Sección 4 Análisis Factorial
El objetivo esencial del análisis de factores es describir las relaciones de covarianza entre muchas variables mediante unas pocas variables latentes no observables, llamadas factores. La idea central es:
Si un conjunto de variables presenta correlaciones altas entre sí, pero bajas con otras variables, es posible que ese grupo comparta una causa común subyacente.
Ese patrón puede interpretarse como la presencia de un factor responsable de las correlaciones dentro del grupo.
Las variables consideradas tienen una escala de medición continua. \[X^\top = (X_1, \dots, X_p)\]
La correlación \(r_{ij}\) entre dos variables \(X_i\) y \(X_j\) se debe a que ambas tienen una relación con una tercera variable \(Z_k\) que se considera no observable.
El coeficiente de correlación parcial \(r_{ij.k}\) mide la asociación que hay entre \(X_i\) y \(X_j\) luego de remover el efecto que tiene \(Z_k\) en cada una.
Si \(r_{ij.k} \approx 0\), se puede pensar que \(Z_k\) ha explicado la correlación existente entre \(X_i\) y \(X_j\).
-De manera más general, pueden considerarse varias variables \(Z_1, \dots, Z_m\) para explicar la asociación que existe entre \(X_i\) y \(X_j\).
La idea en análisis de factores es:
Explicar las correlaciones contenidas en la matriz \[R = [r_{ij}]\] a través de un conjunto de variables no observables \(f_1, \dots, f_m\), llamadas factores comunes.
Buscar que las correlaciones parciales \(r_{ij.{f_1,\dots,f_m}}\) sean muy pequeñas:
- Es decir, que las correlaciones entre las variables se deban a esas \(f_i\).
Además, se desea que el número de factores comunes \(m\) sea pequeño.
Un ejemplo clásico es el de Spearman, cuyas correlaciones entre calificaciones de materias como latín, francés, inglés, matemáticas y música sugerían un factor de “inteligencia”. Otro grupo de variables, como pruebas físicas, podría reflejar un factor de condición física.
El análisis de factores busca precisamente confirmar este tipo de estructura, en la cual grupos de variables se explican por factores subyacentes.
Otro ejemplo: Las variables en los rectángulos están correlacionadas entre sí, debido a que detrás están las variables latentes (no observables) que aparecen en los óvalos.
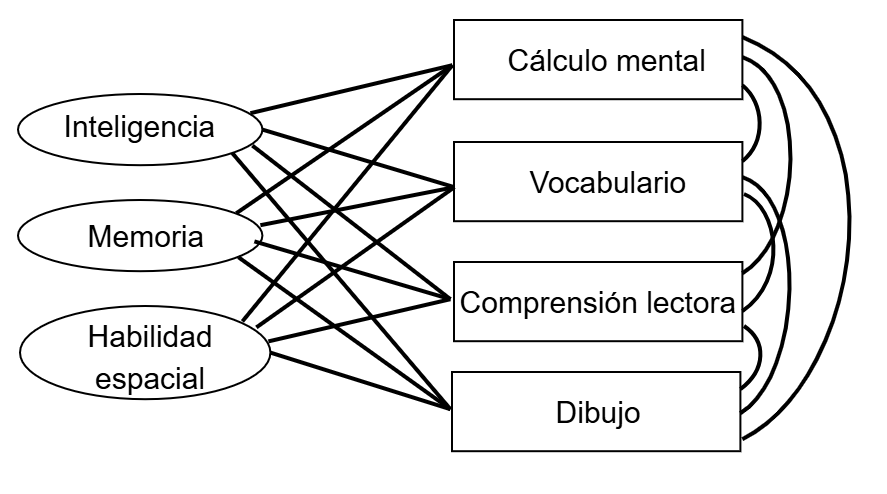
Aunque el análisis de factores está relacionado con el análisis de componentes principales (PCA) y ambos intentan aproximar la matriz de covarianzas, el enfoque de factores es más complejo: no solo reduce dimensiones, sino que intenta comprobar si los datos son consistentes con un modelo estructural prescrito.
4.1 Modelo de factores ortogonales con \(m\) factores comunes
El vector aleatorio observable \(X\), con \(p\) componentes, tiene media \(\mu\) y matriz de covarianzas \(\Sigma\). El modelo de factores quiere explicar las relaciones entre las variables manifiestas \(X=(X_1, \dots, X_p)\) a través de \(m\) variables latentes \(f_1, \dots, f_m\), llamadas factores comunes y \(p\) fuentes adicionales de variación \(e_1,...,e_p\) llamados errores o factores específicos:
\[ X_j = \mu_j + \ell_{j1} f_1 + \dots + \ell_{jm} f_m + e_j, \quad j = 1, \dots, p. \]
\(\mu_j\) y \(\ell_{ji}\) son constantes.
Los \(\ell_{ji}\) se llaman también las cargas (loadings) de la j-ésima variable en el factor i-ésimo.
\(e_j\) y los \(f_i\) son variables aleatorias.
A los \(e_j\) se les llama factores específicos.
Se considera que:
los \(e_j\) no están correlacionados entre sí;
los \(e_j\) son no correlacionados con los \(f_i\).
En forma matricial, el modelo se escribe como:
\[ X = \mu_{p\times 1} + L_{p\times m} F_{m\times 1} + e_{p\times 1}, \]
o, centrando la variable,
\[ X - \mu = L F + e, \]
donde:
\(X = (X_1, \dots, X_p)^\top\),
\(e^\top = (e_1, \dots, e_p)\),
\(F^\top = (f_1, \dots, f_m)\),
\(L\) es una matriz de constantes:
\[ L = \begin{pmatrix} \ell_{11} & \cdots & \ell_{1m} \\ \vdots & & \vdots \\ \ell_{p1} & \cdots & \ell_{pm} \end{pmatrix}. \]
Se supone que \(\mathbb{E}(e) = 0\) y \(\mathbb{E}(F) = 0\).
La matriz de varianzas y covarianzas de los factores específicos se denota por:
\[ \operatorname{cov}(e) = \Psi. \]
Como los \(e_j\) son no correlacionados entre sí, \(\Psi\) es diagonal:
\[ \Psi = \begin{pmatrix} \psi_1^2 & 0 & \cdots & 0 \\ 0 & \psi_2^2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \psi_p^2 \end{pmatrix}. \]
Supongamos que la matriz de varianzas y covarianzas de \(F\) es \(\Gamma\). Si \(\Gamma\) no es diagonal (i.e., las entradas son correlacionadas), como es simétrica y semidefinida positiva, puede escribirse como:
\[ \Gamma = TT^\top. \]
Sea ahora el vector
\[ F^* = T^\top F \]
Entonces:
\(\mathbb{E}(F^*) = T^{\top} \mathbb{E}(F) = 0\),
\(\operatorname{var}(F^*) = T^{\top} \Gamma T = T^\top T = I\).
Es decir, \(F^*\) tiene entradas no correlacionadas.
Además,
- \(\operatorname{cov}(e, F) = \mathbb{E}(eF^\top) = 0_{p\times m}\).
Si definimos \(L^* = L T\), se tiene:
\[ L^* F^* = L T T^\top F = L F. \]
Sustituyendo en el modelo:
\[ X = \mu + L^* F^* + e = \mu + L^* TT^{\top}F + e = \mu + L F + e. \]
El modelo con factores no correlacionados \(F^*\) es indistinguible del modelo original con factores correlacionados \(F\). Por sencillez, se consideran los factores comunes como no correlacionados.
Para ver las varianzas de las variables originales, partimos de:
\[ X_j = \mu_j + \ell_{j1} f_1 + \dots + \ell_{jm} f_m + e_j. \]
Como factores comunes y específicos son no correlacionados, al calcular la varianza:
\[ \operatorname{var}(X_j) = \sum_{k=1}^m \ell_{jk}^2 \;\;+\;\; \operatorname{var}(e_j) = \underbrace{\sum_{k=1}^m \ell_{jk}^2}_{\text{comunalidad}} + \underbrace{\psi_j^2}_{\text{especificidad}}. \]
Las covarianzas entre variables quedan:
\[ \operatorname{cov}(X_i, X_j) = \sum_{k=1}^m \ell_{ik} \ell_{jk}. \]
En forma matricial, la matriz de varianzas y covarianzas de \(X\) se escribe como:
\[ \Sigma = LL^\top + \Psi. \]
Al calcular la covarianza entre los factores comunes y las variables originales se tiene:
\[ \operatorname{cov}(X, F) = \mathbb{E}\big[(L F + e) F^\top\big] = L \mathbb{E}(FF^\top) + \mathbb{E}(eF^\top) = L, \]
porque \(\mathbb{E}(FF^\top) = I\) y \(\mathbb{E}(eF^\top) = 0\).
Por tanto, las cargas \(\ell_{ij}\) pueden interpretarse como la covarianza entre la variable original \(X_i\) y el factor \(f_j\).
Diferencias entre Análisis de Componentes Principales (PCA) y Análisis de Factores (AF)
- El análisis de factores busca explicar las varianzas y covarianzas (y correlaciones).
- El análisis de componentes principales se enfoca en buscar direcciones de máxima varianza.
- En PCA hay tantas componentes como variables originales.
- En AF se fija de antemano el número de factores comunes \(m\), con \(m < p\).
- En AF hay varios métodos para calcular las cargas.
- En PCA las cargas se obtienen a través de eigenvalores y eigenvectores (direcciones de máxima varianza).
En AF, las cargas \(\ell_{ij}\) se pueden calcular por tres métodos principales:
- Extracción inicial de factores: factores principales.
- Factores principales iterados.
- Factores por máxima verosimilitud.
Ejemplo: Verificar que \(\Sigma= LL^\top+\Psi\).
Consideremos la matriz de covarianzas
\[ \Sigma = \begin{pmatrix} 19 & 30 & 2 & 12 \\ 30 & 57 & 5 & 23 \\ 2 & 5 & 38 & 47 \\ 12 & 23 & 47 & 68 \end{pmatrix} \]
Queremos verificar que esta matriz puede escribirse como:
\[\Sigma= LL^\top+\Psi\]
para un modelo factorial ortogonal con \(m=2\) factores.
Vamos a considerar las siguientes matrices de cargas \(L\) y de varianzas específicas \(\Psi\):
\[ L = \begin{pmatrix} 4 & 1 \\ 7 & 2 \\ -1 & 6 \\ 1 & 8 \end{pmatrix} \]
y
\[ \Psi = \begin{pmatrix} 2 & 0 & 0 & 0 \\ 0 & 4 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 3 \end{pmatrix} \]
# Definir matrices
Sigma <- matrix(c(19,30,2,12,
30,57,5,23,
2,5,38,47,
12,23,47,68),
nrow = 4, byrow = TRUE)
# Matriz Lambda
L <- matrix(c(4,1,
7,2,
-1,6,
1,8),
nrow = 4, byrow = TRUE)
Psi <- diag(c(2,4,1,3)) # matriz diagonal
# Queremos verificar Sigma = L L' + Psi
LLt_plus_Psi <- L %*% t(L) + Psi
Sigma## [,1] [,2] [,3] [,4]
## [1,] 19 30 2 12
## [2,] 30 57 5 23
## [3,] 2 5 38 47
## [4,] 12 23 47 68## [,1] [,2] [,3] [,4]
## [1,] 19 30 2 12
## [2,] 30 57 5 23
## [3,] 2 5 38 47
## [4,] 12 23 47 68## [1] TRUECálculo de la comunalidad de \(X_1\):
\[h_1^2 = \ell_{11}^2 + \ell_{12}^2 = 4^2 + 1^2 = 17\]
En R:
## [1] 17Descomposición de la varianza de \(X_1\):
\[\sigma_{11} = (\ell_{11}^2 + \ell_{12}^2) + \psi_1 = h_{1}^2 + \psi_1 \]
\[ \underbrace{19}_{\text{varianza}} \;=\; \underbrace{4^2 + 1^2}_{\text{comunalidad}} \;+\; \underbrace{2}_{\text{varianza específica}} \;=\; 17 + 2 \]
Este ejemplo muestra que:
\[\Sigma= LL^\top+\Psi\]
sí representa un modelo factorial ortogonal con 2 factores, pues toda la matriz \(\Sigma\) puede reconstruirse exactamente usando:
las cargas factoriales en \(L\),
las varianzas específicas en \(\Psi\).
4.2 Métodos de estimación
¿Cuándo es útil el Análisis Factorial?
El objetivo del análisis factorial es determinar si un conjunto de \(p\) variables puede explicarse adecuadamente mediante unos pocos factores comunes.
Para evaluar esta idea, se compara la matriz de covarianzas muestral con la estructura propuesta por el modelo factorial.
Si las correlaciones entre variables son muy pequeñas, no vale la pena hacer un análisis factorial, porque no existen factores comunes fuertes; dominan los factores específicos.
Si la matriz de covarianzas no parece diagonal, entonces es razonable intentar un modelo factorial.
El paso central es estimar las cargas factoriales \(\ell_{ij}\) y las varianzas específicas \(\psi_i\).
Los métodos de estimación más usados son:
Componentes principales / factores principales,
Máxima verosimilitud (ML).
Una vez obtenidas las cargas, se aplica una rotación (Varimax, Promax, etc.) para mejorar la interpretación.
Es recomendable usar varios métodos y comparar resultados; si el modelo factorial es adecuado, las soluciones serán similares.
La estimación y la rotación requieren algoritmos iterativos, por lo que se utilizan programas especializados.
4.2.1 Factores Método de Componentes Principales y Método de Factores Principales
El punto de partida es la matriz de covarianzas poblacional \(\Sigma\). Sabemos que toda matriz simétrica y semidefinida positiva puede escribirse mediante su descomposición espectral. Existen pares autovalor–autovector \((\lambda_i, e_i)\), con \(\lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_p\), que permiten escribir:
\[ \Sigma = \lambda_1 e_1 e_1^\top + \lambda_2 e_2 e_2^\top + \cdots + \lambda_p e_p e_p^\top. \]
Esta representación puede reescribirse como
\[ \Sigma = \left[ \sqrt{\lambda_1} e_1 \;\; \sqrt{\lambda_2} e_2 \;\; \cdots \;\; \sqrt{\lambda_p} e_p \right] \left[ \begin{array}{c} \sqrt{\lambda_1} e_1^\top \\ \sqrt{\lambda_2} e_2^\top \\ \vdots \\ \sqrt{\lambda_p} e_p^\top \end{array} \right] = L_{p\times p}L_{p\times p}^\top + 0_{p\times p} = LL^\top, \]
donde \(L\) es la matriz cuyas columnas son \(\sqrt{\lambda_j} e_j\).
Esta expresión coincide exactamente con la estructura del modelo factorial ortogonal
\[ \Sigma = LL^{\top} + \Psi, \]
donde en este caso \(\Psi = 0\) y el número de factores es \(m = p\).
Aunque esta representación es exacta, no es útil para la reducción de dimensión porque emplea tantos factores como variables.
Si los últimos \(p-m\) autovalores son pequeños, puede ignorarse su contribucióny aproximar:
\[ \Sigma \approx \lambda_1 e_1 e_1^{\top} + \cdots + \lambda_m e_m e_m^{\top}. \]
En forma matricial:
\[ \Sigma \approx \left[ \sqrt{\lambda_1} e_1 \;\; \sqrt{\lambda_2} e_2 \;\; \cdots \;\; \sqrt{\lambda_m} e_m \right] \left[ \begin{array}{c} \sqrt{\lambda_1} e_1^{\top} \\ \sqrt{\lambda_2} e_2^{\top} \\ \vdots \\ \sqrt{\lambda_m} e_m^{\top} \end{array} \right] = L_{p\times m}L_{m\times p}^\top, \]
Esta es la base del método de : aproximar la covariación usando sólo los \(m\) factores más importantes.
El modelo factorial considera, además, un término de varianza específica \(\psi_i\) para cada variable. Para obtenerlo, se define:
\[ \psi_i = \sigma_{ii} - \sum_{j=1}^m \ \ell_{ij}^2, \qquad i = 1,\dots,p, \]
donde \(\ell_{ij}\) es la carga factorial correspondiente.
La aproximación factorial completa se escribe entonces como
\[ \Sigma \approx LL^\top + \Psi, \]
donde \(\Psi\) es diagonal con las varianzas específicas.
Dados datos \(x_1, x_2, \dots, x_n\), el primer paso es centrar las variables:
\[ x_j - \bar{x} = \begin{pmatrix} x_{j1} - \bar{x}_1 \\ x_{j2} - \bar{x}_2 \\ \vdots \\ x_{jp} - \bar{x}_p \end{pmatrix}. \]
La matriz de covarianzas de estas observaciones centradas es la matriz de covarianzas muestral \(S\).
Cuando las variables no están en las mismas unidades, se recomienda estandarizarlas:
\[ z_j = \begin{pmatrix} \dfrac{x_{j1} - \bar{x}_1}{\sqrt{s_{11}}} \\ \dfrac{x_{j2} - \bar{x}_2}{\sqrt{s_{22}}} \\ \vdots \\ \dfrac{x_{jp} - \bar{x}_p}{\sqrt{s_{pp}}} \end{pmatrix}. \]
La matriz de covarianzas de los \(z_j\) es la matriz de correlaciones muestral \(R\). Estandarizar evita que una variable con varianza anormalmente grande influya de manera indebida en la estimación de las cargas.
Aplicar la aproximación
\[ \Sigma \approx LL^\top + \Psi \]
a \(S\) (o a \(R\) si se trabaja con variables estandarizadas), usando los autovalores y autovectores de \(S\) o \(R\), produce la llamada del análisis factorial.
El nombre proviene de que las cargas factoriales \(\ell_{ij}\) se derivan de los coeficientes de las primeras componentes principales, reescaladas por \(\sqrt{\lambda_j}\).
RESUMEN
Solución por Componentes Principales del Modelo Factorial
El análisis factorial por componentes principales de la matriz de covarianzas muestral \(S\) se basa en sus pares autovalor–autovector estimados \[ (\hat{\lambda}_1, \hat{e}_1),\; (\hat{\lambda}_2, \hat{e}_2),\; \dots,\; (\hat{\lambda}_p, \hat{e}_p), \] donde \[ \hat{\lambda}_1 \ge \hat{\lambda}_2 \ge \cdots \ge \hat{\lambda}_p. \]
Sea \(m < p\) el número de factores comunes elegidos.
La matriz de cargas factoriales \(\{\widetilde{\ell}_{i,j}\}\) estimadas está dada por
\[ \widetilde{L} = \left[ \sqrt{\hat{\lambda}_1}\,\hat{e}_1 \;\; \sqrt{\hat{\lambda}_2}\,\hat{e}_2 \;\; \cdots \;\; \sqrt{\hat{\lambda}_m}\,\hat{e}_m \right]. \]
Las varianzas específicas se obtienen como los elementos diagonales de \[ S - \widetilde{L}\,\widetilde{L}^\top, \] es decir,
\[ \widetilde{\Psi} = \begin{pmatrix} \tilde{\psi}_1 & 0 & \cdots & 0 \\ 0 & \tilde{\psi}_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \tilde{\psi}_p \end{pmatrix}, \qquad \text{donde} \qquad \tilde{\psi}_i = s_{ii} - \sum_{j=1}^m \tilde{\ell}_{ij}^{\,2}. \]
La comunalidad estimada de la variable \(i\) es
\[ \tilde{h}_i^{\,2} = \tilde{\ell}_{i1}^{\,2} + \tilde{\ell}_{i2}^{\,2} + \cdots + \tilde{\ell}_{im}^{\,2}. \]
La solución por componentes principales del análisis factorial basada en la matriz de correlaciones se obtiene sustituyendo \(R\) en lugar de \(S\) y aplicando las mismas fórmulas.
4.2.1.1 Selección del número de factores en la solución por componentes principales
En la solución por componentes principales del modelo factorial, las cargas estimadas para un factor dado no cambian cuando se aumenta el número total de factores \(m\).
Por ejemplo, si \(m = 1\), la matriz de cargas estimadas es \[ \widetilde{L} = [\,\sqrt{\hat{\lambda}_1}\,\hat{e}_1\,], \] y si \(m = 2\), \[ \widetilde{L} = \big[\,\sqrt{\hat{\lambda}_1}\,\hat{e}_1 \;\; \sqrt{\hat{\lambda}_2}\,\hat{e}_2\,\big], \] donde \((\hat{\lambda}_1,\hat{e}_1)\) y \((\hat{\lambda}_2,\hat{e}_2)\) son los dos primeros pares autovalor–autovector de la matriz de covarianzas muestral \(S\) (o de la matriz de correlaciones muestral \(R\)).
Por definición de las varianzas específicas estimadas \(\tilde{\psi}_i\), los elementos diagonales de \(S\) coinciden con los elementos diagonales de \[ \widetilde{L}\,\widetilde{L}^\top + \widetilde{\Psi}. \] Sin embargo, los elementos fuera de la diagonal de \(S\) normalmente no se reproducen exactamente por \(\widetilde{L}\,\widetilde{L}^\top + \widetilde{\Psi}\).
Esto plantea la pregunta: ¿cómo seleccionar el número de factores comunes \(m\)?
Si el número de factores \(m\) no está determinado a priori (por teoría, por estudios previos, etc.), entonces puede elegirse con base en los autovalores estimados, de manera análoga a como se hace en el análisis de componentes principales.
Para ello se considera la matriz residual \[ S - (\widetilde{L}\,\widetilde{L}^{\top} + \widetilde{\Psi}) \] que resulta de aproximar \(S\) mediante la solución de componentes principales. Los elementos diagonales de esta matriz residual son cero (por construcción), y si los elementos fuera de la diagonal son también pequeños, se puede considerar que el modelo con \(m\) factores es adecuado.
Analíticamente, se tiene que la suma de cuadrados de los elementos de la matriz residual está acotada por la suma de los autovalores no utilizados: \[ \text{Suma de cuadrados de las entradas de } \bigl(S - (\widetilde{L}\,\widetilde{L}^\top + \widetilde{\Psi})\bigr) \;\;\le\;\; \hat{\lambda}_{m+1}^2 + \cdots + \hat{\lambda}_p^2. \] Por tanto, si los autovalores \(\hat{\lambda}_{m+1},\dots,\hat{\lambda}_p\) son pequeños, el error de aproximación también lo será.
Idealmente, las contribuciones de los primeros factores a las varianzas muestrales de las variables deberían ser grandes. La contribución del primer factor común a la varianza de la variable \(X_i\) viene dada por el cuadrado de su carga, \(\tilde{\ell}_{i1}^2\). La contribución del primer factor a la varianza muestral total \[ s_{11} + s_{22} + \cdots + s_{pp} = \operatorname{tr}(S), \] es entonces \[ \tilde{\ell}_{11}^2 + \tilde{\ell}_{21}^2 + \cdots + \tilde{\ell}_{p1}^2 = (\sqrt{\hat{\lambda}_1}\,\hat{e}_1)^\top (\sqrt{\hat{\lambda}_1}\,\hat{e}_1) = \hat{\lambda}_1, \] pues el autovector \(\hat{e}_1\) tiene norma unitaria.
En general, la proporción de varianza muestral total explicada por el factor \(j\) viene dada por \[\begin{array}{c} \text{Proporción de la varianza} \\ \text{ muestral total explicada} \\ \text{por el factor $j$} \end{array} = \begin{cases} \dfrac{\hat{\lambda}_j}{s_{11} + s_{22} + \cdots + s_{pp}}, & \text{si se factoriza } S, \\[8pt] \dfrac{\hat{\lambda}_j}{p}, & \text{si se factoriza } R. \end{cases} \] ya que en el caso de la matriz de correlaciones \(R\) la traza es \(p\).
El criterio anterior se utiliza frecuentemente como una regla heurística para determinar el número adecuado de factores comunes: se incrementa \(m\) hasta que se alcanza una proporción razonable de varianza explicada (por ejemplo, 70%, 80%, etc.).
Otra convención, muy habitual en programas estadísticos, consiste en fijar \(m\) igual al número de autovalores de \(R\) mayores que uno (cuando se factoriza la matriz de correlaciones), o igual al número de autovalores positivos de \(S\) (cuando se factoriza la matriz de covarianzas). Estas reglas no deben aplicarse indiscriminadamente. Por ejemplo, si se usa la regla de los autovalores positivos de \(S\), para muestras grandes los autovalores tienden a ser todos positivos, y se podría terminar eligiendo \(m = p\).
El enfoque más recomendable es retener un número relativamente pequeño de factores, siempre que:
proporcionen una interpretación razonable de los datos, y
ajusten de manera satisfactoria a \(S\) o a \(R\) (errores residuales pequeños).
Ejemplo(Ej 9.3 Johnson and Wichern): Se encuestó a una muestra de clientes para calificar, en una escala de 7 puntos, los siguientes atributos de un producto: - Taste (sabor)
Good buy for money (buena compra por el dinero)
Flavor (sabor/aroma)
Suitable for snack (adecuado como botana)
Provides lots of energy (aporta mucha energía)
A partir de las calificaciones se construyó la matriz de correlaciones
R <- matrix(c(
1.00, 0.02, 0.96, 0.42, 0.01,
0.02, 1.00, 0.13, 0.71, 0.85,
0.96, 0.13, 1.00, 0.50, 0.11,
0.42, 0.71, 0.50, 1.00, 0.79,
0.01, 0.85, 0.11, 0.79, 1.00
), nrow = 5, byrow = TRUE)
colnames(R) <- rownames(R) <-
c("Taste", "GoodBuy", "Flavor", "Snack", "Energy")
R## Taste GoodBuy Flavor Snack Energy
## Taste 1.00 0.02 0.96 0.42 0.01
## GoodBuy 0.02 1.00 0.13 0.71 0.85
## Flavor 0.96 0.13 1.00 0.50 0.11
## Snack 0.42 0.71 0.50 1.00 0.79
## Energy 0.01 0.85 0.11 0.79 1.00Las correlaciones altas entre las variables (1,3) y (2,5), así como las correlaciones de la variable 4 con 2 y 5, sugieren la presencia de dos grupos de atributos. Por ello, vamos a considerar un modelo con \(m=2\) factores comunes.
Calculemos los eigenvalores de \(R\):
## [1] 2.85309042 1.80633245 0.20449022 0.10240947 0.03367744## [,1] [,2] [,3] [,4] [,5]
## [1,] 0.3314539 -0.60721643 0.09848524 0.1386643 0.701783012
## [2,] 0.4601593 0.39003172 0.74256408 -0.2821170 0.071674637
## [3,] 0.3820572 -0.55650828 0.16840896 0.1170037 -0.708716714
## [4,] 0.5559769 0.07806457 -0.60158211 -0.5682357 0.001656352
## [5,] 0.4725608 0.40418799 -0.22053713 0.7513990 0.009012569Sólo los dos primeros son mayores que 1, de modo que se toma \(m=2\) factores.
La proporción de varianza total explicada por estos dos factores es \(\frac{\hat\lambda_1 + \hat\lambda_2}{p}=\) 0.9318846.
## [1] 0.9318846Consideremos los pares de autovalores y autovectores de la matriz de correlación \(R\) \[ (\hat{\lambda}_1, \hat{e}_1),\; (\hat{\lambda}_2, \hat{e}_2),\; \dots,\; (\hat{\lambda}_p, \hat{e}_p), \] Para el método de componentes principales, las cargas factoriales iniciales se obtienen como
\[ \tilde{\ell_ij} = \sqrt{\hat{\lambda_i}}\hat{e_i} , \]
Para este ejemplo se obtiene
## [,1] [,2]
## [1,] 0.56 -0.82
## [2,] 0.78 0.52
## [3,] 0.65 -0.75
## [4,] 0.94 0.10
## [5,] 0.80 0.54Donde cada columna corresponde a los factores \(f_i\).
La comunialidad de la variable \(i\) es \[ \tilde{h}_i^2 = \sum_{j=1}^m \tilde{\ell}_{ij}^2, \] y, dado que trabajamos con variables estandarizadas, la varianza específica es \[ \tilde{\psi}_i = 1 - \tilde{h}_i^2. \]
Las comunialidades y varianzas específicas se obtienen de la siguiente forma:
## [1] 0.98 0.88 0.98 0.89 0.93## [1] 0.02 0.12 0.02 0.11 0.07El modelo factorial implicaría que \[ R \approx \tilde{L}\tilde{L}^{\top} + \tilde{\Psi}, \] donde \(\tilde{\Psi}\) es una matriz diagonal con las varianzas específicas \(\tilde{\psi}_i\) en la diagonal.
## [,1] [,2] [,3] [,4] [,5]
## [1,] 1.00 0.01 0.97 0.44 0.00
## [2,] 0.01 1.00 0.11 0.78 0.91
## [3,] 0.97 0.11 1.00 0.53 0.11
## [4,] 0.44 0.78 0.53 1.00 0.81
## [5,] 0.00 0.91 0.11 0.81 1.00Para este ejemplo, la matriz \(\tilde{L}\tilde{L}^{\top} + \tilde{\Psi}\) es muy cercana a \(R\), por lo que el modelo de dos factores proporciona un buen ajuste descriptivo a los datos. Además, las comunialidades indican que el modelo de dos factores alcanza un porcentaje alto de la varianza total explicada de cada variable.
4.2.2 Factores principales iterados (un enfoque modificado de Factores principales)
Este proceso se puede realizar tanto sobre \(R\) como \(S\). Lo siguiente será en función de la matriz \(R\).
Si el modelo de factores \(\rho = LL^\top + \Psi\) está correctamente especificado, los \(m\) factores comunes
En el análisis factorial partimos del modelo \[ \rho = LL^{\top} + \Psi, \] donde \(\rho\) es la matriz de correlaciones poblacional, \(L\) contiene las cargas factoriales y \(\Psi\) es la matriz diagonal de varianzas específicas. Dado que las variables están estandarizadas, cada diagonal cumple \[ \rho_{ii} = 1 = h_i^2 + \psi_i, \] donde \(h_i^2\) es la comunalidad de la variable \(i\) y \(\psi_i\) su varianza específica.
Si removemos la contribución específica \(\psi_i\) de la diagonal, o equivalentemente reemplazamos el 1 por \(h_i^2\), obtenemos la matriz \[ \rho - \Psi = LL^\top. \]
Supongamos ahora que tenemos estimaciones iniciales \(\psi_i^*\) de las varianzas específicas. Entonces la \(i\)-ésima diagonal de \(\rho\) se reemplaza por \[ h_i^{*2} = 1 - \psi_i^*, \] con lo cual obtenemos la \[ R_r = \begin{pmatrix} h_1^{*2} & r_{12} & \cdots & r_{1p} \\ r_{12} & h_2^{*2} & \cdots & r_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ r_{1p} & r_{2p} & \cdots & h_p^{*2} \end{pmatrix}. \]
Supondremos que toda la estructura de correlación en \(R_r\) puede explicarse por \(m\) factores comunes. Por ello, factorizamos \[ R_r \approx L^* {L^*}^\top, \] donde \(L^* = (\ell_{ij}^*)\) contiene las .
El método de factores principales utiliza para \(L^*\) la expresión \[ L^* = \left[ \sqrt{\hat{\lambda}_1^*}\, \hat{e}_1^* \,:\: \sqrt{\hat{\lambda}_2^*}\, \hat{e}_2^* \,:\: \cdots \,:\: \sqrt{\hat{\lambda}_m^*}\, \hat{e}_m^* \right], \] donde \((\hat{\lambda}_i^*, \hat{e}_i^*)\) son los \(m\) mayores pares autovalor-autovector obtenidos de la matriz reducida \(R_r\).
Dadas estas cargas, las comunalidades se reestiman mediante \[ \tilde{h}_i^2 = \sum_{j=1}^m \ell_{ij}^{*2}. \]
El procedimiento se puede iterar: las comunalidades estimadas reemplazan a las anteriores en la diagonal de \(R_r\), y se recalculan autovalores y cargas.
De forma similar al método de componentes principales, los autovalores \[ \hat{\lambda}_1^*,\ \hat{\lambda}_2^*,\ \ldots,\ \hat{\lambda}_p^* \] de la matriz reducida ayudan a decidir cuántos factores retener. Sin embargo, debido al uso de comunalidades estimadas, algunos autovalores pueden ser negativos, lo cual complica la elección del número de factores. Idealmente, retendríamos tantos factores como el rango de la matriz poblacional reducida.
Para comenzar el algoritmo se requieren valores iniciales \(\psi_i^*\). Una elección muy común, cuando se trabaja con matrices de correlación, es \[ \psi_i^* = \frac{1}{r^{ii}}, \] donde \(r^{ii}\) es el elemento diagonal \(i\) de \(R^{-1}\). Las comunalidades iniciales serían entonces \[ h_i^{*2} = 1 - \psi_i^* = 1 - \frac{1}{r^{ii}}. \]
Este valor coincide con el cuadrado del coeficiente de correlación múltiple entre \(X_i\) y las restantes \(p-1\) variables.
Aunque el método de componentes principales puede verse como un caso especial del método de factores principales (si se toman las comunalidades iniciales iguales a 1), ambos enfoques tienen diferencias filosóficas y geométricas importantes. En la práctica, las dos técnicas producen con frecuencia cargas factoriales similares, especialmente cuando:
el número de variables es grande,
el número de factores comunes es pequeño.
4.2.3 Factores por máxima verosimilitud
En el análisis factorial, si asumimos que los factores comunes \(F\) y los factores específicos \(\varepsilon\) están normalmente distribuidos, entonces es posible obtener estimadores de máxima verosimilitud para las cargas factoriales y las varianzas específicas.
Sea el modelo factorial \[ X_j - \mu = L F_j + \varepsilon_j, \] donde \(X_j\) es el vector de observaciones de la variable \(j\), \(L\) es la matriz de cargas y \(\Psi\) es la matriz diagonal de varianzas específicas. Si tanto \(F_j\) como \(\varepsilon_j\) son normales, entonces cada \(X_j\) es normal con matriz de covarianza \[ \Sigma = LL^{\top} + \Psi. \]
Suponiendo una muestra aleatoria \(X_1, X_2, \ldots, X_n\) de \(\mathcal{N}_p(\mu, \Sigma)\), la verosimilitud viene dada por \[ L(\mu,\Sigma) = (2\pi)^{-\frac{np}{2}} |\Sigma|^{-\frac{n}{2}} \exp\left( -\frac{1}{2}\texttt{tr}\left[\sum \ ^{-1} \left(\sum_{j=1}^{n} (X_j -\bar{X})(X_j -\bar{X})^{\top} + n(\bar{X} - \mu)(\bar{X} - \mu)^{\top} \right)\right] \right), \] es decir, depende de \(L\) y \(\Psi\) únicamente a través de \(\Sigma = LL^{\top} + \Psi\).
Debido a que múltiples matrices \(L\) producen la misma matriz \(\Sigma\) mediante rotaciones ortogonales, el modelo no está completamente identificado. Para resolver esta indeterminación, se impone la siguiente condición de unicidad: \[ L^{\top}\Psi^{-1} L = \Delta, \] donde \(\Delta\) es una matriz diagonal. Esta restricción fija una orientación conveniente para los factores.
En la práctica, los estimadores de máxima verosimilitud \(\hat{L}\) y \(\hat{\Psi}\) se obtienen mediante algoritmos numéricos, ya que maximizar explícitamente la verosimilitud es algebraicamente complejo. Existen hoy en día programas de computadora que realizan estas estimaciones de manera eficiente.
Método de Máxima Verosimilitud (Maximum Likelihood Method)
Proposición: Sea \(X_1, X_2, \ldots, X_n\) una muestra aleatoria de \(\mathcal{N}_p(\mu,\Sigma)\), donde \[ \Sigma = LL^{\top} + \Psi \] es la matriz de covarianzas bajo el modelo factorial con \(m\) factores comunes. Sean \(\hat{L}\) y \(\hat{\Psi}\) los estimadores de máxima verosimilitud que maximizan la verosimilitud sujeta a la condición \[ \hat{L}^{\top} \hat{\Psi}^{-1} \hat{L} \quad \text{diagonal}. \]
Entonces:
Las comunalidades estimadas por máxima verosimilitud son \[ \hat{h}_i^2 = \hat{\ell}_{i1}^2 + \hat{\ell}_{i2}^2 + \cdots + \hat{\ell}_{im}^2, \qquad i=1,\ldots,p. \]
La proporción de la varianza total de la muestra explicada por el factor \(j\) es \[ \frac{ \hat{\ell}_{1j}^2 + \hat{\ell}_{2j}^2 + \cdots + \hat{\ell}_{pj}^2 }{ s_{11} + s_{22} + \cdots + s_{pp} }, \] donde \(s_{ii}\) son los elementos diagonales de la matriz de covarianzas de la muestra.
Este resultado resume las cantidades más importantes obtenidas mediante el método de máxima verosimilitud: las comunalidades y la varianza explicada por cada factor. Aunque la maximización de la verosimilitud requiere métodos numéricos, las expresiones finales para la interpretación del modelo factorial son conceptualmente simples.
Ejemplo: