el número óptimo de clústers se determinó mediante la inspección del dendrograma y la identificación de incrementos marcados en los niveles de fusión, los cuales sugieren separaciones naturales entre grupos. Adicionalmente, se evaluaron distintas particiones mediante criterios de validación interna, tales como el coeficiente de silhouette promedio, con el fin de corroborar la estabilidad y coherencia de la estructura obtenida.
Con este procedimiento combinado (fidelidad del dendrograma y evaluación de cohesión/separación) se seleccionó el número final de clústers a reportar.
##
## Adjuntando el paquete: 'kableExtra'## The following object is masked from 'package:dplyr':
##
## group_rows# vector con nombre de los métodos
m <- c( "average", "single", "complete", "ward.D2", "median", "centroid")
names(m) <- c( "average", "single", "complete", "ward.D2", "median", "centroid")
# Función para calcular el coeficiente de correlación
coef_cor <- function(x) {
cor(x=dist, cophenetic(hclust(d=dist, method = x)))
}
# Tabla comparativa
coef_tabla <- map_dbl(m, coef_cor)
kbl(coef_tabla, booktabs = TRUE, align = "c",
caption = "Cuadro comparativo de los coeficientes de correlación",
col.names = rownames(coef_tabla)) %>%
kable_styling(position = "center",
latex_options = c("repeat_header", "hold_position"),
font_size = 9) %>%
add_header_above(c("Método", "Coeficiente de correlación"))| average | 0.6816035 |
| single | 0.5139962 |
| complete | 0.6521790 |
| ward.D2 | 0.6349740 |
| median | 0.5333157 |
| centroid | 0.5676691 |
A partir de los coeficientes de correlación cofenética (Cuadro 5.1), observamos que el dendrograma obtenido mediante el método average es el que mejor preserva la estructura de similitudes original entre las observaciones, seguido por el método median. Por este motivo, utilizamos el dendrograma generado con average como base para determinar la partición final.
Posteriormente, para determinar el número adecuado de clústers, utilizamos dos enfoques complementarios: el método del codo aplicado a la variación explicada y el paquete NbClust. Este último permite evaluar de manera simultánea un conjunto amplio de índices de validación (por ejemplo, Calinski–Harabasz, Dunn, Silhouette, entre otros), con el fin de sugerir el número de clústers más adecuado dentro de un rango especificado. Con base en la concordancia entre ambos enfoques, seleccionamos el número final de grupos a analizar.
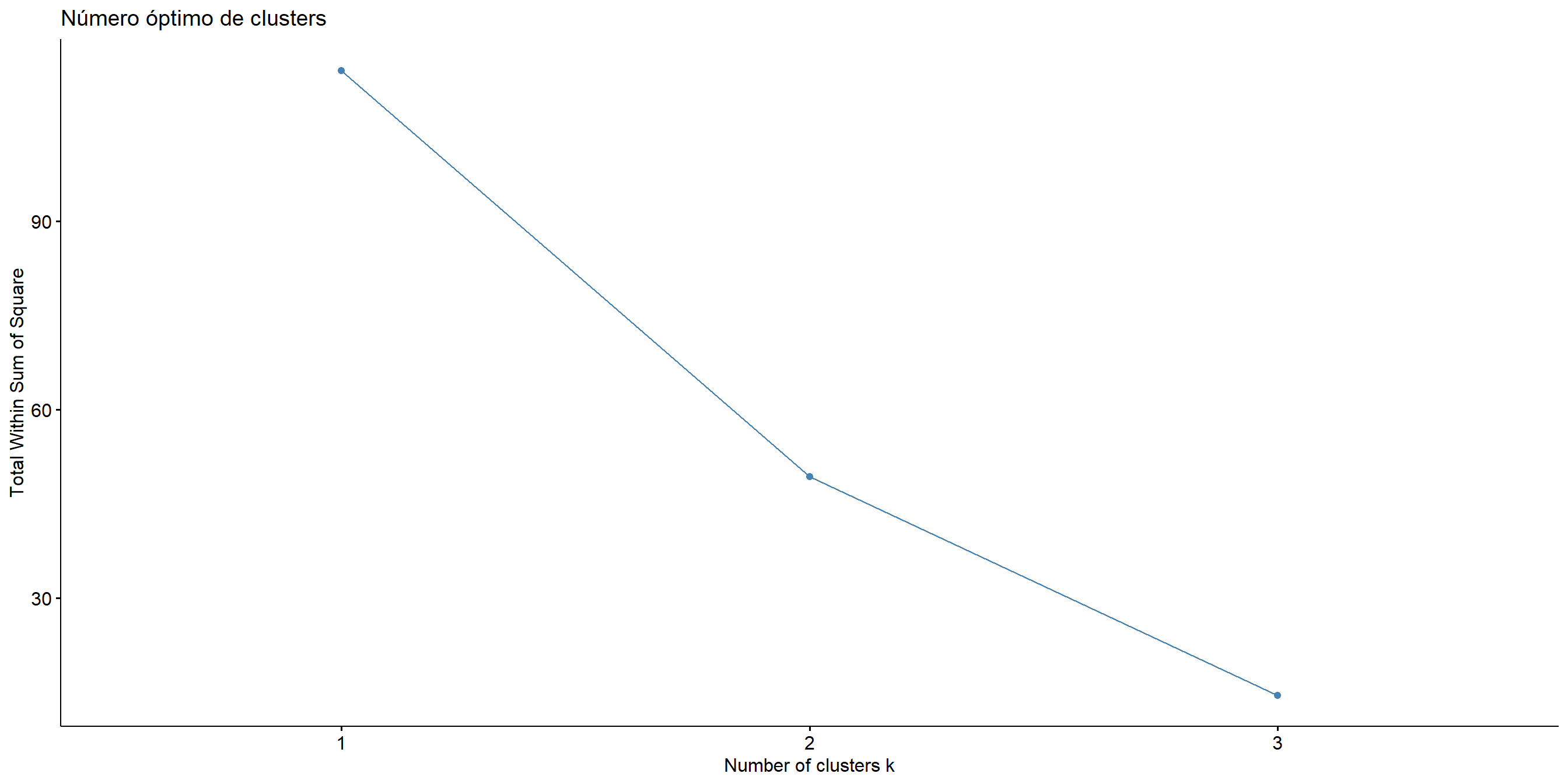
Figure 5.13: Número óbtimo de clusters usando el método del codo
Podemos observar en la gráfica de codo que en 2 es donde se forma el codo, así que esto nos diría que debemos considerar 2 clústers.
Usando el paquete ‘NbClust’ se pueden obtener una comparación del número óptimo de clústers. Para el ejemplo que hemos estado realizando, no es posible aplicarle esto, pero lo que deberíamos de realizar es lo siguiente.
5.3 Ejercicios
Ejercicio 1 (Ejemplo 12.2, Johnsonn y Wichern): Ssimilitud entre 11 lenguas.
El significado de las palabras cambia a lo largo de la historia; sin embargo, el significado de los números \(1,2,3,\dots\) se mantiene notablemente estable. Esto permite comparar lenguas utilizando únicamente las palabras para los numerales.
En la tabla siguiente se muestran las palabras que representan los números del 1 al 10 en once lenguas europeas modernas: inglés, noruego, danés, neerlandés, alemán, francés, español, italiano, polaco, húngaro y finés.
(Únicamente se consideran lenguas que usan el alfabeto romano; se omiten acentos, diéresis, cedillas, etc.)
Una inspección rápida de la tabla sugiere que las primeras cinco lenguas (inglés, noruego, danés, neerlandés y alemán) son muy parecidas entre sí.
Las lenguas francesa, española e italiana parecen guardar una similitud aún mayor entre ellas. Húngaro y finés parecen más aisladas, y el polaco comparte características con las lenguas de ambos subgrupos mayores.
library(knitr)
tabla1 <- data.frame(
Ingles = c("one","two","three","four","five","six","seven","eight","nine","ten"),
Noruego = c("en","to","tre","fire","fem","seks","sju","atte","ni","ti"),
Danes = c("en","to","tre","fire","fem","seks","syv","otte","ni","ti"),
Neerlandes = c("een","twee","drie","vier","vijf","zes","zeven","acht","negen","tien"),
Aleman = c("eins","zwei","drei","vier","funf","sechs","sieben","acht","neun","zehn"),
Frances = c("un","deux","trois","quatre","cinq","six","sept","huit","neuf","dix"),
Espanol = c("uno","dos","tres","cuatro","cinco","seis","siete","ocho","nueve","diez"),
Italiano = c("uno","due","tre","quattro","cinque","sei","sette","otto","nove","dieci"),
Polaco = c("jeden","dwa","trzy","cztery","piec","szesc","siedem","osiem","dziewiec","dziesiec"),
Hungaro = c("egy","ketto","harom","negy","ot","hat","het","nyolc","kilenc","tiz"),
Fines = c("yksi","kaksi","kolme","neljä","viisi","kuusi","seitsemän","kahdeksan","yhdeksän","kymmenen")
)
kable(tabla1, caption = "Numerales del 1 al 10 en 11 lenguas europeas")| Ingles | Noruego | Danes | Neerlandes | Aleman | Frances | Espanol | Italiano | Polaco | Hungaro | Fines |
|---|---|---|---|---|---|---|---|---|---|---|
| one | en | en | een | eins | un | uno | uno | jeden | egy | yksi |
| two | to | to | twee | zwei | deux | dos | due | dwa | ketto | kaksi |
| three | tre | tre | drie | drei | trois | tres | tre | trzy | harom | kolme |
| four | fire | fire | vier | vier | quatre | cuatro | quattro | cztery | negy | neljä |
| five | fem | fem | vijf | funf | cinq | cinco | cinque | piec | ot | viisi |
| six | seks | seks | zes | sechs | six | seis | sei | szesc | hat | kuusi |
| seven | sju | syv | zeven | sieben | sept | siete | sette | siedem | het | seitsemän |
| eight | atte | otte | acht | acht | huit | ocho | otto | osiem | nyolc | kahdeksan |
| nine | ni | ni | negen | neun | neuf | nueve | nove | dziewiec | kilenc | yhdeksän |
| ten | ti | ti | tien | zehn | dix | diez | dieci | dziesiec | tiz | kymmenen |
Para cuantificar la similitud entre dos lenguas podemos fijarnos únicamente en la primera letra de cada palabra. Diremos que dos palabras para el mismo número en dos lenguas distintas son concordantes si tienen la misma letra inicial y discordantes en caso contrario.
A partir de la Tabla anterior podemos construir una tabla de concordancias entre lenguas: para cada par de lenguas contamos cuántas veces (sobre los 10 numerales) coinciden las letras iniciales de sus palabras. El resultado se resume en la Tabla siguiente. Por ejemplo, el valor 8 en la celda \((\text{E},\text{N})\) indica que inglés y noruego comparten la misma letra inicial en 8 de los 10 numerales.
tabla2 <- data.frame(
row.names = c("E","N","Da","Du","G","Fr","Sp","I","P","H","Fi"),
E = c(10,8,8,3,4,4,4,4,3,1,1),
N = c(8,10,9,5,6,4,4,4,3,2,1),
Da = c(8,9,10,4,5,4,5,5,4,2,1),
Du = c(3,5,4,10,5,1,1,1,0,2,1),
G = c(4,6,5,5,10,3,3,3,2,1,1),
Fr = c(4,4,4,1,3,10,8,9,5,0,1),
Sp = c(4,4,5,1,3,8,10,9,7,0,1),
I = c(4,4,5,1,3,9,9,10,6,0,1),
P = c(3,3,4,0,2,5,7,6,10,0,2),
H = c(1,2,2,2,1,0,0,0,0,10,1),
Fi = c(1,1,1,1,1,1,1,1,2,1,10)
)
kable(tabla2, caption = "Concordancias entre primeras letras de los numerales (1--10)")| E | N | Da | Du | G | Fr | Sp | I | P | H | Fi | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| E | 10 | 8 | 8 | 3 | 4 | 4 | 4 | 4 | 3 | 1 | 1 |
| N | 8 | 10 | 9 | 5 | 6 | 4 | 4 | 4 | 3 | 2 | 1 |
| Da | 8 | 9 | 10 | 4 | 5 | 4 | 5 | 5 | 4 | 2 | 1 |
| Du | 3 | 5 | 4 | 10 | 5 | 1 | 1 | 1 | 0 | 2 | 1 |
| G | 4 | 6 | 5 | 5 | 10 | 3 | 3 | 3 | 2 | 1 | 1 |
| Fr | 4 | 4 | 4 | 1 | 3 | 10 | 8 | 9 | 5 | 0 | 1 |
| Sp | 4 | 4 | 5 | 1 | 3 | 8 | 10 | 9 | 7 | 0 | 1 |
| I | 4 | 4 | 5 | 1 | 3 | 9 | 9 | 10 | 6 | 0 | 1 |
| P | 3 | 3 | 4 | 0 | 2 | 5 | 7 | 6 | 10 | 0 | 2 |
| H | 1 | 2 | 2 | 2 | 1 | 0 | 0 | 0 | 0 | 10 | 1 |
| Fi | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 10 |
Los resultados de la Tabla anterior confirman la impresión visual de la primer tabla: inglés, noruego, danés, neerlandés y alemán parecen formar un grupo; francés, español, italiano y polaco podrían agruparse juntos, mientras que húngaro y finés parecen más aislados.
A partir de la tabla de concordancias \(\big(c_{ij}\big)\) de la Tabla , construyan una matriz de disimilitudes definiendo, por ejemplo, \[ d_{ij} = 10 - c_{ij}, \] para \(i \neq j\), y \(d_{ii} = 0\). (Es decir, mientras mayor sea el número de diferencias en las letras iniciales, mayor será la disimilitud entre las lenguas \(i\) y \(j\).)
Apliquen métodos de clustering jerárquico aglomerativo utilizando al menos los siguientes criterios de enlace:
enlace simple,
enlace completo,
enlace promedio,
método de Ward.
- Para cada método de enlace:
Generen el dendrograma correspondiente a la matriz de disimilitudes \(D = (d_{ij})\).
Calcule el coeficiente de correlación cofenético entre la matriz de disimilitudes original y las distancias cofenéticas del dendrograma.
Comparen los dendrogramas obtenidos y los valores de correlación cofenética. ¿Qué método produce el dendrograma que mejor preserva la estructura de similitudes entre las lenguas?
Usando el dendrograma seleccionado en el punto anterior:
Exploren distintos cortes del árbol para obtener diferentes números de clústers (\(k=2,3,\dots\)).
Utilicen el método del codo (basado en la suma de cuadrados intra–grupo) y, si lo desean, índices adicionales de validación interna (por ejemplo, silhouette promedio) para determinar el número más adecuado de clústers.
- Finalmente, interpreten los clústers obtenidos:
¿Qué lenguas quedan agrupadas en cada clúster?
¿Coinciden los grupos encontrados con la impresión inicial basada en las dos tablas?
Ejercicio 2: Carga la base de datos USArrests. Obtén los dendrogramas y compara cuales realizan una mejor agrupación. ¿Cuál es el número óptimo de clusters?
#Código de la clase
library(tidyverse)
library(cluster)
library(factoextra)
library(ggplot2)
library(purrr)
library(NbClust)
# Cargar datos y analizar varianzas y correlaciones
data("USArrests")
any(is.na(USArrests))
summary(USArrests)
dim(USArrests)
var(data.matrix(USArrests))
cor.mat_all <- cor(data.matrix(USArrests), use="complete.obs")
cor.mat_all
# Escalar datos
US_df <- scale(USArrests)
var(US_df)
# Calcular distancias
dist <- dist(US_df, method = "euclidean")
head(dist)
# Realizar clusters
cluster_single <- hclust (d = dist, method = 'single')
plot(cluster_single,cex=0.7, hang = -2)
cluster_complete <- hclust (d = dist, method = 'complete')
plot(cluster_complete, cex=0.7, hang = -2)
cluster_average <- hclust (d = dist, method = 'average')
plot(cluster_average, cex=0.7, hang = -2)
cluster_ward <- hclust (d = dist, method = 'ward.D2')
plot(cluster_ward,cex=0.7, hang = -2)
par (mfrow = c(2,2))
plot(cluster_single,cex=0.7, hang = -2)
plot(cluster_complete,cex=0.7, hang = -2)
plot(cluster_average,cex=0.7, hang = -2)
plot(cluster_ward,cex=0.7, hang = -2)
par (mfrow = c(1,1))
# Comparar coeficiente de correlación de los métodos
# vector con nombre de los métodos
m <- c( "average", "single", "complete", "ward.D2", "median", "centroid")
names(m) <- c( "average", "single", "complete", "ward.D2", "median", "centroid")
# Función para calcular el coeficiente de correlación
coef_cor <- function(x) {
cor(x=dist, cophenetic(hclust(d=dist, method = x)))
}
# Tabla comparativa
coef_tabla <- map_dbl(m, coef_cor)
coef_tabla
# Calcular número óptimo de clusters
# Método del codo
fviz_nbclust(x = US_df, FUNcluster = hcut, method = "wss", diss = dist, k.max = 7) +
labs(title = "Número óptimo de clusters") +
xlab("Número de clústers")
# Aplicar todos los índices y métodos
res.nbclust <- NbClust(US_df, distance = "euclidean",
min.nc = 3, max.nc = 6,
method = "average", index ="all")
# Realizar plot con el número óptimo de cluster y marcar los grupos
plot(cluster_average, cex = 0.6, hang = -2)
rect.hclust(cluster_average, k = 4, border = 2:8)
#fviz_nbclust(res.nbclust) +
# theme_minimal() +
# ggtitle("Número óbtimo de clusters con NbClust")
# Con Factoextra
# Matriz de distancias
fviz_dist(dist.obj = dist, lab_size = 8)
# Clusters
set.seed(12345)
hc_single <- hclust(d=dist, method = "single")
hc_average <- hclust(d=dist, method = "average")
hc_complete <- hclust(d=dist, method = "complete")
hc_ward <- hclust(d=dist, method = "ward.D2")
hc_median <- hclust(d=dist, method = "median")
hc_centroid <- hclust(d=dist, method = "centroid")
fviz_dend(x = hc_complete, k=4,
cex = 0.7,
main = "Cluster método complete",
xlab = "Ciudades",
ylab = "Distancias",
type= "rectangle",
sub = "",
horiz = TRUE)+
geom_hline(yintercept = 3.8, linetype = "dashed")
sub_grp <- cutree(hc_complete, k = 4)
table(sub_grp)
fviz_cluster(list(data = US_df, cluster = sub_grp))
# Comparar dendrogramas
library(dendextend)
hc_single <- agnes(US_df, method = "single")
hc_complete <- agnes(US_df, method = "complete")
hc_single <- as.dendrogram(hc_single)
hc_complete <- as.dendrogram(hc_complete)
tanglegram(rank_branches(hc_single),rank_branches(hc_complete),
main_left = "Single",
main_right = "Complete", lab.cex= 0.7, margin_inner = 5, k_branches = 4)5.4 Clustering no jerárquico
Los métodos de clustering no jerárquicos están diseñados para agrupar observaciones (ítems), más que variables, en una colección de \(K\) clústers. El número de clústers \(K\) puede fijarse de antemano o bien determinarse como parte del procedimiento de agrupamiento.
A diferencia de los métodos jerárquicos, en los métodos no jerárquicos no es necesario trabajar explícitamente con una matriz completa de distancias (o similitudes), ni almacenarla durante todo el proceso de cómputo. Esto permite aplicar estos métodos a conjuntos de datos mucho más grandes que los que suelen manejarse con técnicas jerárquicas.
En general, los métodos no jerárquicos parten de:
una partición inicial de los ítems en grupos, o
un conjunto inicial de “puntos semilla”, que funcionarán como núcleos de los clústers.
Una buena elección de la configuración inicial es importante y, en la medida de lo posible, debe evitar sesgos evidentes. Una estrategia simple consiste en elegir aleatoriamente los puntos semilla entre las observaciones, o bien asignar aleatoriamente los ítems a grupos iniciales.
En esta sección consideramos uno de los procedimientos no jerárquicos más populares: el método de \(k\)-means.
5.4.1 K-means
MacQueen introdujo el término \(k\)-means para describir un algoritmo que asigna cada observación al clúster cuyo centroide (media) sea más cercano. En su versión más simple, el proceso consta de los siguientes pasos:
Partición inicial: Dividir las observaciones en \(K\) clústers iniciales (o bien elegir \(K\) centroides iniciales).
Asignación: Recorrer la lista de observaciones y asignar cada una al clúster cuyo centroide esté más cerca. La distancia suele ser la euclidiana, usando ya sea datos estandarizados o sin estandarizar.
Actualización: Recalcular el centroide de cada clúster a partir de las observaciones que contiene tras la nueva asignación.
Iteración: Repetir los pasos 2 y 3 hasta que no se produzcan reasignaciones (o los cambios sean despreciables).
En lugar de comenzar con una partición inicial de todos los ítems en \(K\) grupos (Paso 1), también es posible especificar directamente \(K\) centroides iniciales (puntos semilla) y empezar el algoritmo a partir del Paso 2.
La asignación final de las observaciones a los clústers depende, en cierta medida, de la partición o de los centroides iniciales elegidos. La experiencia indica que la mayoría de los cambios importantes en la asignación ocurren durante las primeras iteraciones, y posteriormente el algoritmo tiende a estabilizarse.
Ejemplo 1: Supongamos que medimos dos variables \(X_1\) y \(X_2\) para cuatro ítems: A, B, C y D. Los datos se muestran en la tabla siguiente:
| Ítem | x1 | x2 |
|---|---|---|
| A | 5 | 3 |
| B | -1 | 1 |
| C | 1 | -2 |
| D | -3 | -2 |
El objetivo consiste en dividir estos ítems en \(K = 2\) clústers, de modo que los elementos dentro de un clúster sean más similares entre sí que respecto a los elementos del otro clúster.
Para implementar el método \(k\)-means con \(K=2\), iniciamos con una partición arbitraria. Supongamos que asignamos inicialmente: \[ \text{Cluster 1: } (A,B), \qquad \text{Cluster 2: } (C,D). \]
Entonces, el paso 1 sería calcular los centroides iniciales. Después, la reasignación usando distancia euclidiana y el nuevo cálculo de centroides, hasta terminar el proceso.
Paso 1: Cálculo de centroides iniciales
Calculamos los centroides (promedios) de cada clúster.
Para el clúster \((A,B)\): \[ \bar{x}_1 = \frac{5 + (-1)}{2} = 2, \qquad \bar{x}_2 = \frac{3 + 1}{2} = 2 \] Por tanto, el centroide es: \[ m_{AB} = (2,\,2). \]
Para el clúster \((C,D)\): \[ \bar{x}_1 = \frac{1 + (-3)}{2} = -1, \qquad \bar{x}_2 = \frac{-2 + (-2)}{2} = -2 \] Por tanto, el centroide es: \[ m_{CD} = (-1,\,-2). \]
Paso 2: Reasignación usando distancia euclidiana
En el Paso 2, calculamos la distancia euclidiana de cada ítem al centroide de los grupos y reasignamos cada ítem al grupo más cercano. Si un ítem se mueve de la configuración inicial, los centroides deben actualizarse antes de continuar. La coordenada \(i\)-ésima del centroide, \(i = 1,2,\dots,p\), se actualiza fácilmente usando las siguientes fórmulas:
\[ \bar{x}_{i, \text{new}} = \frac{n \bar{x}_i + x_{ji}}{n + 1} \qquad \text{si el ítem } j \text{ es añadido a un grupo}, \]
\[ \bar{x}_{i, \text{new}} = \frac{n \bar{x}_i - x_{ji}}{n - 1} \qquad \text{si el ítem } j \text{ es removido de un grupo}. \]
Aquí \(n\) es el número de ítems en el “grupo antiguo”, cuyo centroide es \[ \bar{x}' = (\bar{x}_1, \bar{x}_2,\dots, \bar{x}_p). \]
Consideremos los clústers iniciales \((AB)\) y \((CD)\). Las coordenadas iniciales de los centroides eran \((2,2)\) y \((-1,-2)\) respectivamente. Supongamos que el ítem \(A=(5,3)\) se mueve al grupo \((CD)\). Los nuevos grupos son \((B)\) y \((ACD)\) con centroides actualizados.
Para el grupo \((B)\) se tiene:
\[ \bar{x}_{1,\text{new}} = \frac{2(2) - 5}{2 - 1} = -1, \qquad \bar{x}_{2,\text{new}} = \frac{2(2) - 3}{2 - 1} = 1. \]
Por lo tanto, las coordenadas del centroide de \((B)\) son: \[ (-1,\,1). \]
Para el grupo \((ACD)\) se obtiene:
\[ \bar{x}_{1,\text{new}} = \frac{2(-1) + 5}{2 + 1} = 1, \qquad \bar{x}_{2,\text{new}} = \frac{2(-2) + 3}{2 + 1} = -0.33. \]
Así, las nuevas coordenadas del centroide de \((ACD)\) son: \[ (1,\,-0.33). \]
Volviendo a la asignación inicial del Paso 1, ahora calculamos las distancias al cuadrado:
\[ d^2(A,(AB)) = (5-2)^2 + (3-2)^2 = 10, \] si \(A\) no se mueve.
\[ d^2(A,(CD)) = (5+1)^2 + (3+2)^2 = 61, \] si \(A\) se moviera al grupo \((CD)\).
\[ d^2(A,(B)) = (5-(-1))^2 + (3-1)^2 = 40, \] si \(A\) se moviera al nuevo grupo $(B).
\[ d^2(A,(ACD)) = (5-1)^2 + (3+0.33)^2 = 27.09. \]
Como \(A\) está más cerca del centro de \((AB)\) que del centro de \((ACD)\), no se reasigna.
Para el ítem \(B\) se obtiene:
\[ d^2(B,(AB)) = (-1-2)^2 + (1-2)^2 = 10, \] si B no se mueve.
\[ d^2(B,(CD)) = (-1+1)^2 + (1+2)^2 = 9, \] si B se moviera a $(CD). ]
\[ d^2(B,(A)) = (-1-5)^2 + (1-3)^2 = 40, \]
\[ d^2(B,(BCD)) = (-1+1)^2 + (1+1)^2 = 4. \]
Como \(B\) está más cerca del centro de \((BCD)\) que del de \((AB)\), \(B\) es reasignado al grupo \((CD)\).
Verificamos si \(C\) debe reasignarse:
\[ d^2(C,(A)) = (1-5)^2 + (-2-3)^2 = 41, \]
\[ d^2(C,(BCD)) = (1+1)^2 + (-2+1)^2 = 5. \]
\[ d^2(C,(A)) = (1-3)^2 + (-2-5)^2 = 102.25, \]
\[ d^2(C,(BCD)) = (1+2)^2 + (-2+5)^2 = 11.25. \]
Como \(C\) está más cerca del centro de \((BCD)\) que del centro de \((A)\), no se mueve.
Continuando de esta manera, no se producen más reasignaciones y los clústers finales son \((A)\) y \((BCD)\).
Tabla final de distancias al cuadrado al centroide
| Cluster | A | B | C | D |
|---|---|---|---|---|
| A | 0 | 40 | 41 | 89 |
| (BCD) | 52 | 4 | 5 | 5 |
La suma total de cuadrados dentro de los clústers (WSS) es:
Para el clúster A: \[ 0 \]
Para el clúster (BCD): \[ 4 + 5 + 5 = 14. \]
Equivalentemente, podemos determinar \(K=2\) clústers usando el criterio:
\[ \min E = \sum_{i} d^2_{i,c(i)}, \]
donde la suma es sobre todos los ítems y \(d^2_{i,c(i)}\) es la distancia al cuadrado entre el ítem \(i\) y el centroide del clúster asignado.
En este ejemplo existen siete posibilidades de partición para \(K = 2\) clústers:
A , (BCD)
B , (ACD)
C , (ABD)
D , (ABC)
(AB) , (CD)
(AC) , (BD)
(AD) , (BC)
Para la partición \(A,(BCD)\) se tiene:
\[ d^2_{A,c(A)} = 0, \]
para \((BCD)\):
\[ d^2_{B,c(B)} + d^2_{C,c(C)} + d^2_{D,c(D)} = 4 + 5 + 5 = 14. \]
Entonces:
\[ \sum_i d^2_{i,c(i)} = 0 + 14 = 14. \]
Para las restantes particiones se tiene:
B,(ACD) \(\sum d^2_{i,c(i)} = 48.7\)
C,(ABD) \(\sum d^2_{i,c(i)} = 27.7\)
D,(ABC) \(\sum d^2_{i,c(i)} = 31.3\)
(AB),(CD) \(\sum d^2_{i,c(i)} = 28\)
(AC),(BD) \(\sum d^2_{i,c(i)} = 27\)
(AD),(BC) \(\sum d^2_{i,c(i)} = 51.3\)
Dado que la suma mínima \(\sum d^2_{i,c(i)}\) ocurre para los grupos \((A)\) y \((BCD)\), esta es la solución final.
Veamos unos ejemplos en R.
Ejemplo 1: Usaremos la matriz del ejemplo pasado.
df <- data.frame(
x1 = c(5, -1, 1, -3),
x2 = c(3, 1, -2, -2),
row.names = c("A", "B", "C", "D")
)
df## x1 x2
## A 5 3
## B -1 1
## C 1 -2
## D -3 -2Para realiazar kmeans en R, usamos la función kmenas.
El parámetro nstart = 20 indica que intenta 20 configuraciones iniciales y se queda con la mejor.
La variable km2 tiene guardada toda la información de este algoritmo.
## K-means clustering with 2 clusters of sizes 1, 3
##
## Cluster means:
## x1 x2
## 1 5 3
## 2 -1 -1
##
## Clustering vector:
## A B C D
## 1 2 2 2
##
## Within cluster sum of squares by cluster:
## [1] 0 14
## (between_SS / total_SS = 73.6 %)
##
## Available components:
##
## [1] "cluster" "centers" "totss" "withinss" "tot.withinss"
## [6] "betweenss" "size" "iter" "ifault"## A B C D
## 1 2 2 2## x1 x2
## 1 5 3
## 2 -1 -1## [1] 0 14## [1] 14Podemos hacer un plot de estos clústers.
## Item x1 x2 Cluster
## A A 5 3 1
## B B -1 1 2
## C C 1 -2 2
## D D -3 -2 2# Especificamos colores por cluster
cols <- c("steelblue", "tomato")[km2$cluster]
# Usando R base
plot(df$x1, df$x2,
col = cols,
pch = 19,
xlab = "x1", ylab = "x2",
main = "Clustering k-means con K = 2")
text(df$x1, df$x2, labels = rownames(df),
pos = 3)
# Podemos añadir centroides
points(km2$centers[,1], km2$centers[,2],
pch = 8, cex = 2, lwd = 2)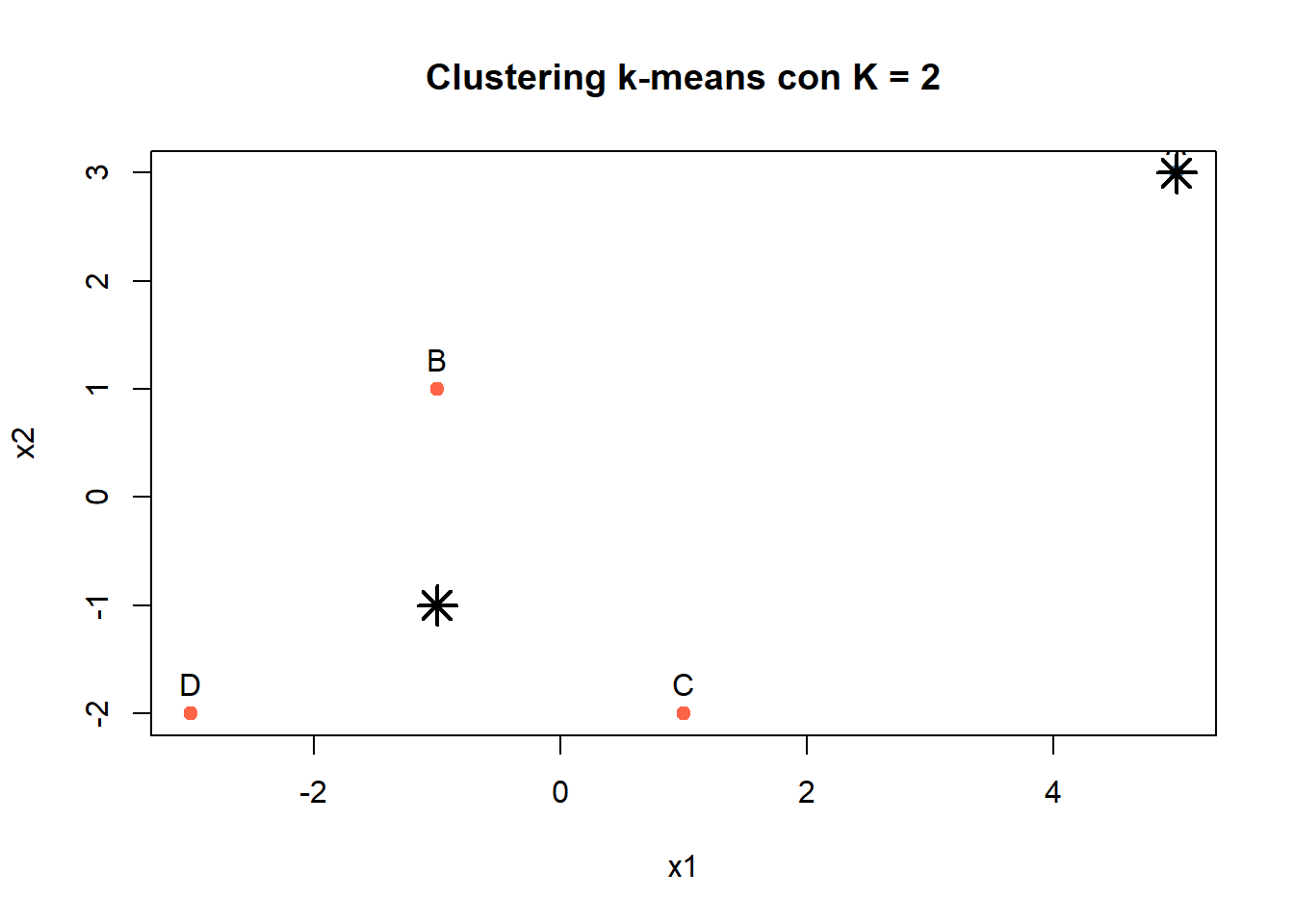
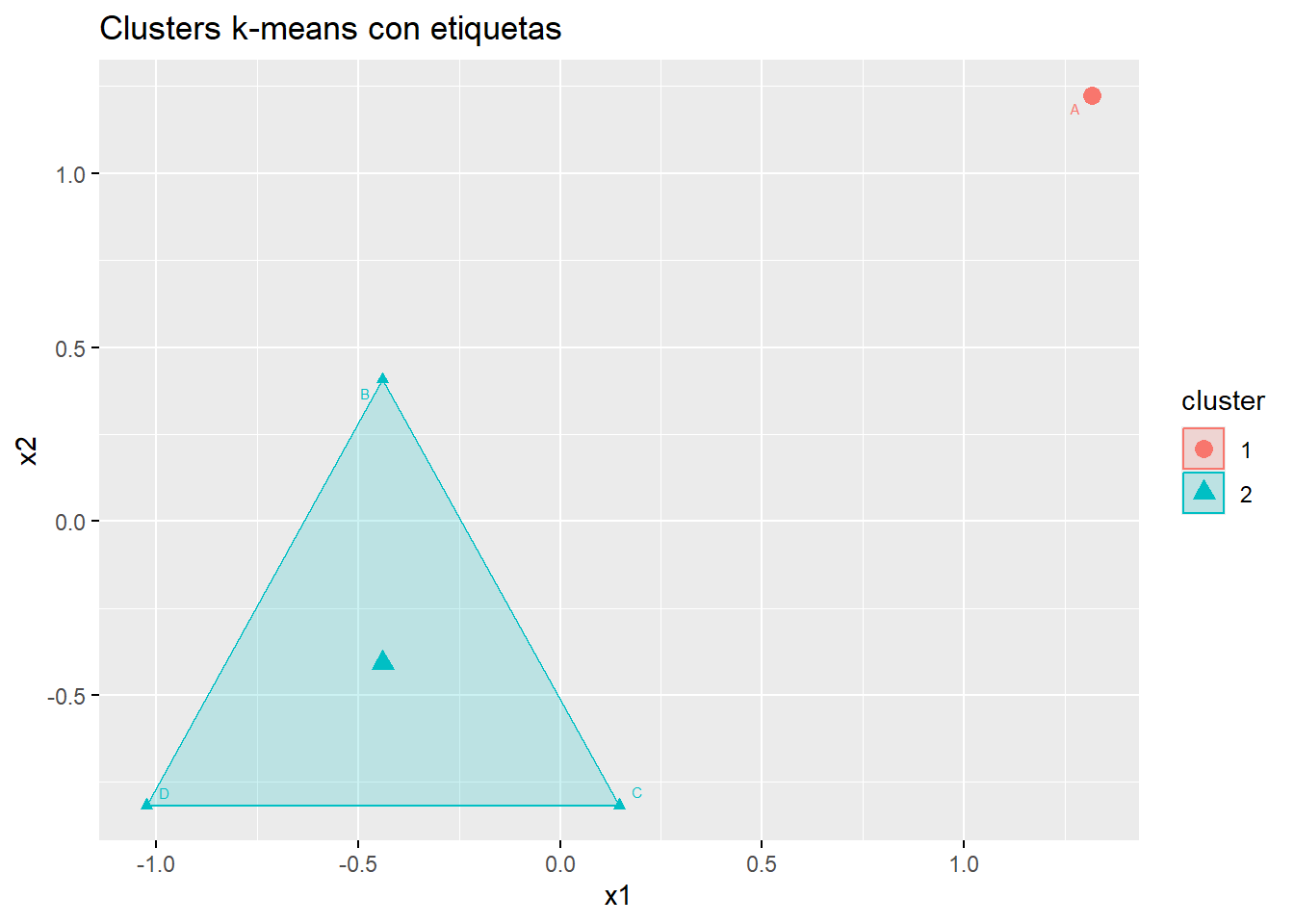
Otra forma de hacerlo, es con el paquete factoextra.
library(factoextra)
# debemos asegurarnos que nuestro df tenga como rownames los nombres de los items
#df_named <- df
#df_named$label <- rownames(df_named)
fviz_cluster(
km2,
data = df, #df_named
repel = TRUE,
labelsize = 6,
main = "Clusters k-means con etiquetas"
) 
Ejemplo 2: En este ejemplo se aplicará el algoritmo de K-means utilizando el conjunto de datos USArrests, disponible en R. Antes de realizar la agrupación, es necesario preparar el conjunto de datos asegurando que solo incluya variables numéricas continuas, ya que el método de K-means se basa en promedios y distancias entre observaciones.
Además, para evitar que las diferencias en escala entre las variables influyan en la formación de los grupos, por ejemplo, debido a que algunas variables se miden en unidades mucho mayores que otras, los datos se estandarizan utilizando la función scale() de R. Esta transformación permite que todas las variables contribuyan de manera equitativa al proceso de agrupación.
## Murder Assault UrbanPop Rape
## Alabama 1.24256408 0.78283935 -0.52090661 -0.003416473
## Alaska 0.50786248 1.10682252 -1.21176419 2.484202941
## Arizona 0.07163341 1.47880321 0.99898006 1.042878388
## Arkansas 0.23234938 0.23086801 -1.07359268 -0.184916602
## California 0.27826823 1.26281442 1.75892340 2.067820292
## Colorado 0.02571456 0.39885929 0.86080854 1.864967207
## Connecticut -1.03041900 -0.72908214 0.79172279 -1.081740768
## Delaware -0.43347395 0.80683810 0.44629400 -0.579946294
## Florida 1.74767144 1.97077766 0.99898006 1.138966691
## Georgia 2.20685994 0.48285493 -0.38273510 0.487701523
## Hawaii -0.57123050 -1.49704226 1.20623733 -0.110181255
## Idaho -1.19113497 -0.60908837 -0.79724965 -0.750769945
## Illinois 0.59970018 0.93883125 1.20623733 0.295524916
## Indiana -0.13500142 -0.69308401 -0.03730631 -0.024769429
## Iowa -1.28297267 -1.37704849 -0.58999237 -1.060387812
## Kansas -0.41051452 -0.66908525 0.03177945 -0.345063775
## Kentucky 0.43898421 -0.74108152 -0.93542116 -0.526563903
## Louisiana 1.74767144 0.93883125 0.03177945 0.103348309
## Maine -1.30593210 -1.05306531 -1.00450692 -1.434064548
## Maryland 0.80633501 1.55079947 0.10086521 0.701231086
## Massachusetts -0.77786532 -0.26110644 1.34440885 -0.526563903
## Michigan 0.99001041 1.01082751 0.58446551 1.480613993
## Minnesota -1.16817555 -1.18505846 0.03177945 -0.676034598
## Mississippi 1.90838741 1.05882502 -1.48810723 -0.441152078
## Missouri 0.27826823 0.08687549 0.30812248 0.743936999
## Montana -0.41051452 -0.74108152 -0.86633540 -0.515887425
## Nebraska -0.80082475 -0.82507715 -0.24456358 -0.505210947
## Nevada 1.01296983 0.97482938 1.06806582 2.644350114
## New Hampshire -1.30593210 -1.36504911 -0.65907813 -1.252564419
## New Jersey -0.08908257 -0.14111267 1.62075188 -0.259651949
## New Mexico 0.82929443 1.37080881 0.30812248 1.160319648
## New York 0.76041616 0.99882813 1.41349461 0.519730957
## North Carolina 1.19664523 1.99477641 -1.41902147 -0.547916860
## North Dakota -1.60440462 -1.50904164 -1.48810723 -1.487446939
## Ohio -0.11204199 -0.60908837 0.65355127 0.017936483
## Oklahoma -0.27275797 -0.23710769 0.16995096 -0.131534211
## Oregon -0.66306820 -0.14111267 0.10086521 0.861378259
## Pennsylvania -0.34163624 -0.77707965 0.44629400 -0.676034598
## Rhode Island -1.00745957 0.03887798 1.48258036 -1.380682157
## South Carolina 1.51807718 1.29881255 -1.21176419 0.135377743
## South Dakota -0.91562187 -1.01706718 -1.41902147 -0.900240639
## Tennessee 1.24256408 0.20686926 -0.45182086 0.605142783
## Texas 1.12776696 0.36286116 0.99898006 0.455672088
## Utah -1.05337842 -0.60908837 0.99898006 0.178083656
## Vermont -1.28297267 -1.47304350 -2.31713632 -1.071064290
## Virginia 0.16347111 -0.17711080 -0.17547783 -0.056798864
## Washington -0.86970302 -0.30910395 0.51537975 0.530407436
## West Virginia -0.47939280 -1.07706407 -1.83353601 -1.273917376
## Wisconsin -1.19113497 -1.41304662 0.03177945 -1.113770203
## Wyoming -0.22683912 -0.11711392 -0.38273510 -0.601299251
## attr(,"scaled:center")
## Murder Assault UrbanPop Rape
## 7.788 170.760 65.540 21.232
## attr(,"scaled:scale")
## Murder Assault UrbanPop Rape
## 4.355510 83.337661 14.474763 9.366385La función kmeans() es la encargada de ejecutar el algoritmo de K-means en R. Los principales argumentos de entrada:
x: Conjunto de datos a utilizar para la agrupación. Puede ser una matriz numérica, un data frame numérico o un vector numérico.centers: Indica el número de clústers deseados (k) o bien un conjunto de centroides iniciales. Si se especifica un número, el algoritmo selecciona aleatoriamente filas distintas de x como centroides iniciales.iter.max: Número máximo de iteraciones permitidas para la ejecución del algoritmo. Su valor por defecto es 10.nstart: Cantidad de asignaciones iniciales aleatorias que se generan cuando centers es un número. Se recomienda usar un valor mayor que 1 para obtener soluciones más estables.
Vamos a estimar primero la cantidad óptima de clústers usando el método del codo.
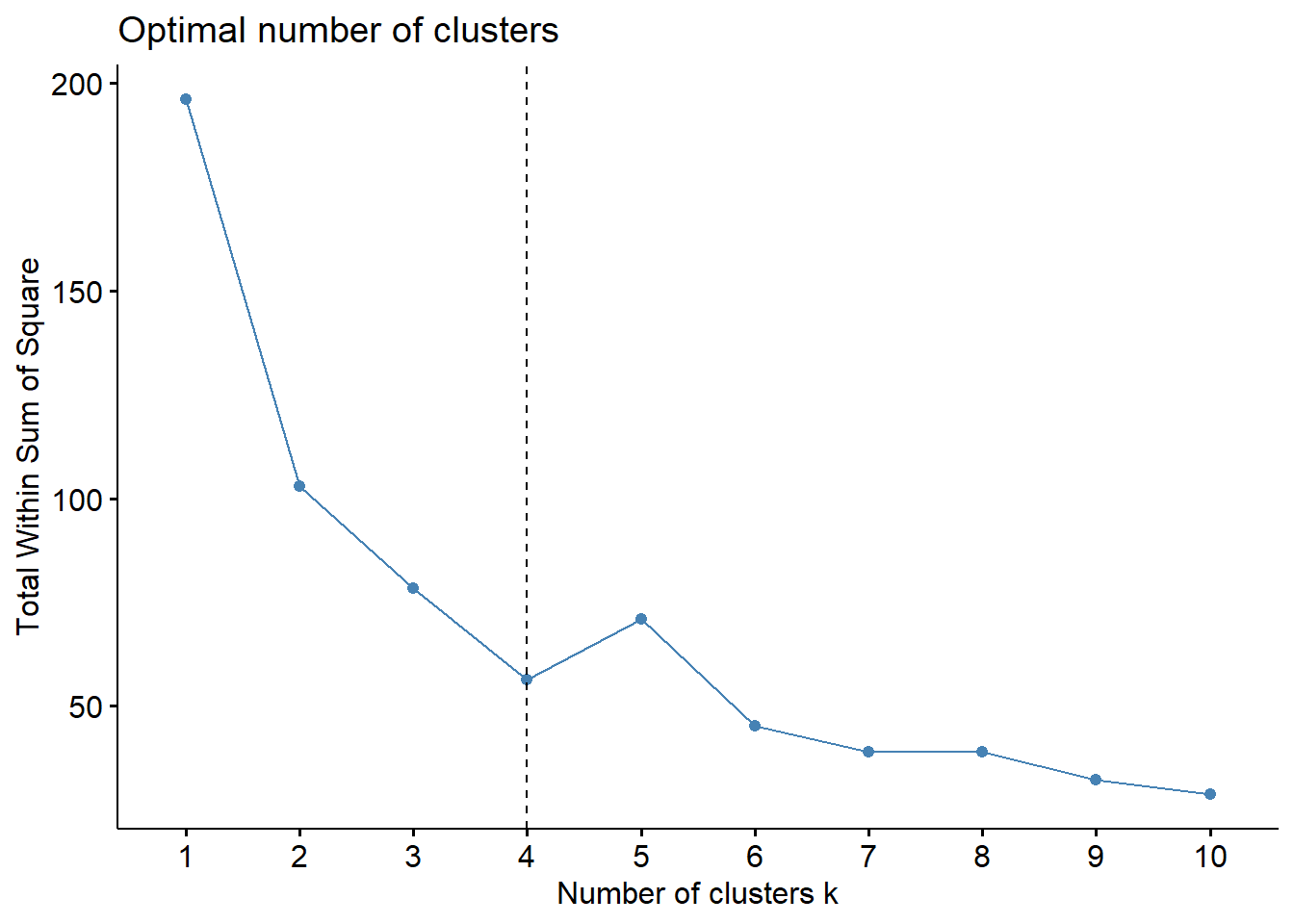
El gráfico anterior representa cómo cambia la variabilidad interna de los grupos conforme aumenta el número de clústers \(k\). Como es esperable, al incrementar el número de clústers la variación dentro de cada grupo disminuye. No obstante, se identifica un punto de inflexión alrededor de \(k=4\), donde la reducción de la varianza deja de ser tan significativa. Este punto, conocido como el método del codo, sugiere que a partir de \(k=4\) añadir más clústers no aporta mejoras sustanciales en la homogeneidad interna. Por ello, se considera que el valor adecuado de \(k\) para estos datos es aproximadamente 4.
Como al inicializar el algoritmo, se seleccionan al aleatoriamente los centroides, debemos inicializar una semilla.
Al establecer nstart = 25, R realizará 25 asignaciones de inicio aleatorias y luego seleccionará los resultados que correspondan a la asignación con la variación más baja dentro de los clusters. El valor predeterminado de nstart es 1, lo que significa que solo se realiza una asignación aleatoria inicial.
## K-means clustering with 4 clusters of sizes 8, 13, 16, 13
##
## Cluster means:
## Murder Assault UrbanPop Rape
## 1 1.4118898 0.8743346 -0.8145211 0.01927104
## 2 -0.9615407 -1.1066010 -0.9301069 -0.96676331
## 3 -0.4894375 -0.3826001 0.5758298 -0.26165379
## 4 0.6950701 1.0394414 0.7226370 1.27693964
##
## Clustering vector:
## Alabama Alaska Arizona Arkansas California
## 1 4 4 1 4
## Colorado Connecticut Delaware Florida Georgia
## 4 3 3 4 1
## Hawaii Idaho Illinois Indiana Iowa
## 3 2 4 3 2
## Kansas Kentucky Louisiana Maine Maryland
## 3 2 1 2 4
## Massachusetts Michigan Minnesota Mississippi Missouri
## 3 4 2 1 4
## Montana Nebraska Nevada New Hampshire New Jersey
## 2 2 4 2 3
## New Mexico New York North Carolina North Dakota Ohio
## 4 4 1 2 3
## Oklahoma Oregon Pennsylvania Rhode Island South Carolina
## 3 3 3 3 1
## South Dakota Tennessee Texas Utah Vermont
## 2 1 4 3 2
## Virginia Washington West Virginia Wisconsin Wyoming
## 3 3 2 2 3
##
## Within cluster sum of squares by cluster:
## [1] 8.316061 11.952463 16.212213 19.922437
## (between_SS / total_SS = 71.2 %)
##
## Available components:
##
## [1] "cluster" "centers" "totss" "withinss" "tot.withinss"
## [6] "betweenss" "size" "iter" "ifault"Calculemos la media de cada variable para cada cluster utilizando los datos originales.
## cluster Murder Assault UrbanPop Rape
## 1 1 13.93750 243.62500 53.75000 21.41250
## 2 2 3.60000 78.53846 52.07692 12.17692
## 3 3 5.65625 138.87500 73.87500 18.78125
## 4 4 10.81538 257.38462 76.00000 33.19231Podemos agregarle a la base de datos originales una columna que nos indique en que clúster quedó cada observación.
## Murder Assault UrbanPop Rape cluster
## Alabama 13.2 236 58 21.2 1
## Alaska 10.0 263 48 44.5 4
## Arizona 8.1 294 80 31.0 4
## Arkansas 8.8 190 50 19.5 1
## California 9.0 276 91 40.6 4
## Colorado 7.9 204 78 38.7 4Cuando se trabaja con más de dos variables, una forma de visualizar los grupos obtenidos mediante clustering es reducir la dimensionalidad con un método como el Análisis de Componentes Principales.
Usando las dos primeras componentes principales como ejes, es posible construir un diagrama de dispersión en dos dimensiones y colorear los puntos según el clúster asignado. Esta visualización facilita interpretar la estructura de los datos, comparar distintas particiones y evaluar si el número de clústers elegido resulta apropiado.
fviz_cluster(km.res, data = df,
palette = c("#FF0000", "#0000FF", "#000000", "#C870FF"),
ellipse.type = "euclid", # Agregar elipses
star.plot = TRUE, # Añadir segmentos desde los centroides a los datos
repel = TRUE, # que no se sobrelapen
ggtheme = theme_minimal())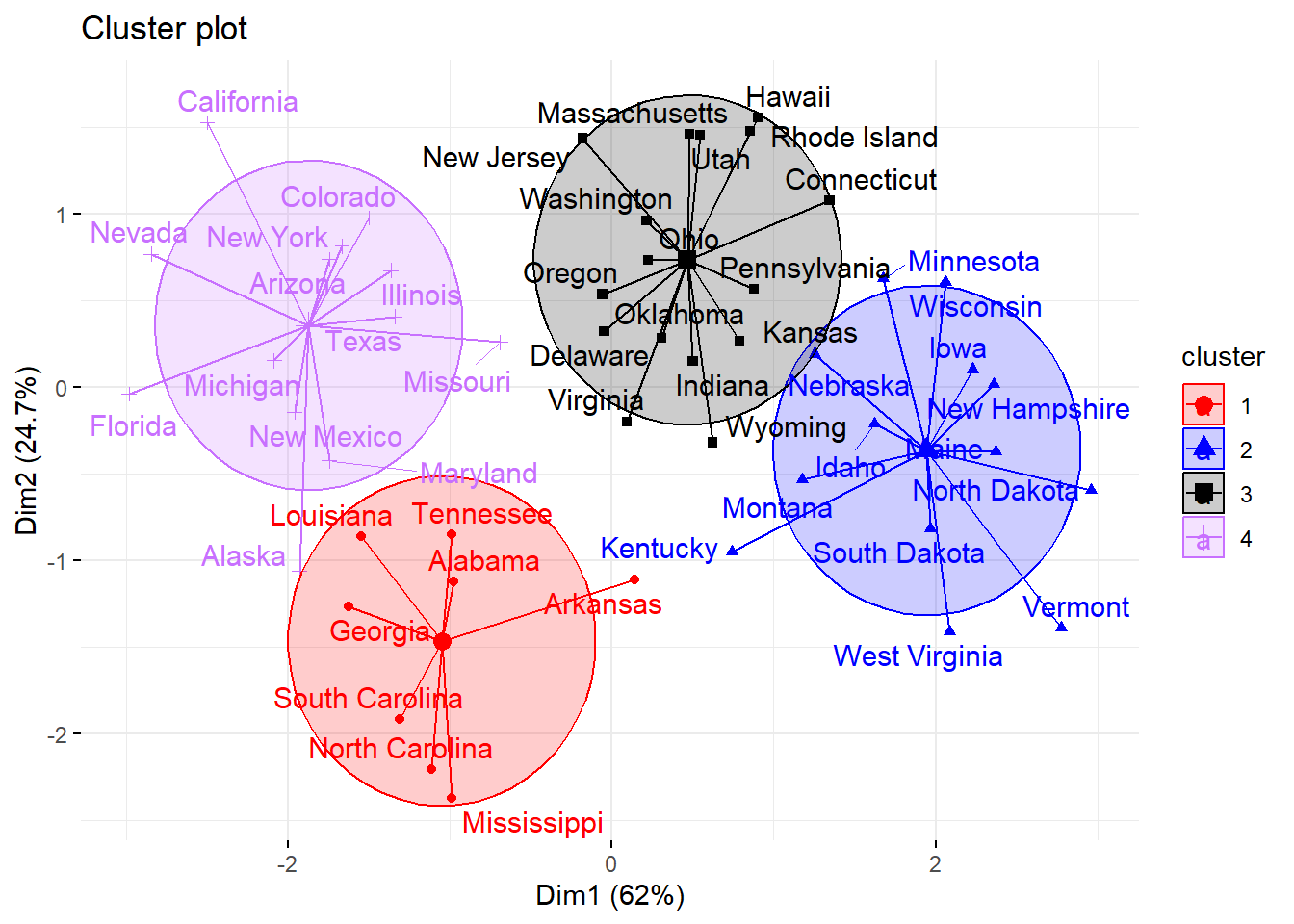
5.4.2 Ejercicios
Ejercicio 1: Los siguientes datos fueron colectados en 22 compañías públicas de EU en 1975. Estandarizar las variables. Ajustar modelos k-means para 4 y 5 clústers. Reportar: tamaño de cada clúster, empresas en cada clúster, distancias entre centroides y proporción de variación explicada. Comparar la calidad de la partición (dentro vs. entre clústers). Puedes comentar cuál de los dos K “separa mejor” (ratio más grande) y si esa mejora justifica pasar de 4 a 5 clústers. Busca el “codo” de la curva y comenta si K=4 o K=5 son valores razonables. Interpretar los clústers: ¿qué variables parecen distinguir más los grupos? ¿qué tipo de empresas se agrupan juntas (por tamaño, porcentaje nuclear, ventas, etc.)?
| ID | Company | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Arizona Public Service | 1.06 | 9.2 | 151 | 54.4 | 1.6 | 9077 | 0 | 0.628 |
| 2 | Boston Edison Co. | 0.89 | 10.3 | 202 | 57.9 | 2.2 | 5088 | 25.3 | 1.555 |
| 3 | Central Louisiana Electric Co. | 1.43 | 15.4 | 113 | 53.0 | 3.4 | 9212 | 0 | 1.058 |
| 4 | Commonwealth Edison Co. | 1.02 | 11.2 | 168 | 56.0 | 0.3 | 6423 | 34.3 | 0.700 |
| 5 | Consolidated Edison Co. (N.Y.) | 1.49 | 8.8 | 192 | 51.2 | 1.0 | 3300 | 15.6 | 2.044 |
| 6 | Florida Power & Light Co. | 1.32 | 13.5 | 111 | 60.0 | -2.2 | 11127 | 22.5 | 1.241 |
| 7 | Hawaiian Electric Co. | 1.22 | 12.2 | 175 | 67.6 | 2.2 | 7642 | 0 | 1.652 |
| 8 | Idaho Power Co. | 1.10 | 9.2 | 245 | 57.0 | 3.3 | 13082 | 0 | 0.309 |
| 9 | Kentucky Utilities Co. | 1.34 | 13.0 | 168 | 60.4 | 7.2 | 8406 | 0 | 0.862 |
| 10 | Madison Gas & Electric Co. | 1.12 | 12.4 | 197 | 53.0 | 2.7 | 6455 | 39.2 | 0.623 |
| 11 | Nevada Power Co. | 0.75 | 7.5 | 173 | 51.5 | 6.5 | 17441 | 0 | 0.768 |
| 12 | New England Electric Co. | 1.13 | 10.9 | 178 | 62.0 | 3.7 | 6154 | 0 | 1.897 |
| 13 | Northern States Power Co. | 1.15 | 12.7 | 199 | 53.7 | 6.4 | 7179 | 50.2 | 0.527 |
| 14 | Oklahoma Gas & Electric Co. | 1.09 | 12.0 | 96 | 49.8 | 1.4 | 9673 | 0 | 0.588 |
| 15 | Pacific Gas & Electric Co. | 0.96 | 7.6 | 164 | 62.2 | -0.1 | 6468 | 0.9 | 1.400 |
| 16 | Puget Sound Power & Light Co. | 1.16 | 9.9 | 252 | 56.0 | 9.2 | 15991 | 0 | 0.620 |
| 17 | San Diego Gas & Electric Co. | 0.76 | 6.4 | 136 | 61.9 | 9.0 | 5714 | 8.3 | 1.920 |
| 18 | The Southern Co. | 1.05 | 12.6 | 150 | 56.7 | 2.7 | 10140 | 0 | 1.108 |
| 19 | Texas Utilities Co. | 1.16 | 11.7 | 104 | 54.0 | -2.1 | 13507 | 0 | 0.636 |
| 20 | Wisconsin Electric Power Co. | 1.20 | 11.8 | 148 | 59.9 | 3.5 | 7287 | 41.1 | 0.702 |
| 21 | United Illuminating Co. | 1.04 | 8.6 | 204 | 61.0 | 3.5 | 6650 | 0 | 2.116 |
| 22 | Virginia Electric & Power Co. | 1.07 | 9.3 | 174 | 54.3 | 5.9 | 10093 | 26.6 | 1.306 |
Clave de variables:
\(X_1\): Razón de cobertura de cargos fijos (ingreso/deuda).
\(X_2\): Tasa de retorno sobre el capital.
\(X_3\): Costo por kW de capacidad instalada.
\(X_4\): Factor de carga anual.
\(X_5\): Crecimiento máximo de demanda en kWh de 1974 a 1975.
\(X_6\): Ventas (kWh utilizadas por año).
\(X_7\): Porcentaje de generación nuclear.
\(X_8\): Costo total de combustible (centavos por kWh).
utilities <- data.frame(
ID = 1:22,
Company = c(
"Arizona Public Service",
"Boston Edison Co.",
"Central Louisiana Electric Co.",
"Commonwealth Edison Co.",
"Consolidated Edison Co. (N.Y.)",
"Florida Power & Light Co.",
"Hawaiian Electric Co.",
"Idaho Power Co.",
"Kentucky Utilities Co.",
"Madison Gas & Electric Co.",
"Nevada Power Co.",
"New England Electric Co.",
"Northern States Power Co.",
"Oklahoma Gas & Electric Co.",
"Pacific Gas & Electric Co.",
"Puget Sound Power & Light Co.",
"San Diego Gas & Electric Co.",
"The Southern Co.",
"Texas Utilities Co.",
"Wisconsin Electric Power Co.",
"United Illuminating Co.",
"Virginia Electric & Power Co."
),
X1 = c(1.06, 0.89, 1.43, 1.02, 1.49, 1.32, 1.22, 1.10, 1.34, 1.12,
0.75, 1.13, 1.15, 1.09, 0.96, 1.16, 0.76, 1.05, 1.16, 1.20,
1.04, 1.07),
X2 = c(9.2, 10.3, 15.4, 11.2, 8.8, 13.5, 12.2, 9.2, 13.0, 12.4,
7.5, 10.9, 12.7, 12.0, 7.6, 9.9, 6.4, 12.6, 11.7, 11.8,
8.6, 9.3),
X3 = c(151, 202, 113, 168, 192, 111, 175, 245, 168, 197,
173, 178, 199, 96, 164, 252, 136, 150, 104, 148,
204, 174),
X4 = c(54.4, 57.9, 53.0, 56.0, 51.2, 60.0, 67.6, 57.0, 60.4, 53.0,
51.5, 62.0, 53.7, 49.8, 62.2, 56.0, 61.9, 56.7, 54.0, 59.9,
61.0, 54.3),
X5 = c(1.6, 2.2, 3.4, 0.3, 1.0, -2.2, 2.2, 3.3, 7.2, 2.7,
6.5, 3.7, 6.4, 1.4, -0.1, 9.2, 9.0, 2.7, -2.1, 3.5,
3.5, 5.9),
X6 = c(9077, 5088, 9212, 6423, 3300, 11127, 7642, 13082, 8406, 6455,
17441, 6154, 7179, 9673, 6468, 15991, 5714, 10140, 13507, 7287,
6650, 10093),
X7 = c(0.0, 25.3, 0.0, 34.3, 15.6, 22.5, 0.0, 0.0, 0.0, 39.2,
0.0, 0.0, 50.2, 0.0, 0.9, 0.0, 8.3, 0.0, 0.0, 41.1,
0.0, 26.6),
X8 = c(0.628, 1.555, 1.058, 0.700, 2.044, 1.241, 1.652, 0.309, 0.862, 0.623,
0.768, 1.897, 0.527, 0.588, 1.400, 0.620, 1.920, 1.108, 0.636, 0.702,
2.116, 1.306)
)Ejercicio 2: Utilizando el conjunto de datos mtcars, incluido por defecto en R, que contiene información sobre distintas características de automóviles: consumo de gasolina, cilindrada, caballos de fuerza, peso, etc. Aplica k-means para identificar posibles grupos de automóviles con características mecánicas similares.
Ejercicio 3: El conjunto de datos Iris es un clásico en biología y machine learning. Incluye mediciones de tres especies de flores del género Iris: Setosa, versicolor y virginica. Consta de 4 variables: sepal length, sepal width, petal length, petal width. Aplicar k-means para identificar patrones naturales en las mediciones de las flores y compararlos con las especies reales.
Solución en Python
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import pandas as pd
import matplotlib.pyplot as plt
# Cargar dataset
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
# Convertir a DataFrame
df = pd.DataFrame(X, columns=feature_names)
df["species"] = y
# Escalar
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Aplicar K-means con k=3
kmeans = KMeans(n_clusters=3, n_init=20, random_state=42)
labels = kmeans.fit_predict(X_scaled)
df["cluster"] = labels
print("Centros de los clusters (estandarizados):")
print(kmeans.cluster_centers_)
print("\nTamaño de cada cluster:")
print(df["cluster"].value_counts())
# Visualización
plt.figure(figsize=(7,5))
scatter = plt.scatter(
df["sepal length (cm)"],
df["petal length (cm)"],
c=df["cluster"], s=80
)
plt.xlabel("Largo del sépalo")
plt.ylabel("Largo del pétalo")
plt.title("k-means en el dataset Iris (k = 3)")
plt.colorbar(scatter, label="Cluster")
plt.tight_layout()
plt.show()5.5 Otros métodos
Otros métodos de clustering son por ejemplo DBSCAN y UMAP. Existen también métodos basados en modelos estadísticos, una buena referencia es el libro de Johnson y Wichern.
5.6 Ejemplo Completo
Según el diccionario de la Real Academia Española (RAE, 2014), bienestar proviene de la unión de las palabras bien y estar. Es el conjunto de las cosas necesarias para vivir bien. También lo define como vida holgada o abastecida de cuanto conduce a pasarlo bien y con tranquilidad.
El presente trabajo tiene por objetivo analizar el bienestar de manera multivariante y territorial, para tal cometido se ha tomado varias dimensiones que afectan al bienestar como la marginación, la pobreza, la desigualdad. Adicionalmente se toma en consideración al desarrollo humano que es una medida que favorece al bienestar.
A nivel territorial se ha tomado los datos de Ecuador provenientes del Censo de Población y Vivienda 2010. Se usará por tanto una base de datos denominada base.csv que contiene las diferentes dimensiones a ser estudiadas.
Usaremos la base de datos base.csv con las siguientes variables:
Región natural: Costa, Sierra, Amazonía y Galápagos.
Estado: 24 estados.
Municipio: 24 capitales de estados.
Dimensión 1: Porcentaje de población de 15 años o más analfabeta.
Dimensión 2: Porcentaje de población de 15 años o más sin primaria completa.
Dimensión 3: Porcentaje de ocupantes en viviendas particulares habitadas sin drenaje ni servicio sanitario.
Dimensión 4: Porcentaje de ocupantes en viviendas particulares habitadas sin energía eléctrica.
Dimensión 5: Porcentaje de ocupantes en viviendas particulares habitadas sin agua entubada.
Dimensión 6: Porcentaje de viviendas particulares habitadas con algún nivel de hacinamiento.
Dimensión 7: Porcentaje de ocupantes de viviendas particulares habitadas con piso de tierra.
Dimensión 8: Porcentaje de población ocupada con ingresos de hasta dos salarios mínimos
Densidad poblacional: habitantes por \(Km^{2}\)
IDH: Índice de Desarrollo Humano
Pobre: pobreza por consumo (%)
Gini: Índice de desigualdad
Para iniciar con nuestros análisis, cargamos la base de datos que utilizaremos.
library(readr)
base <- read_csv("D:/Users/hayde/Documents/R_sites/MultivariateStatisticalAnalysis/data/base.csv")
base2 <- base[,c(2,4:16)]en esta sección se describen gráficos multivariados. Se muestran las gráficas paralelas, que representa correlación entre variables, donde cada línea es una observación o individuo.
Dado que en Ecuador existen cuatro regiones, a saber: la Sierra, Amazonía, la Costa e Insular, cada una se colorea con distintos tonos, a fin de visualizar los cambios por variable. Se aprecia que la variable sobre la proporción de piso de tierra es la que tiene la tasa más baja, seguida por el porcentaje de población sin educación primaria completa.
Así mismo, se vislumbra que la región con el porcentaje más bajo de variables que reflejan vulnerabilidad es la Insular, seguida por la región de Sierra. Mientras que la Amazonía es la región con mayor vulnerabilidad, al presentar porcentajes más altos.
Por otra parte, se distingue que hay correlación entre las variables de pobreza, piso de tierra, al menos dos salarios mínimos, y las relativas a la educación. Esto se ve ya que hay líneas paralelas, lo que implica un patrón en el país. En contraste, hay cruce entre líneas entre las vairables de porcentaje de población sin primaria completa, el índice de gini, y el Índice de Desarrollo humano.
Plot de paralelas
library(GGally)
ggparcoord(base, columns = c(8, 9, 16, 7, 15, 10, 14, 13, 6, 11, 5, 12),
groupColumn = 2, showPoints = TRUE,
title = "",
alphaLines = 1, scale = "uniminmax"
# order = "Outlying"
) 
(#fig:parellel plot)Gráfico de paralelas
Se muestra otro tipo de esquema. En las gráficas de estrellas, cada una es un estado, y la longitud de los “brazos” implica el rango de la variable. Se aprecia que aquellas regiones con estrellas más grandes en variables de marginación (i1-i8), son las mismas con estrellas más pequeñas para variables que expresan bienestar (como el índice de gini, idh, y densidad poblacional).
Plot de estrellas
par(mfrow= c(2,2))#cuatro tipos de gráficas
#Se segmenta a las variables en función del factor que expresan.
stars(base2[, 3:7],len = 1.3, key.loc = c(-1,11), lwd = 1, col.segments = T, col.lines = 1:24, )
stars(base2[, c(7:10, 13)],len = 1.3, key.loc = c(-1,11), lwd = 1, col.segments = T, col.lines = 1:24, )
stars(base2[, c(11:12,14)], scale = T, len = 1.3, key.loc = c(-1,11), lwd = 1, col.segments = T, col.lines = 1:24)
(#fig:grafica estrellas)Gráfico de estrellas
El siguiente gráfico muestra la correlación entre variables. Se ha tachado las variables que no son significantes.
library(corrplot)
cor_base <- cor(base2[,3:14], use="complete.obs")
cor.mtest <- function(mat, ...) {
mat <- as.matrix(mat)
n <- ncol(mat)
p.mat<- matrix(NA, n, n)
diag(p.mat) <- 0
for (i in 1:(n - 1)) {
for (j in (i + 1):n) {
tmp <- cor.test(mat[, i], mat[, j], ...)
p.mat[i, j] <- p.mat[j, i] <- tmp$p.value
}
}
colnames(p.mat) <- rownames(p.mat) <- colnames(mat)
p.mat
}
# matrix of the p-value of the correlation
p.mat <- cor.mtest(cor_base)
corrplot(cor_base, type = "upper", order = "hclust", tl.col = "black", tl.srt = 45, p.mat = p.mat, sig.level = 0.05)
Figure 5.14: Correlograma con significancia
5.6.1 Análisis de componentes principales
El análisis de componenetes principales tiene como objetivo reducir la dimensión y conservar en lo posible su estructura, es decir la ”forma” de la nube de datos para esto el primer paro es obtener la matriz de correlaciones y la matriz de covarianzas.
Cuando se trabaja con distintas unidades de medición, conviene hacer el análisis de componentes principales haciendo los cálculos con la matriz R de correlaciones.
Calculamos primero la matriz de correlación.
base.cp1 <- data.matrix(base2)
res1 <- cor.mtest(base.cp1, conf.level= .95)
res2 <- cor.mtest(base.cp1, conf.level= .99)
cor.mat <- cor(base2[,c(3:14)], use="complete.obs")
corrplot(cor.mat)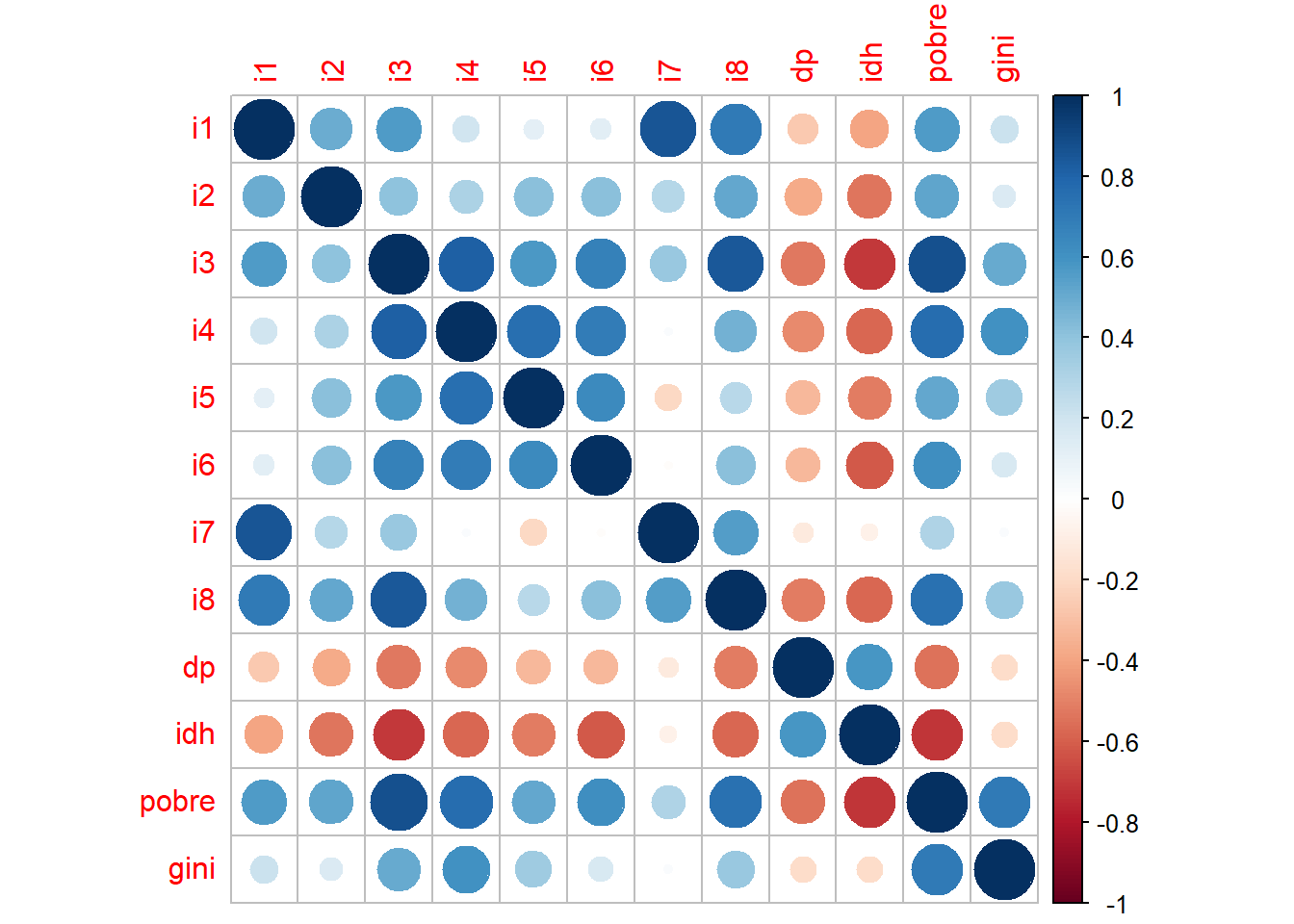
Figure 5.15: Gráfico de correlaciones
La prueba de Kaiser-Meyer-Olkin (KMO) es una medida de qué tan adecuados son sus datos para el análisis factorial . La prueba mide la adecuación del muestreo para cada variable en el modelo y para el modelo completo. La estadística es una medida de la proporción de varianza entre variables que podrían ser varianza común.
Como referencia, Kaiser puso los siguientes valores en los resultados:
0.00 a 0.49 inaceptable. 0.50 a 0.59 miserable. 0,60 a 0,69 mediocre. 0.70 a 0.79 medio. 0,80 a 0,89 meritorio. 0.90 a 1.00 maravilloso.
En nuestro caso observamos que al remover las variables “dp”, “gini”, “i2” e “i7” el valor del test KMO sube de 0.62 a 0.79, por este motivo decidimos remover estas variables para los análisis siguientes, ademas en la grafica de la matriz de correlaciones podemos observar que para las variables i7 i2 no se observa correlación con la mayoría de las otras variables.
##
## Adjuntando el paquete: 'psych'## The following objects are masked from 'package:ggplot2':
##
## %+%, alpha## Kaiser-Meyer-Olkin factor adequacy
## Call: KMO(r = base.cp1)
## Overall MSA = 0.62
## MSA for each item =
## i1 i2 i3 i4 i5 i6 i7 i8 dp idh pobre gini
## 0.60 0.57 0.68 0.70 0.60 0.64 0.47 0.64 0.58 0.75 0.65 0.39## Kaiser-Meyer-Olkin factor adequacy
## Call: KMO(r = base.cp1)
## Overall MSA = 0.79
## MSA for each item =
## i1 i3 i4 i5 i6 i8 idh pobre
## 0.73 0.75 0.68 0.81 0.87 0.75 0.90 0.87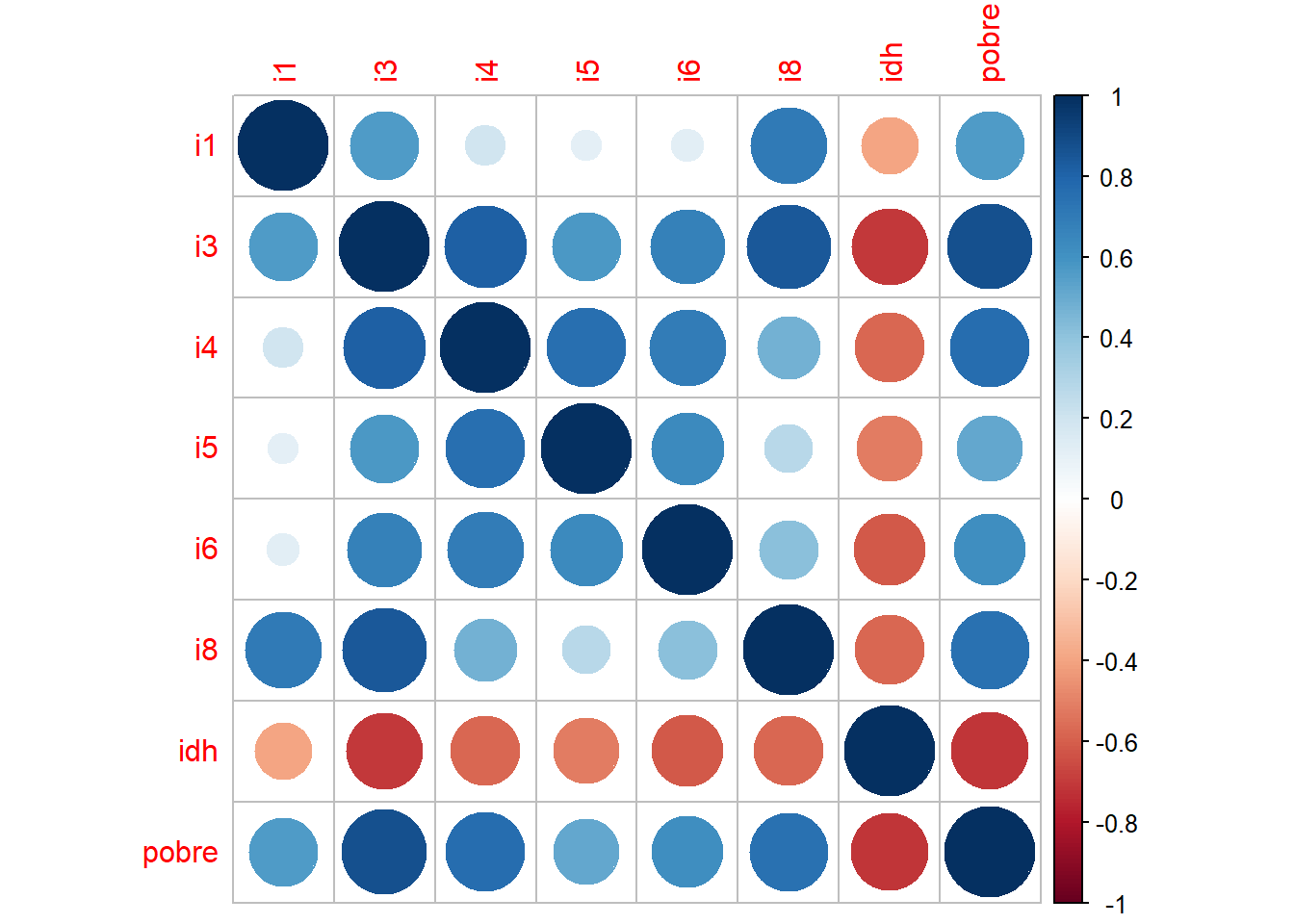
Figure 5.16: Gráfico de correlaciones ajustado
Vamos a proceder a realizar el análisis de componentes principales.
## i1 i3 i4 i5 i6 i8 idh pobre
## CUENCA 0.0487 0.1121 0.0121 0.0318 0.2238 0.3510 0.875 0.15
## GUARANDA 0.1809 0.5266 0.1204 0.1582 0.3672 0.5975 0.714 0.51
## AZOGUES 0.0819 0.1937 0.0177 0.0662 0.2375 0.4391 0.727 0.26
## TULCAN 0.0550 0.1140 0.0429 0.0498 0.3411 0.3423 0.727 0.33
## LATACUNGA 0.0931 0.3238 0.0368 0.0395 0.3046 0.4685 0.722 0.37
## RIOBAMBA 0.0836 0.1816 0.0286 0.0423 0.2273 0.3562 0.780 0.28
## MACHALA 0.0310 0.1235 0.0210 0.0942 0.3239 0.2888 0.780 0.16
## ESMERALDAS 0.0534 0.1668 0.0713 0.1114 0.3389 0.2153 0.718 0.32
## GUAYAQUIL 0.0309 0.0982 0.0688 0.1322 0.3473 0.2133 0.863 0.14
## IBARRA 0.0548 0.1002 0.0119 0.0191 0.2673 0.3130 0.784 0.23
## LOJA 0.0314 0.1260 0.0191 0.0317 0.2958 0.3063 0.796 0.19
## BABAHOYO 0.0669 0.2818 0.0778 0.2019 0.4022 0.4375 0.705 0.30
## PORTOVIEJO 0.0664 0.2249 0.0560 0.2848 0.3088 0.2888 0.733 0.19
## MORONA 0.0525 0.3846 0.1512 0.2190 0.3430 0.4403 0.708 0.43
## TENA 0.0493 0.4985 0.1902 0.2930 0.4221 0.4832 0.731 0.57
## PASTAZA 0.0717 0.4216 0.2228 0.2902 0.3051 0.4160 0.711 0.42
## QUITO 0.0299 0.0436 0.0061 0.0112 0.2102 0.2475 0.821 0.11
## AMBATO 0.0697 0.2237 0.0208 0.0624 0.2530 0.4351 0.794 0.23
## ZAMORA 0.0423 0.3283 0.0645 0.0891 0.3519 0.4230 0.694 0.31
## SAN CRISTOBAL 0.0129 0.0292 0.0099 0.0370 0.2463 0.2385 0.801 0.00
## LAGO AGRIO 0.0609 0.3463 0.1405 0.4907 0.3794 0.3933 0.716 0.35
## ORELLANA 0.0558 0.3845 0.2264 0.4110 0.4010 0.4132 0.701 0.45
## SANTO DOMINGO 0.0630 0.1759 0.0443 0.3535 0.3415 0.3646 0.737 0.27
## SANTA ELENA 0.0558 0.4339 0.1395 0.1745 0.4351 0.4794 0.712 0.29## Importance of components:
## Comp.1 Comp.2 Comp.3 Comp.4 Comp.5
## Standard deviation 2.2619624 1.1774584 0.67794519 0.62045643 0.54095096
## Proportion of Variance 0.6395592 0.1733010 0.05745121 0.04812077 0.03657849
## Cumulative Proportion 0.6395592 0.8128602 0.87031146 0.91843223 0.95501072
## Comp.6 Comp.7 Comp.8
## Standard deviation 0.46406345 0.33236941 0.18463456
## Proportion of Variance 0.02691936 0.01380868 0.00426124
## Cumulative Proportion 0.98193008 0.99573876 1.00000000Con la instrucción loadings lo que obtenemos son las cargas de los componentes principales. Es decir, lo que obtenemos son los coeficientes que se usarán en las combinaciones lineales para calcular cada componente principal. Por ejemplo, para un conjunto de datos \(X_1, X_2,..., X_p\) la primera columna que está denotada por Comp.1 tiene los coeficientes \(\phi_{11}, \phi_{21},... ,\phi_{p1}\) de la combinación lineal con la que se obtiene la primera componente principal:
\[Z_1=\phi_{11}X_1+\phi_{21}X_2+... +\phi_{p1}X_p\]
Esta primera componente principal será la que refleje la mayor variabilidad de los datos.
##
## Loadings:
## Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 Comp.7 Comp.8
## i1 0.245 0.619 0.205 0.432 0.334 0.373 0.261
## i3 0.424 0.121 -0.255 -0.186 0.319 -0.771
## i4 0.375 -0.308 0.365 -0.210 -0.345 0.170 0.469 0.469
## i5 0.305 -0.452 0.399 0.590 0.167 -0.284 -0.286
## i6 0.337 -0.353 -0.368 -0.272 0.704 0.220
## i8 0.350 0.417 -0.278 0.102 -0.641 -0.231 0.389
## idh -0.356 0.717 -0.426 0.363 0.114 -0.170
## pobre 0.406 0.106 -0.152 -0.319 0.494 -0.668
##
## Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 Comp.7 Comp.8
## SS loadings 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000
## Proportion Var 0.125 0.125 0.125 0.125 0.125 0.125 0.125 0.125
## Cumulative Var 0.125 0.250 0.375 0.500 0.625 0.750 0.875 1.000En la primera fila de la instrucción summary tenemos la desviación estándar, para calcular la varianza debemos elevar al cuadrado cada una de las entradas.
## Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 Comp.7
## 5.11647369 1.38640826 0.45960969 0.38496619 0.29262794 0.21535488 0.11046942
## Comp.8
## 0.03408992Para obtener la proporción de la varianza que explica cada componente lo que tenemos que hacer es dividir el valor de la varianza de la componente \(j\) entre la suma de las varianzas de todas las componentes.
El siguiente código muestra como realizarlo. Además, en la instrucción summary vemos que estos valores coinciden con los de la segunda fila.
## Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 Comp.7
## 0.63955921 0.17330103 0.05745121 0.04812077 0.03657849 0.02691936 0.01380868
## Comp.8
## 0.00426124#si lo que queremos es el porcentaje, entonces solo hay que multiplicar por 100
porcentaje_varianza <- (cp1$sdev)^2*100/sum((cp1$sdev)^2)Para encontrar la proporción de varianza acumulada, lo que tenemos que hacer es dividir la suma de los primeros \(j-\)ésimos eigenvalores entre entre la suma de todos los eigenvalores.
La varianza de las Componentes Principales, es igual a los eigenvalores. Es decir, la desviación estándar de las componentes, es igual a la raiz de los valores propios.
## Comp.1 Comp.2 Comp.3 Comp.4 Comp.5 Comp.6 Comp.7 Comp.8
## TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUEPor otra parte, se puede afirmar que la traza de la matriz lambda es igual a la suma de la varianza de cada valor observado.
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
## [1,] 5.12 0.00 0.00 0.00 0.00 0.00 0.00 0.00
## [2,] 0.00 1.39 0.00 0.00 0.00 0.00 0.00 0.00
## [3,] 0.00 0.00 0.46 0.00 0.00 0.00 0.00 0.00
## [4,] 0.00 0.00 0.00 0.38 0.00 0.00 0.00 0.00
## [5,] 0.00 0.00 0.00 0.00 0.29 0.00 0.00 0.00
## [6,] 0.00 0.00 0.00 0.00 0.00 0.22 0.00 0.00
## [7,] 0.00 0.00 0.00 0.00 0.00 0.00 0.11 0.00
## [8,] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.03## [1] 8Además, el porcentaje de la varianza generalizada que es explicado por la componente \(j\)-ésima es igual a la relación que hay entre los eigenvalores divididos por la suma de la diagonal de eigenvalores (que la traza es igual a 8). Es decir, esto es igual al porcentaje de varianza acumulada por la función summary, y hecho a mano con la suma acumulada de los valores propios.
## [1] 0.6395592 0.8128602 0.8703115 0.9184322 0.9550107 0.9819301 0.9957388
## [8] 1.0000000Esta matriz es la diagonal con los eigenvalores.
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
## [1,] 5.12 0.00 0.00 0.00 0.00 0.00 0.00 0.00
## [2,] 0.00 1.39 0.00 0.00 0.00 0.00 0.00 0.00
## [3,] 0.00 0.00 0.46 0.00 0.00 0.00 0.00 0.00
## [4,] 0.00 0.00 0.00 0.38 0.00 0.00 0.00 0.00
## [5,] 0.00 0.00 0.00 0.00 0.29 0.00 0.00 0.00
## [6,] 0.00 0.00 0.00 0.00 0.00 0.22 0.00 0.00
## [7,] 0.00 0.00 0.00 0.00 0.00 0.00 0.11 0.00
## [8,] 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.03La traza de la matriz \(\Lambda\) es igual a la suma de las varianzas acumuladas por los Componentes.
## [1] 8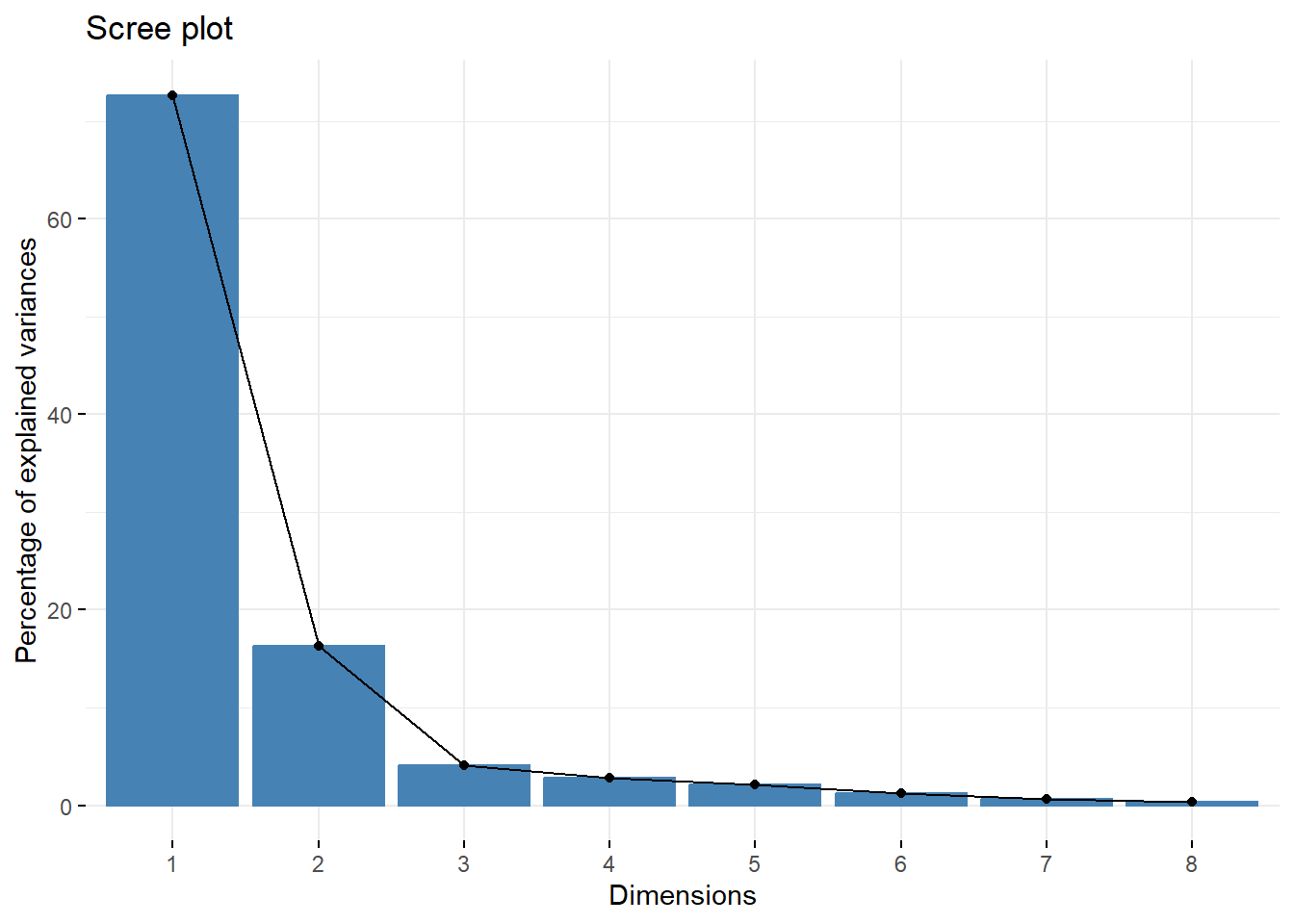
(#fig:grafico_codo_pca)Gráfico de codo
Recordemos que la regla de Kaiser consiste en tomar todas las componentes cuya varianza sea mayor a 1. Esto se debe a que si consideramos variables son independientes, entonces las componentes principales serán las mismas que las de las variables originales y para el caso de la matriz de correlación todas tendrán varianza 1. Entonces cualquier componente con varianza menor a 1 tiene menos información que las variables originales.
La librería nFactors tiene implementada la regla de Kaiser.
library(nFactors)
ev_cor <- eigen(cor.mat.aj)
ap <- parallel(subject=nrow(base.cp1),var=ncol(base.cp1),
rep=100,cent=.05)
num_cp <- nScree(x=ev_cor$values, aparallel=ap$eigen$qevpea, cor = TRUE)
num_cp## $Components
## noc naf nparallel nkaiser
## 1 2 1 2 2
##
## $Analysis
## Eigenvalues Prop Cumu Par.Analysis Pred.eig OC Acc.factor
## 1 5.11647369 0.63955921 0.6395592 1.63942593 1.6117947 NA
## 2 1.38640826 0.17330103 0.8128602 1.32588064 0.5447136 (< OC) 2.80326685
## 3 0.45960969 0.05745121 0.8703115 1.11025907 0.4726853 0.85215508
## 4 0.38496619 0.04812077 0.9184322 0.86210375 0.3788073 -0.01769474
## 5 0.29262794 0.03657849 0.9550107 0.67980927 0.3059874 0.01506518
## 6 0.21535488 0.02691936 0.9819301 0.52215947 0.1868489 -0.02761240
## 7 0.11046942 0.01380868 0.9957388 0.32235235 NA 0.02850596
## 8 0.03408992 0.00426124 1.0000000 0.03452362 NA NA
## AF
## 1 (< AF)
## 2
## 3
## 4
## 5
## 6
## 7
## 8
##
## $Model
## [1] "components"
##
## attr(,"class")
## [1] "nScree"Bajo la regla de Kaiser nos quedamos con 2 componentes unicamente.
fviz_pca_biplot(cp1, repel = TRUE, habillage=base2$region, gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07")
)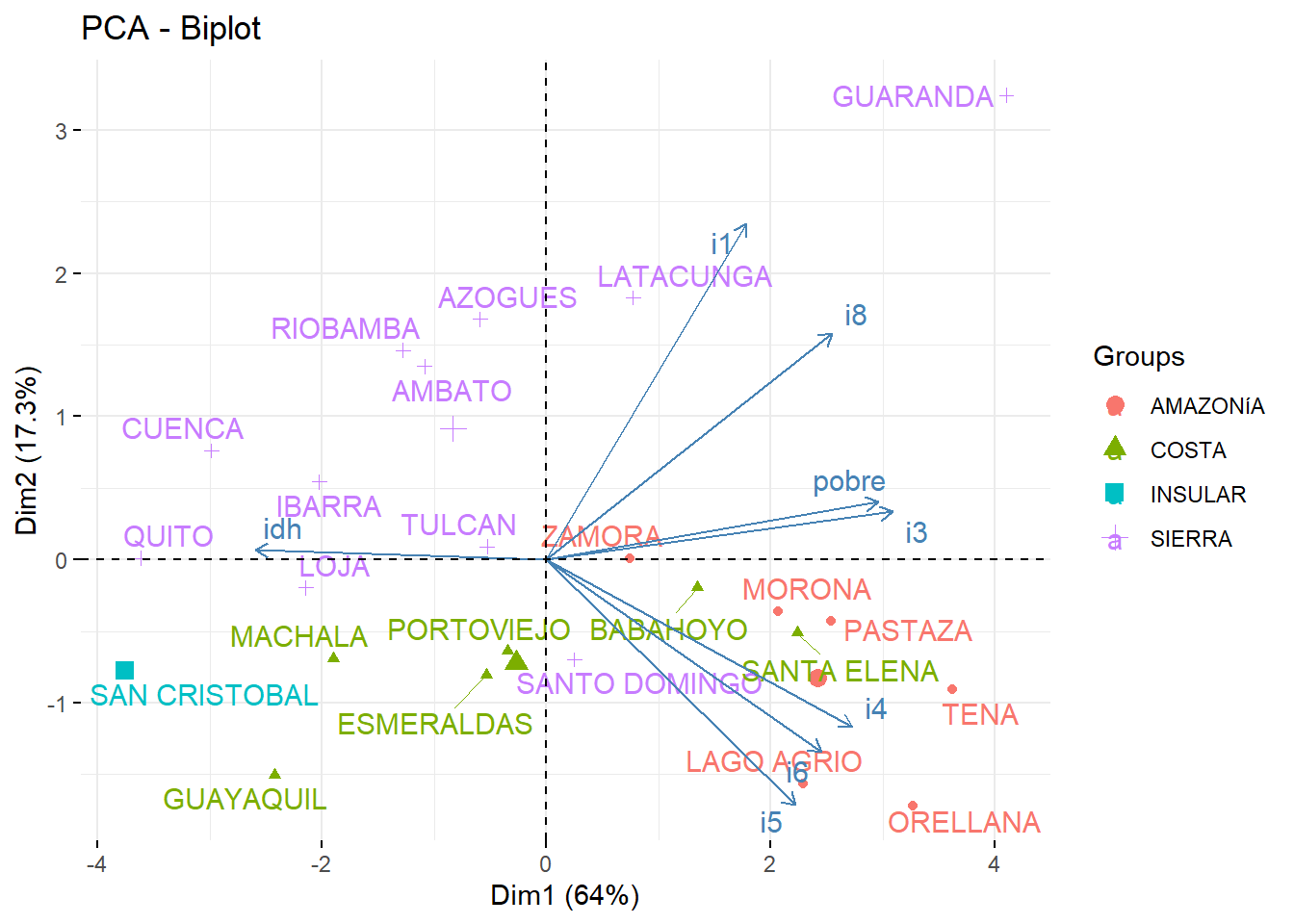
Figure 5.17: Biplot 1ra y 2da componente
fviz_pca_biplot(cp1, repel = TRUE,
habillage=base2$region,
addEllipses=TRUE,
ellipse.level=0.6,
col.var = "brown"
)## Too few points to calculate an ellipse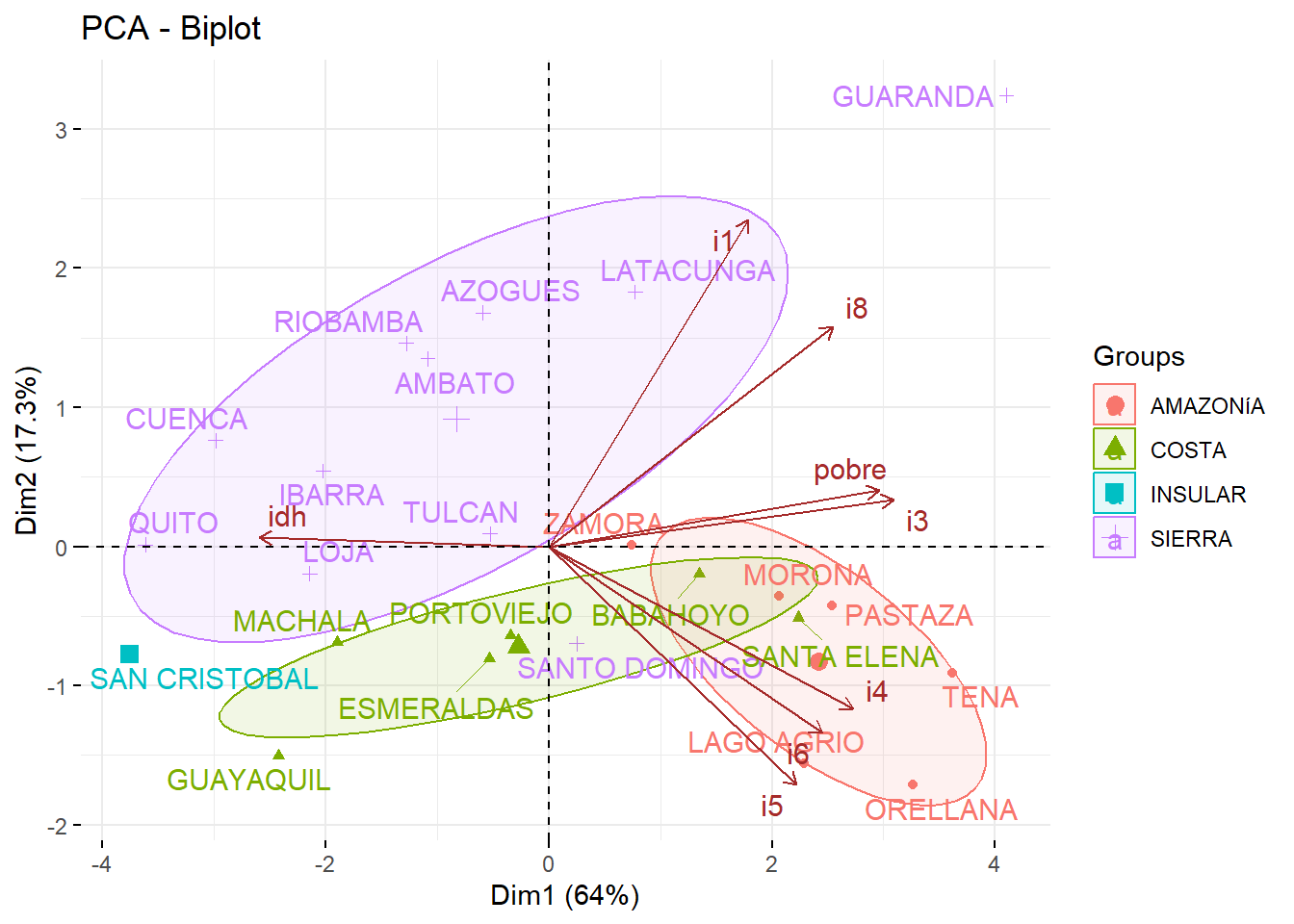
Figure 5.18: Biplot 1ra y 2da componente
Podemos observar en el biplot que todos los indicadores de pobreza apuntan al lado derecho, podríamos concluir que los municipios mas pobres serían Orellana, Tena y Guaranda, asi como el indice de desarrollo humano apunta hacia el lado izquierdo, dado que es un valor que en concepto es contrario a los indicadores de pobreza, en este sentido observamos que las ciudades menos pobres son: Quito, que es la capital. San Cristobal y Cuenca. Esta dristribución correlaciona con lo que se observará en los análisis de factores y clusters.
Podemos tambien obsrvar que las ciudades se agruparon en gran medida de acuerdo a la region a la que pertenecen, es decir si son parte de la region de la Amazonía, de la costa, la sierra o forman parte de la región insular.
Los indicadores i4 (%hogares sin energía eléctrica), i5 (%hogares sin servicio de agua entubada) e i6 (%hogares con algun nivel de hacinamiento), se puede observar que estar tres dimensiones apuntan hacia el cuarto cuadrante que es donde se agrupan las ciudades que se encuantran en la region de la Amazonía, una probable hipótesis, sería que las condiciones geográficas específicas de esta region encarecen o dificultan la construcción de infraestructura básica para poder otorgar servicios de electricidad, agua entubada y la construccion de vivienda.
Los indicadores i1 (% de poblacion de 15 años o mas analfabeta), i3 (% de ocupantes sin servicio de drenaje ni servicio sanitario), e i8 (porcentaje de poblacion coupada con 2 salarios mínimos o menos), estos indicadores apuntatan hacia el cuadrante 1 donde las ciudades ubicadas en esta direccion son predominantemente ciudades en la region de la sierra, lo cual podría sugerir como hipotesis que en esta region la infraestructura para escuelas o la disponibilidad de maestros sería menor a las otras regiones, en el caso del i3, la deficiencia hace referencia a la infraestructura de servicios basicos, y se encuantra muy cercana al cuadrante 4 junto con los otrs indicadores de carencias en cuaestion de viviendas. el indicador i8 que habla de la percepcion economica de las personas observamos que se encuentra en el cuadrante 1 y podriamos cuncluir que la ciudad de Guaranda es la de menor ingreso económico, aunque tambien es la que presenta una situación de pobreza mayor al resto de ciudades.
El indicador de Indice de Desarrollo Humano IDH como se mencionó anteriormente es un indicador contrario a los indicadores de pobreza antes mencionados, por eso no es de sorprendernos que apunte en dicreccion contraria, ademas es interesante observar que practicamente forma un vector horizontal al eje ordenado, podrias plantear como hipótesis que el IDH representa un buen parametro para medir la No pobreza de las ciudades analizadas.
5.6.2 Análisis de clústers
Vamos ahora a realizar el análisis de clústers. Este tipo de análisis nos permite encontar grupos dentro de un conjunto de observaciones. Estos grupos se forman de tal manera que las observaciones que quedan dentro de un mismo grupo tienen características similares entre si y diferentes a las de otros grupos.
Todos los métodos de clúster tienen en común que para poder realizar los grupos deben de definir lo que es que dos observaciones esten cerca o no. Para esto lo que se hace es definir una similitud o disimilitud entre las observaciones. En este caso, decidimos trabajar con la métrica euclidiana para obtener la matriz de distancias y así poder definir si dos ciudades estaban cerca o no de acuerdo a las variables estudiadas. Para calcular la matriz de distancias usamos la función dist del paquete stats.
En el gráfico siguiente podemos visualizar la matriz de distancias y podemos empezar a darnos cuenta que si se forman ciertos grupos. Las intensidades azules indican que la disimilitud entre las ciudades es alta y las intensidades rojas que la disimilitud es baja.
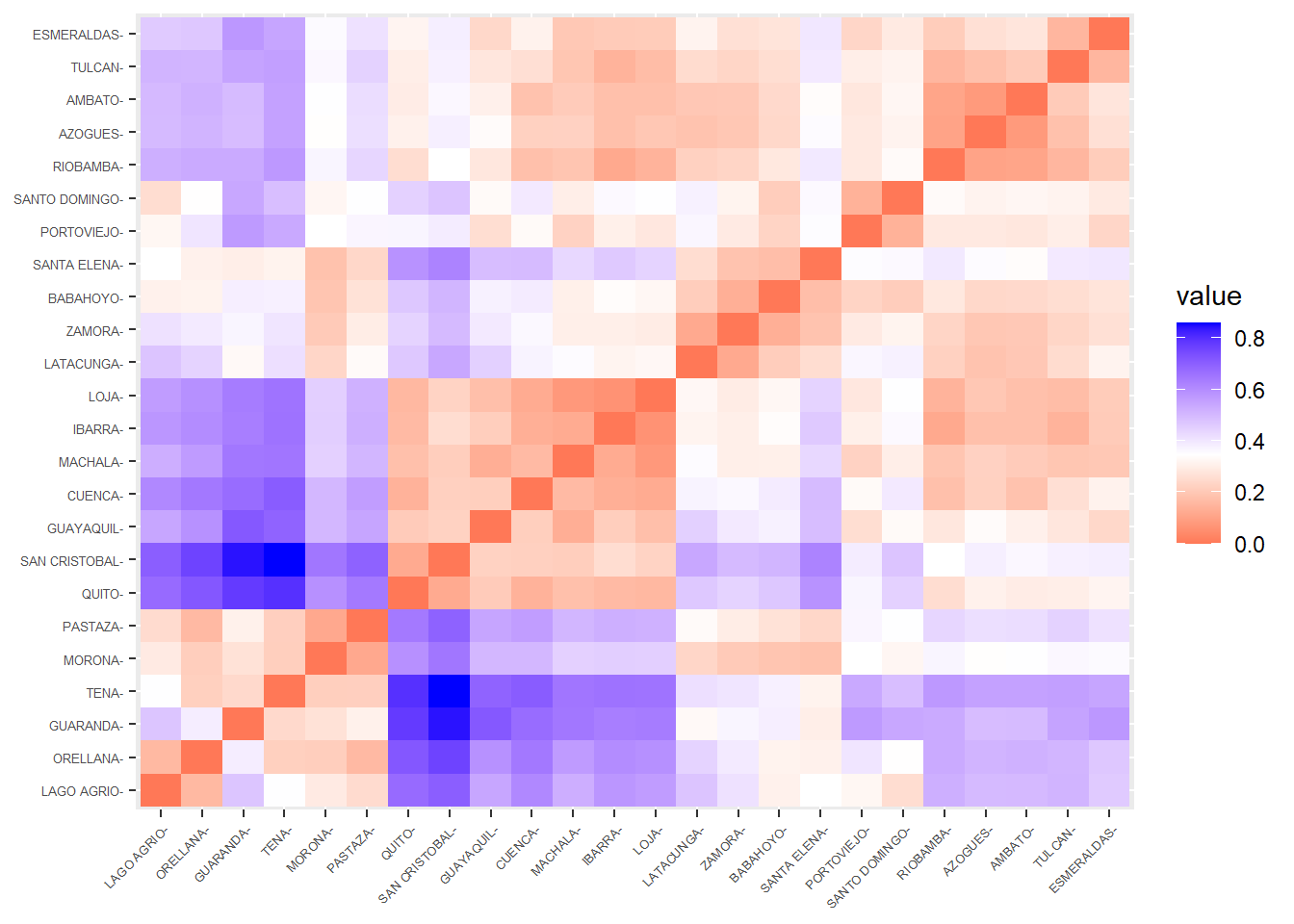
(#fig:visualizar_matriz)Heatmap de la matriz de distancias
Ahora, vamos a generar los clústers con diferentes métodos para analizar cual es el más conveniente en este caso.
set.seed(12345)
hc_single <- hclust(d=mat_dist, method = "single")
hc_average <- hclust(d=mat_dist, method = "average")
hc_complete <- hclust(d=mat_dist, method = "complete")
hc_ward <- hclust(d=mat_dist, method = "ward.D2")
hc_median <- hclust(d=mat_dist, method = "median")
hc_centroid <- hclust(d=mat_dist, method = "centroid")Procedemos a graficar sus respectivos dendrogramas.
fviz_dend(x = hc_average,
cex = 0.4,
main = "",
xlab = "Municipios",
ylab = "Distancia",
sub = "",
horiz = TRUE)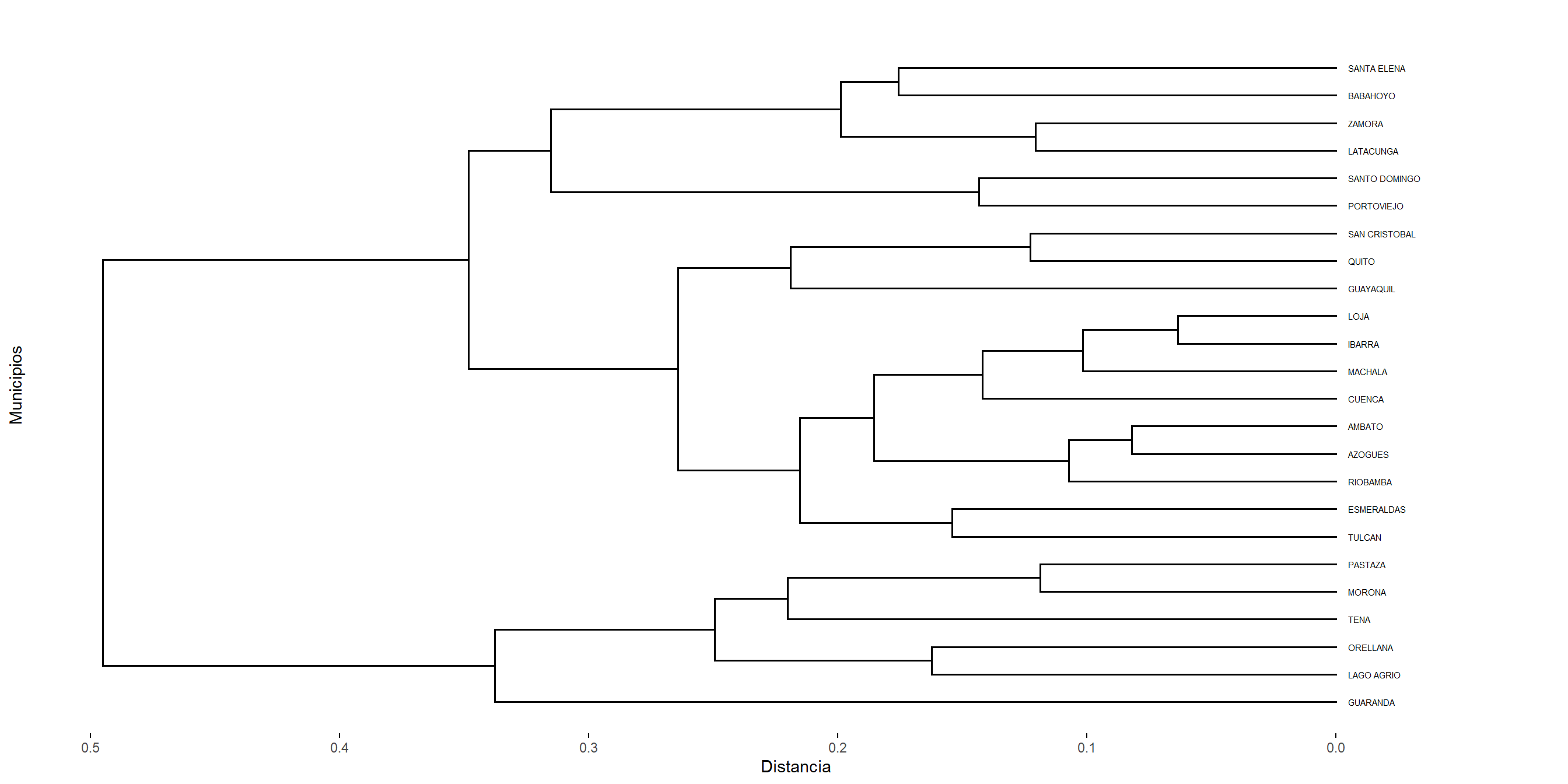
(#fig:dendograma_average)Dendrograma usando el método de Promedio
fviz_dend(x = hc_ward,
cex = 0.3,
main = "",
xlab = "Municipios",
ylab = "Distancia",
sub = "",
horiz = TRUE)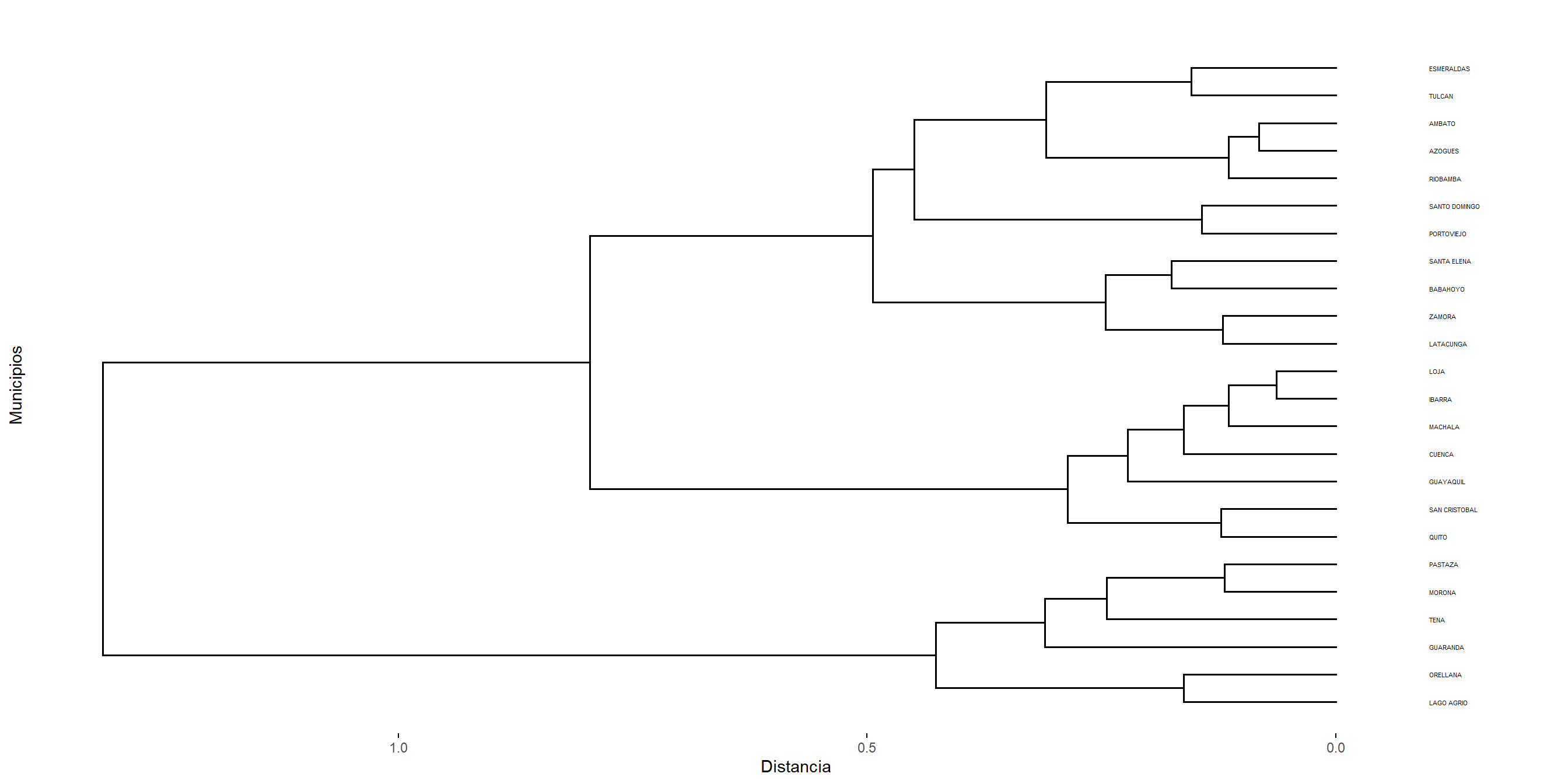
(#fig:dendograma_Ward)Dendrograma usando el método de Ward
fviz_dend(x = hc_single,
cex = 0.4,
main = "",
xlab = "Municipios",
ylab = "Distancia",
sub = "",
horiz = TRUE)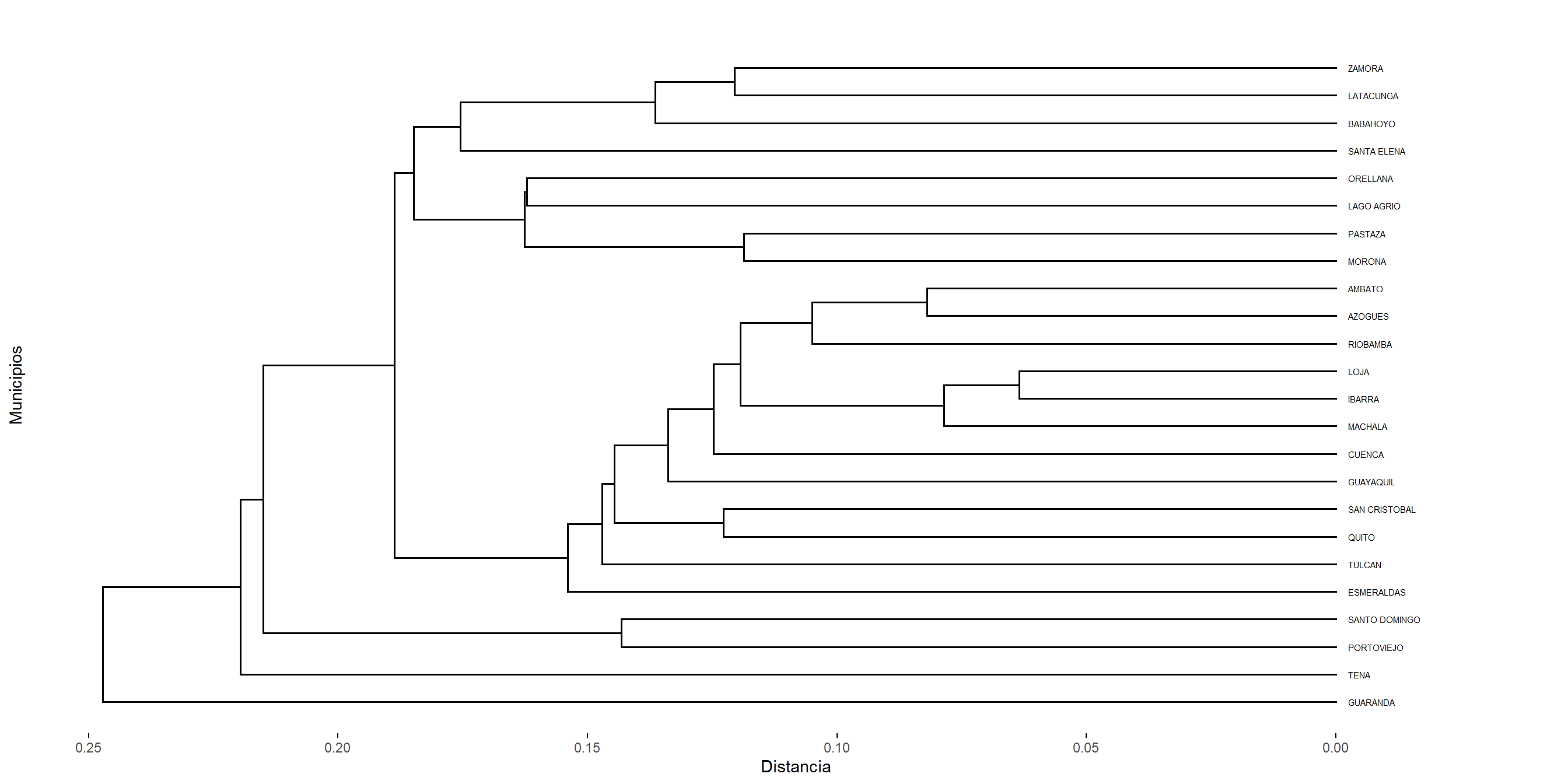
(#fig:dendograma_single)Dendrograma usando el método del vecino más cercano
fviz_dend(x = hc_complete,
cex = 0.4,
main = "",
xlab = "Municipios",
ylab = "Distancia",
sub = "",horiz = TRUE)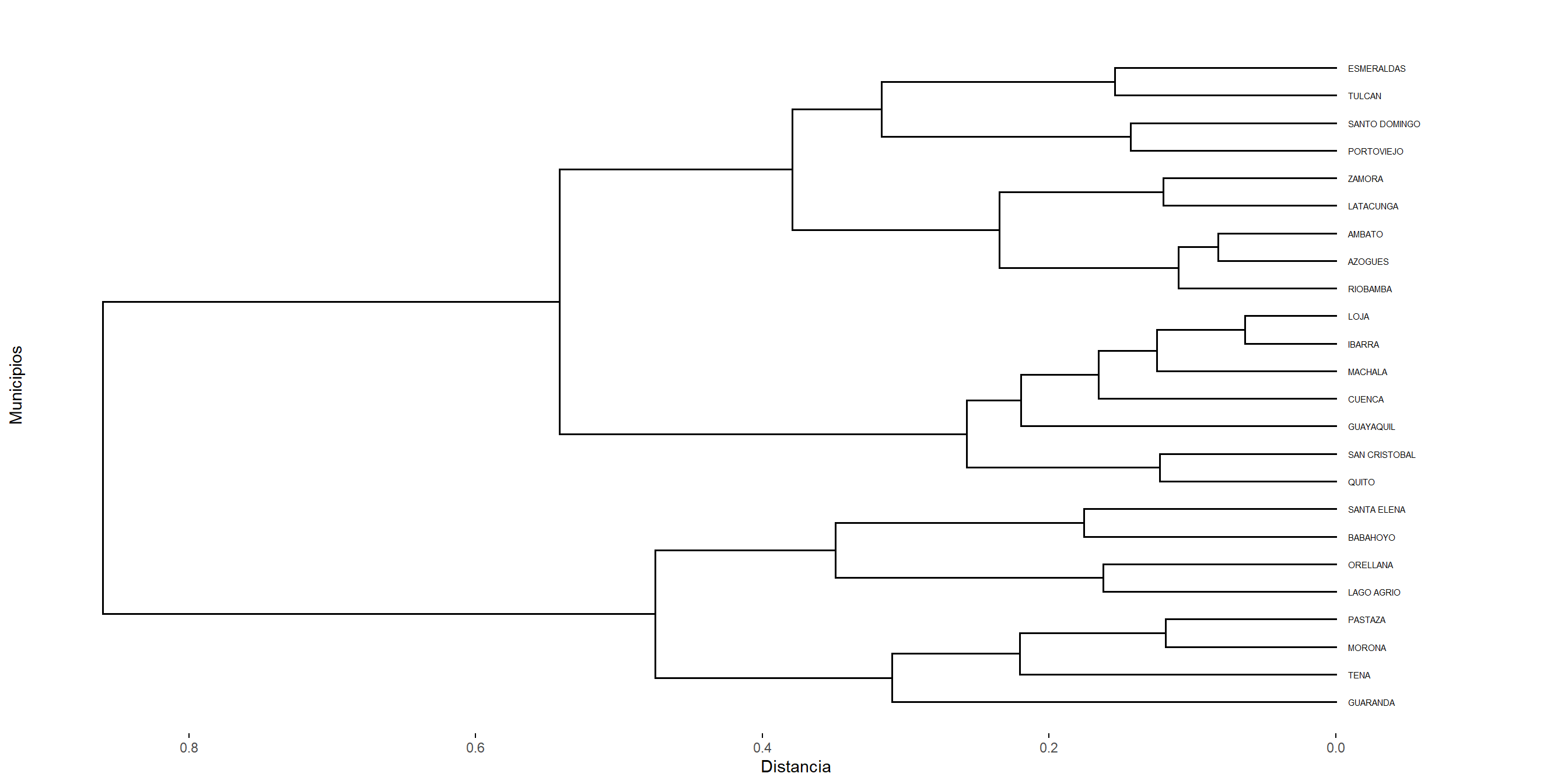
(#fig:dendograma_complete)Dendrograma usando el método de complete
fviz_dend(x = hc_median,
cex = 0.4,
main = "",
xlab = "Municipios",
ylab = "Distancia",
sub = "",horiz = TRUE)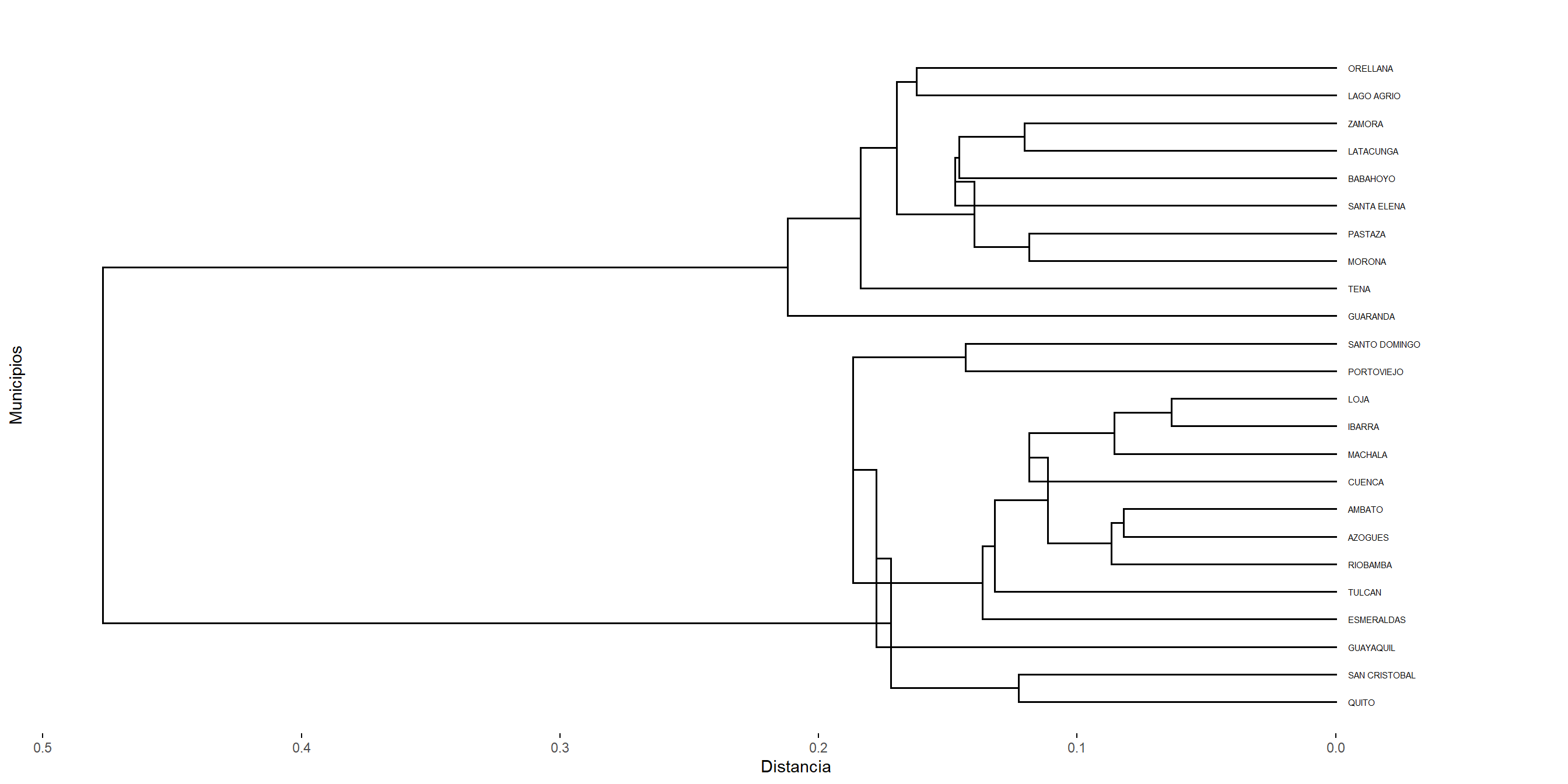
(#fig:dendograma_median)Dendrograma usando el método de mediana
fviz_dend(x = hc_centroid,
cex = 0.4,
main = "",
xlab = "Municipios",
ylab = "Distancia",
sub = "",horiz = TRUE)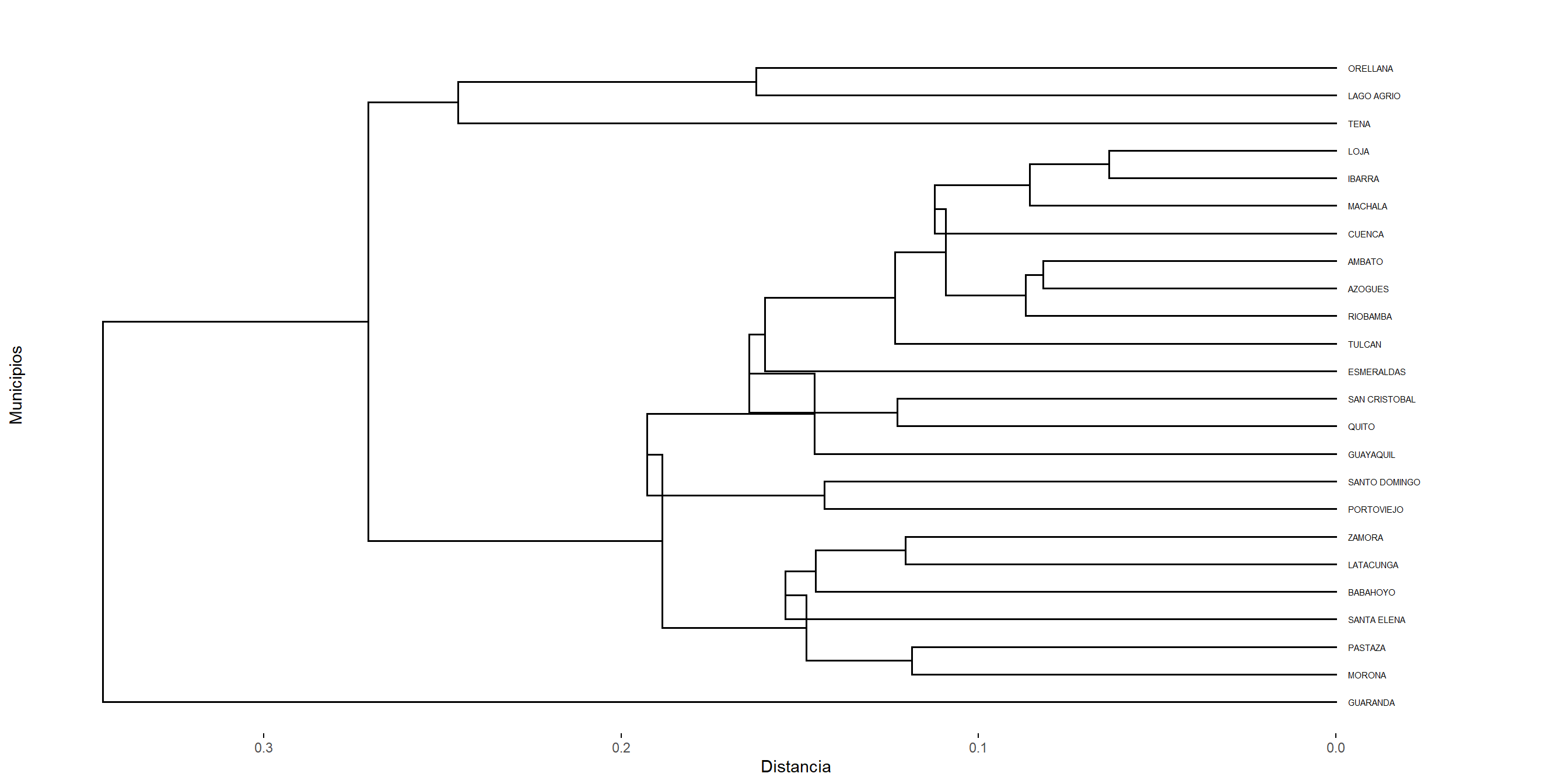
(#fig:dendograma_centroide)Dendrograma usando el método del centroide
Después de analizar los distintos dendrogramas para las diferentes ligas, en los que se aprecian mejor los grupos son los métodos de ward y average. Para evaluar cual dendrograma reflejaba mejor las distancias originales entre las observaciones, calculamos el coeficiente de correlación entre las distancias cofenéticas del dendrograma y la matriz de distancias originales, esta información está en el cuadro siguiente. Entre más cercano este el coeficiente de correlación a 1 nos indica que el dendrograma refleja mejor las distancias originales.
library(kableExtra)
library(purrr)
# vector con nombre de los métodos
m <- c( "average", "single", "complete", "ward.D2", "median", "centroid")
names(m) <- c( "average", "single", "complete", "ward.D2", "median", "centroid")
# Función para calcular el coeficiente de correlación
coef_cor <- function(x) {
cor(x=mat_dist, cophenetic(hclust(d=mat_dist, method = x)))
}
# Tabla comparativa
coef_tabla <- map_dbl(m, coef_cor)
kbl(coef_tabla, booktabs = TRUE, align = "c",
caption = "Cuadro comparativo de los coeficientes de correlación",
col.names = rownames(coef_tabla)) %>%
kable_styling(position = "center",
latex_options = c("repeat_header", "hold_position"),
font_size = 9) %>%
add_header_above(c("Método", "Coeficiente de correlación"))| average | 0.7455171 |
| single | 0.5854219 |
| complete | 0.7032896 |
| ward.D2 | 0.7108765 |
| median | 0.6755044 |
| centroid | 0.6571929 |
Podemos observar que el dendrograma que mejor refleja la similitud entre las observaciones es la del método average y el segundo mejor es el del método ward. Decidimos usar el dendrograma de Ward ya que es en el que se visualizan mejor los grupos que se forman.
Para determinar cuantos grupos nos conviene más tomar, usamos dos métodos: el método del codo y el paquete NbClust. Este paquete usa 30 índices para determinar el número más relevante de clústers variando todas las combinaciones de número de clústers, distancias y métodos.
fviz_nbclust(x = base.cp1, FUNcluster = hcut, method = "wss", diss = mat_dist, k.max = 7) +
labs(title = "Número óptimo de clusters")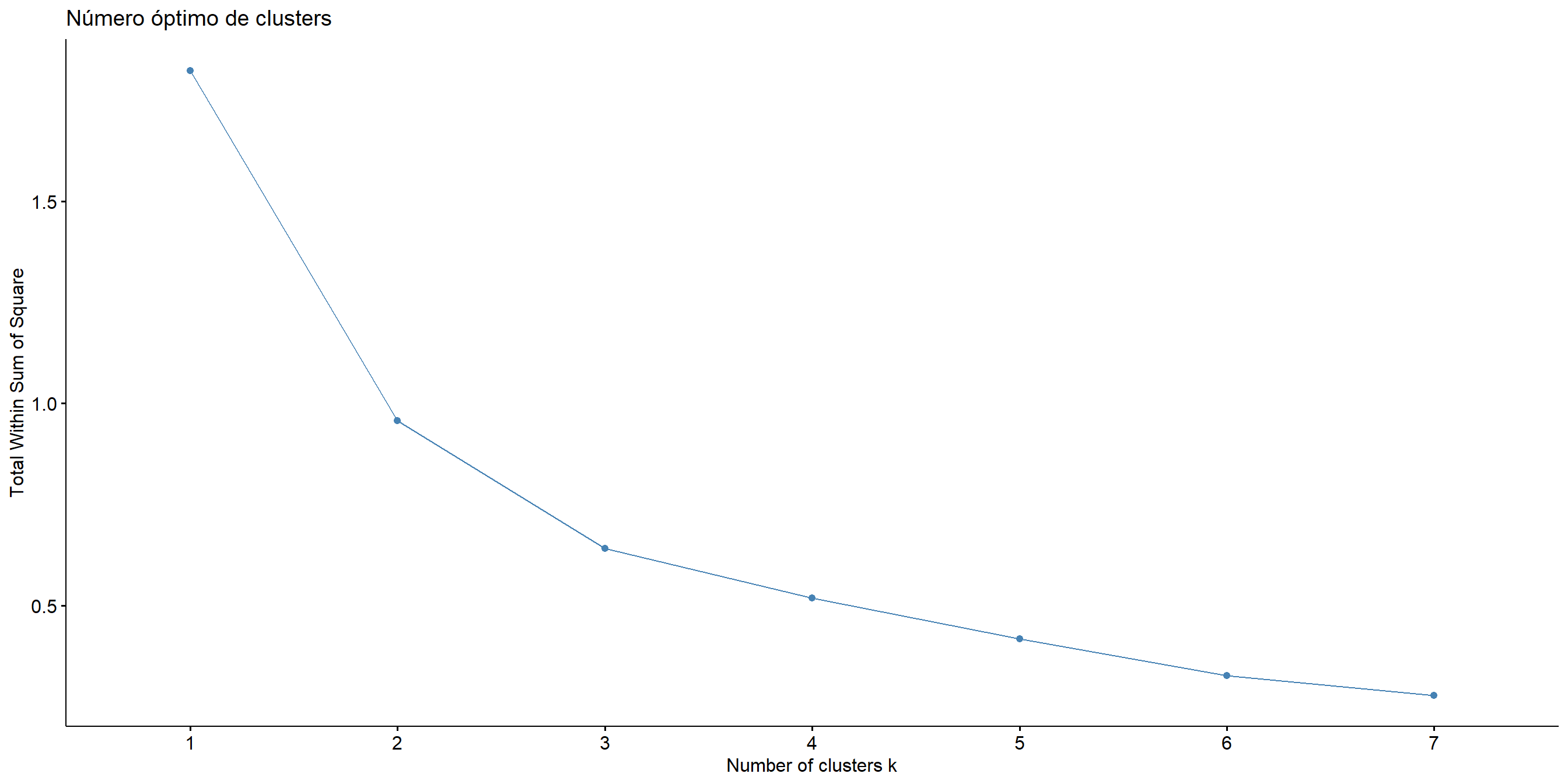
(#fig:num_clusters_codo)Número óbtimo de clusters usando el método del codo
Podemos observar en la gráfica de codo que en 3 es donde se forma el codo, así que esto nos diría que debemos considerar 3 clústers.
Usando el paquete ‘NbClust’ obtenemos los siguientes resultados. En la última gráfica de barras que se muestra es claro que deberíamos tomar 3 clústers.
library(NbClust)
basef_scaled <- scale(base.cp1)
res.nbclust <- NbClust(basef_scaled, distance = "euclidean",
min.nc = 2, max.nc = 9,
method = "ward.D2", index ="all")
(#fig:num_clusters_NbClust-1)Número óbtimo de clusters usando el paquete NbClust
## *** : The Hubert index is a graphical method of determining the number of clusters.
## In the plot of Hubert index, we seek a significant knee that corresponds to a
## significant increase of the value of the measure i.e the significant peak in Hubert
## index second differences plot.
## 
(#fig:num_clusters_NbClust-2)Número óbtimo de clusters usando el paquete NbClust
## *** : The D index is a graphical method of determining the number of clusters.
## In the plot of D index, we seek a significant knee (the significant peak in Dindex
## second differences plot) that corresponds to a significant increase of the value of
## the measure.
##
## *******************************************************************
## * Among all indices:
## * 6 proposed 2 as the best number of clusters
## * 8 proposed 3 as the best number of clusters
## * 2 proposed 4 as the best number of clusters
## * 5 proposed 6 as the best number of clusters
## * 1 proposed 8 as the best number of clusters
## * 2 proposed 9 as the best number of clusters
##
## ***** Conclusion *****
##
## * According to the majority rule, the best number of clusters is 3
##
##
## *******************************************************************best <- as.data.frame(res.nbclust$Best.nc)
clusters <- as.numeric(best["Number_clusters", ])
freq <- as.data.frame(table(clusters))
colnames(freq) <- c("clusters", "freq")
ggplot(freq, aes(x = clusters, y = freq)) +
geom_col(fill = "#2E9FDF") +
theme_minimal() +
labs(
x = "Número de clusters",
y = "Frecuencia como óptimo",
title = "Número óptimo de clusters según índices de NbClust"
)
(#fig:num_clusters_NbClust-3)Número óbtimo de clusters usando el paquete NbClust
Entonces, el mejor número de cluster que podemos tomar es 3. Vamos a proceder a encontrar el punto de corte del dendrograma y a identificar los grupos.
El valor de \(y\) al cual tomaremos el corte se obtiene como el promedio de las alturas obtenidas entre el grupo \(3\) y el grupo \(4\).
## [1] 0.56695Por lo tanto, el corte debe realizarse al nivel \(y =\) 0.56695. En el dendograma pueden identificarse los grupos que se forman al realizar dicho corte.
fviz_dend(x = hc_ward,
k = 3,
k_colors = c("#DE3A17", "#00AFBB", "#1131E7"),
color_labels_by_k = TRUE,
rect_border = c("#2E9FDF", "#00AFBB", "#E7B800", "#FC4E07"),
cex = 0.4,
xlab = "Municipios",
ylab = "Distancia",
sub = "", horiz = TRUE) +
geom_hline(yintercept = y, linetype = "dashed") +
labs(title = "Dendrograma",
subtitle = "Método de Ward, k = 3"
)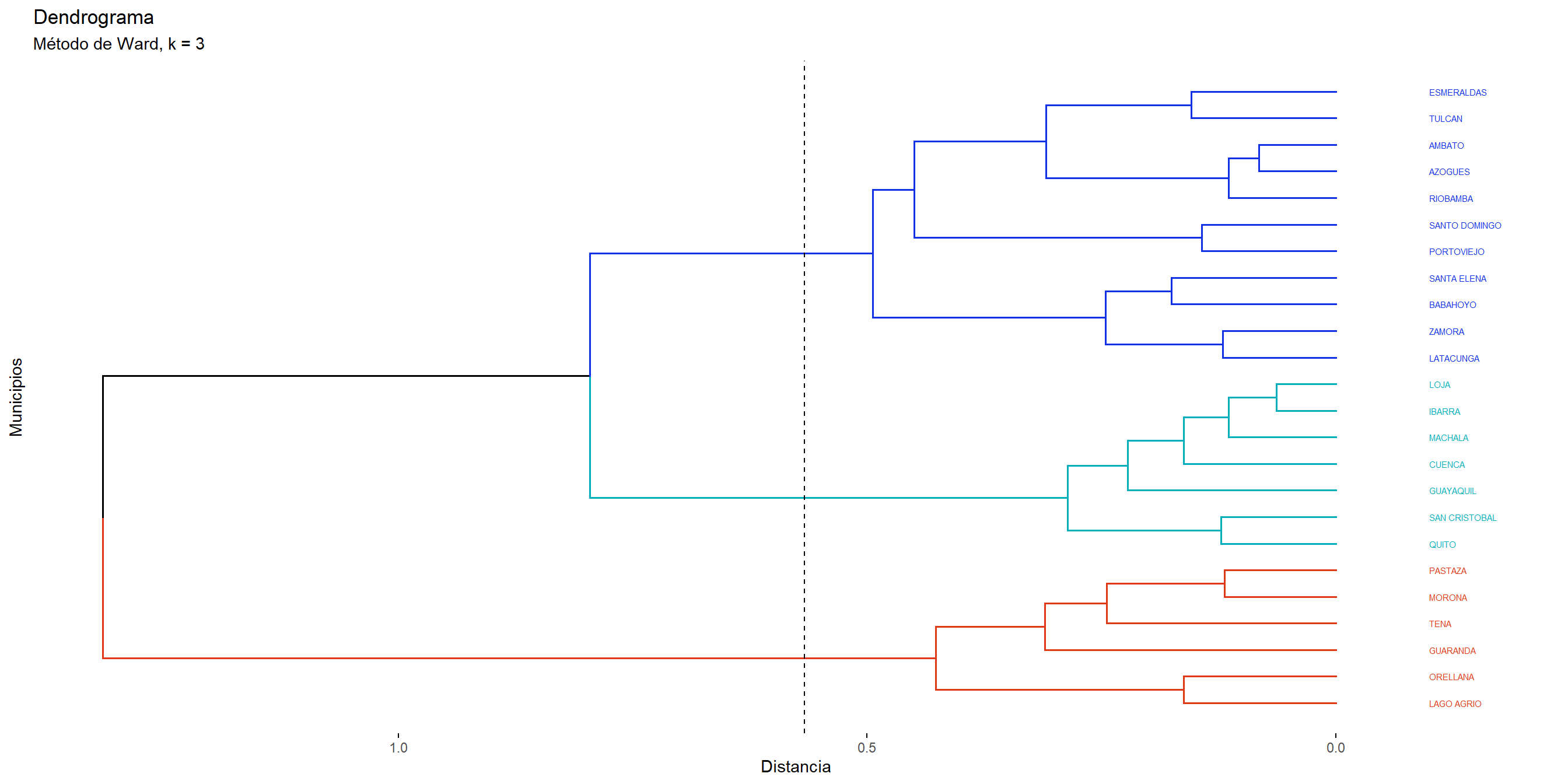
(#fig:grupos_dendograma)Dendrograma con 3 grupos
Podemos visualizar también estos grupos al hacer PCA y observamos en la figura siguiente.
fviz_cluster(object = list(data=base.cp1, cluster=cutree(hc_ward, k=3)),
ellipse.type = "convex", repel = TRUE, show.clust.cent = FALSE,
labelsize = 8) +
labs(title = "Clustering jerárquicos + Proyección PCA",
subtitle = "Distancia euclídea, Método Ward, K=3") +
theme_bw() +
theme(legend.position = "bottom")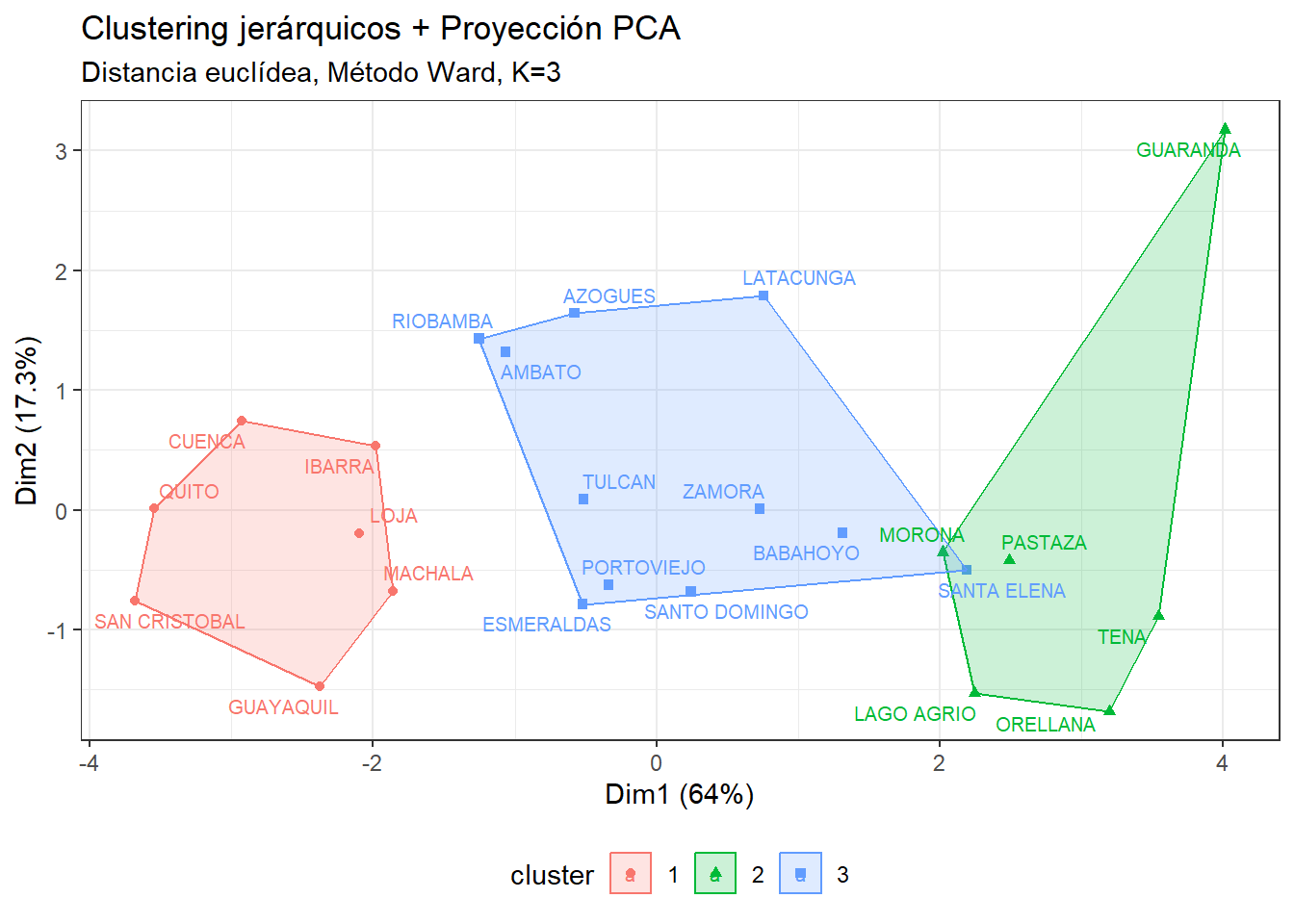
Figure 5.19: Grupos y PCA
Guardamos el corte realizado para obtener de manera explícita los grupos y poder presentarlos en la siguiente tabla.
## CUENCA MACHALA GUAYAQUIL IBARRA LOJA
## 1 1 1 1 1
## QUITO SAN CRISTOBAL GUARANDA MORONA TENA
## 1 1 2 2 2
## PASTAZA LAGO AGRIO ORELLANA AZOGUES TULCAN
## 2 2 2 3 3
## LATACUNGA RIOBAMBA ESMERALDAS BABAHOYO PORTOVIEJO
## 3 3 3 3 3
## AMBATO ZAMORA SANTO DOMINGO SANTA ELENA
## 3 3 3 3Lo que podemos notar al realizar los grupos es que si quedan agrupados con respecto a su bienestar general, en el grupo 1 están los grupos de mayor bienestar/riqueza, en el grupo 2 los de riqueza intermedia y en el grupo 3 los más pobres o de menor bienestar.
Podemos concluir que existen agrupaciones naturales respecto al bienestar, los municipios con mayor bienestar se encuentran en la sierra y unos pocos en la costa mientras los de menor bienestar en la Amazonía.
Pendiente: Análisis de factores y análisis de discriminante en este mismo set de datos.
5.7 Tutoriales de DataCamp sugeridos
Otro material sugerido: BiotrAIn course: Concepts, approaches and applications of Artificial Intelligence in bioscience
Otros tutoriales: - https://rpubs.com/Dariel1102/1046632,