Sección 3 Git y Github
Usar control de versiones es una forma de manejar proyectos, todo a lo que se hace commit se pierde, se queda un registro de todos los cambios y siempre es posible regresar a una versión anterior. Nos evitamos estar enviando y enviando correos con versiones finales para después comparar versiones. Se guarda el usuario que hizo el cambio y automáticamente obtenemos una notificación de si intentamos modificar lo mismo que un colaborador para revisar cual cambio guardar.
Pueden pensar en versión de control como una forma de undo ilimitado y de trabajar paralelamente con sus colaboradores.
Lo primero que vamos a hacer es configurar Git en nuestra computadora.
Vamos a abrir Git bash y configurar nuestro usuario y correo con la que vamos a enlazar más adelante Github.
Ahora, vamos a configurar los saltos de línea para no tener conflicto según el sistema operativo.
# Mac o Linux
$ git config --global core.autocrlf input
# Windows
$ git config --global core.autocrlf truePara configurar el editor de texto por default:
Por default, Git inicializa un repositorio con una rama llamada master, a partir del 2020, la mayoría de los servidores de Git cambiaron esto a que la rama principal fuera main, para configurar esto usaremos lo siguiente:
Los comandos anteriores solo se necesitan configurar una sola vez. Para ver la configuración que acabamos de realizar y probar cual es nuestro editor de texto usamos lo siguiente:
Y para revisar esta configuración sin entrar al editor:
Si debieran hacer cambios en su usuario o correo o cualquier otra configuración lo pueden hacer ilimitadas veces con los comandos anteriores.
Para pedir ayuda nos sirve aún git comando -h o git comando --help, por ejemplo:
O para ayuda general de Git: git help.
3.1 Repositorios
Un repositorio es donde se va a almacenar toda la información de nuestro proyecto, es donde vamos a tener toda la historia y registro de cambios y usuarios. Es recomendable tener un repositorio por proyecto y no multiples proyectos en un solo repositorio.
Vamos a movernos a la carpeta del curso y vamos a hacer una carpeta para trabajar con git.
Para inicializar un repositorio usamos lo siguiente (dentro de la carperta).
Al inicializar el repositorio, cualquier carpeta y archivo que se cree dentro de la carpeta quedará su registro, no es necesario inicializar las carpetas anidadas.
Si revisamos que tiene la carpeta solo con ls no vamos a notar ningún cambio pero si listamos con la opción -a veremos que contiene archivos ocultos. En el archivo .git se almacena TODA la información de nuestro repositorio, así que si lo borramos perderemos todo el historial del repositorio.
Para cambiar manualmente la rama de nuestro repositorio si no es la main, lo podemos hacer como sigue.
Para preguntarle a git el estado de nuestro proyecto:
Si dentro de una carpeta preguntamos git status y obtenemos el siguiente mensaje:
fatal: not a git repository (or any of the parent directories): .gitsignifica que si podemos inicializarlo como un repositorio.
Ejercicio: Dentro de la carpeta Mi_primer_repo crea una carpeta llamada subproyecto1. Si quieres llevar un registro de lo que hagas en ese subproyecto, ¿debes inicializarla? Inicializala. Ahora, ¿cómo borras el archivo .git?
3.2 Rastrear cambios
Vamos a crear un archivo de texto dentro de la carpeta Mi_primer_repo.
Y escribamos algo en el archivo y guardemoslo.
Ahora, si preguntamos por el estado de nuestro proyecto vamos a obtener un mensaje de que hay algo nuevo:
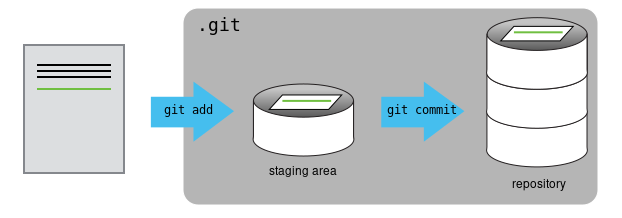
El mensaje que dice untracked files nos indica que hay cambios y que a Git no se le ha indicado que debe registrarlos. Para añadir estos cambios hacemos lo siguiente:
Si revisamos el estado del proyecto vemos que ahora un mensaje diferente, ahora solo nos indica que no se ha realizado ningún commit pero que si se tiene registro de algo que cambio.
Para hacer un commit:
Este comando le dice a Git que tome todo lo que se añadió y que guarde una copia permanente dentro del directorio .git. Cada commit tiene un identificador único. Si no especificamos el mensaje, Git abrirá un editor de texto para colocar el mensaje. Los mensajes deben de reflejar lo que se está guardando para que sean útiles en el futuro.
Si ahora verificamos el estado del proyecto veremos que nos dice que no hay nada a lo que hacer commit ya que en el paso anterior añadimos todo y no hemos realizado ningún cambio.
Para mostrar el historial del proyecto:
Ahora, añadamos una línea nueva al archivo prueba.txt
Primer archivo en el que rastrearemos cambios.
Segunda línea de cambios para continuar con el ejemplo.Si revisamos el estado veremos de nuevo que nos devuelve el mensaje de que hay archivos sin rastrear. Para comparar las diferencias del archivo usamos:
El signo + nos está indicando cuales son los cambios en el archivo nuevo.
Vamos a hacer un commit de este cambio.
¿Qué paso? Nos esta diciendo que no hemos añadido nada al staged area a lo que le podamos hacer un commit, recuerden añadir todo antes de hacer commit.
Añadir todo primero al área de preparación nos permite tener un mejor control de a que le estamos haciendo commit, por ejemplo podemos añadir y hacerle commit solo al archivo donde tenemos la bibliografía y no a todo el proyecto donde hay partes no completas.
Ejercicio: Añadamos una tercera línea al archivo y verifiquemos las diferencias en los archivos, después añadamoslo al área de preparación y revicemos las diferencias. ¿Qué sucede?
Al añadirlo al área de preparación lo estamos añadiendo permanentemente, entonces no hay ninguna diferencia. Si queremos las diferencias con lo último a lo que se le hizo commit podemos hacer lo siguiente:
Ahora hagamos el commit.
Si revisamos el historial, veremos ahora 3 commit diferentes:
Cuando el historial es muy grande no nos va a mostrar todo el historial nuestra terminal, para ir avanzando debemos presionar Spacebar y para salir la letra Q. Al presionar / se puede buscar alguna palabra en los mensajes de los commits. Para limitar la cantidad de información que nos regresa log podemos especificar con la opción -n la cantidad de commits desde el más reciente. Para ver por ejemplo el último utilizariamos lo siguiente:
Si queremos ver los mensajes en una sola línea usamos:
Git no guarda información de directorios vacíos. Por ejemplo:
Si creamos un directorio con archivos, entonces si podemos añadir todos los archivos a la vez y si quedará el registro del directorio también.
$ git touch dic_prueba/prueba1.txt dic_prueba/prueba2.txt dic_prueba/prueba3.txt
$ git status
$ git add dic_prueba
$ git status
$ git commit -m "Ejemplo de como realizar un registro de directorios con archivos"En algunas ocasiones verán directorios vacíos con un archivo .gitkeep, este archivo es solo para que podamos añadir el repo a Git.
Ejercicio: Crea un archivo mi_archivo.txt, escribe algo en el y guárdalo en la ruta Mi_primer_repo. Añádelo a la historia de tu repo. ¿Cuáles son los pasos que debes realizar?
Ejercicio: Modifica el archivo prueba.txt añadiéndole una línea, ahora en el archivo mi_archivo.txt agrega algo y guárdalo. ¿Cómo añadirías los dos archivos al staging área? Añádelos y realiza el commit correspondiente.
Ejercicio: Crea un repositorio llamado bio. Escribe en un archivo llamado me.txt tres líneas de tu biografía, has un commit con tus cambios. Modifica una línea y agrega una cuarta línea. Muestra las diferencias entre el archivo en el staging área y el actual.
3.3 Explorando el historial
A los commits nos podemos referir a ellos con sus identificadores. Al último commit también nos podemos referir como HEAD. Añadamos una línea más al archivo prueba.txt.
Ahora, para ver el último cambio con el último commit:
Si quitamos el HEAD de esa última instrucción veremos lo mismo. Pero si colocamos un ~numero vamos a ver que nos estamos refiriendo al commit anterior número n.
Con git show vamos a ver los cambios con respecto a un commit anterior.
También podemos referirnos a los commit por su identificador de números y letras enorme o por los primeros 7 números o letras:
Revisemos el estado:
Con la siguiente instrucción podemos regresar las cosas a como estaban antes de hacer el último cambio.
O podríamos usar uno de los identificadores de commits:
Y para regresarlo al último commit de nuevo:
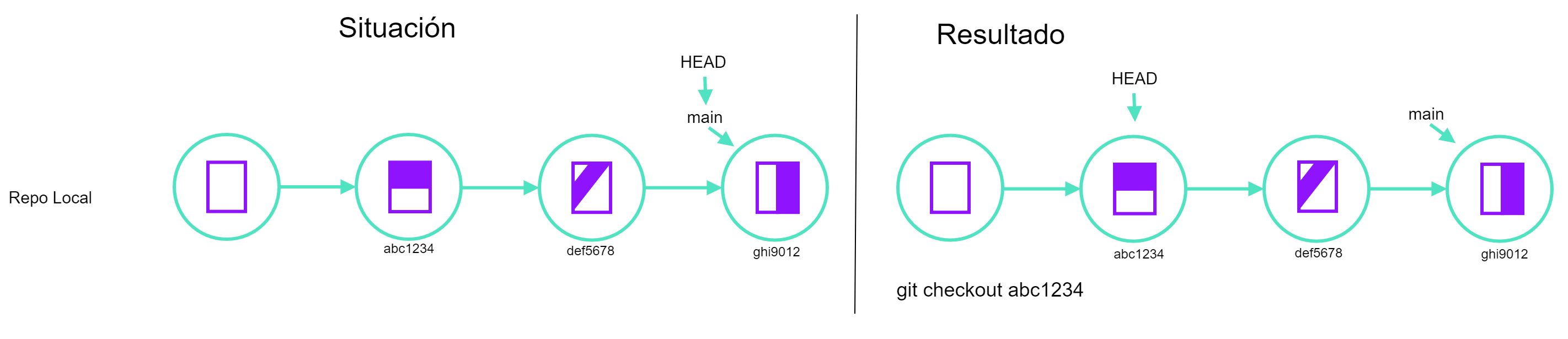
git checkout <ID commit> <archivo>, basdo en ASSPEl comando git checkout revierte los archivos a alguna versión anterior siempre que no lo hayamos añadido al staging área. Para revertir un commit usamos la instrucción git revert [ID commit]. Supongamos que tenemos un error en el archivo prueba.txt y que ya hicimos commit y queremos revertir al último cambio. Los pasos que haríamos serían los siguientes:
git logpara identificar el ID del commit.Copiar el ID del commit
git revert [ID del commit]para revertir a ese cambio.Teclear el nuevo mensaje de commit.
Guardar y cerrar
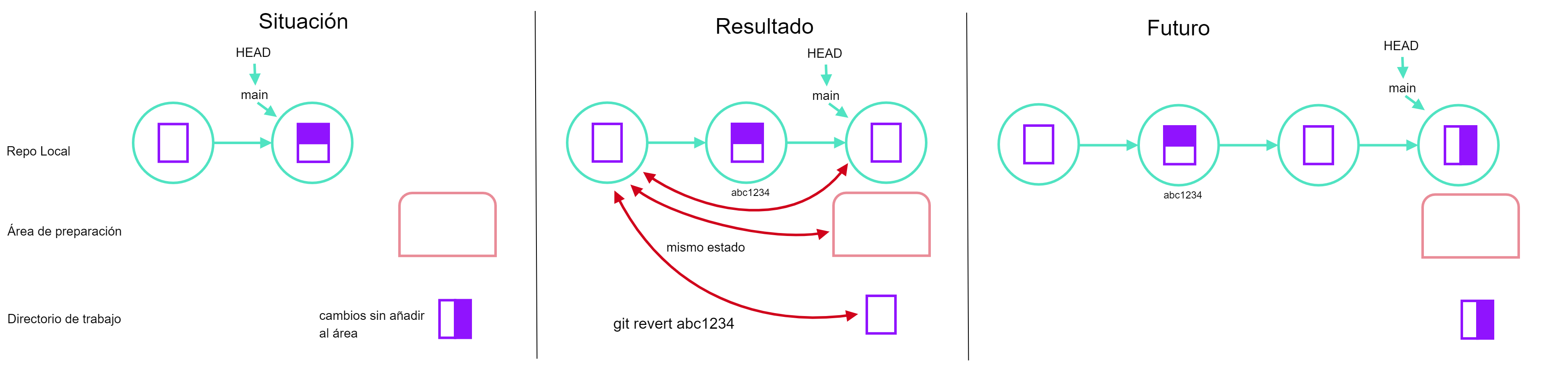
git revert <ID commit>, basado en APPSi ya añadimos los cambios al área de preparación, ya no podemos usar git checkout simplemente.
Ejercicio: Realiza las siguientes instrucciones:
Crea una carpeta llamada
learn_revert.Muévete a la carpeta
learn_revertInicializa el repositorio.
Crea un archivo llamado
first.txty añade una línea de texto.Agrégalo al área de preparación y realiza el primer commit.
Crea el archivo
wrong.txty agrega una línea de texto.Agrégalo al área de preparación y realiza un commit.
Agrega una segunda línea de texto al archivo
first.txt, guárdalo, agrégalo al área de preparación y realiza un commit.Agrega una tercera línea de texto al archivo
first.txt, guárdalo, agrégalo al área de preparación y realiza un commit.Queremos deshacer el commit realizado cuando se añadió el archivo
wrong.txt. Como este commit fue el segundo de donde no estamos, podemos usargit revert HEAD~2(o podemos usargit logy encontrar el ID de ese commit).
¿Está el archivo wrong.txt? ¿Qué sucede con el historial de commits?
Otras opciones del historial del commit:
- Para ver tanto las diferencias entre los archivos y los ID de los commits. Se puede colocar solo el nombre de un archivo y solo mostrara los commit que afectaban ese archivo o si no se coloca el nombre del archivo aplica sobre todo el historial de commits.
- Para mostrar las descripciones detalladas de las modificaciones y archivos.
- Para mostrar los nombres de los archivos afectados en cada commit.
- Para mostrar los archivos afectados en cada commit con la leyenda de si fueron modificados (M) o añadidos (A) o eliminados.
Consultar el siguiente link para ver más opciones y ejemplos.
3.4 Restore y reset
Otra forma de deshacer cambios es con restore y reset. Usualmente deshacer cambios se requiere para deshacer:
Cambios antes de mandarlos al área de preparación.
Cambios que ya se mandaron al área de preparación.
Commits
Supongamos que hicimos un cambio en el archivo de prueba y lo guardamos y después decidimos que ya no queremos ese cambio, entonces usamos la opción:
Esto nos regresará a la versión del archivo del último commit. Esto no se puede deshacer, una vez echo esto no hay forma de recuperar los cambios que se habían realizado.
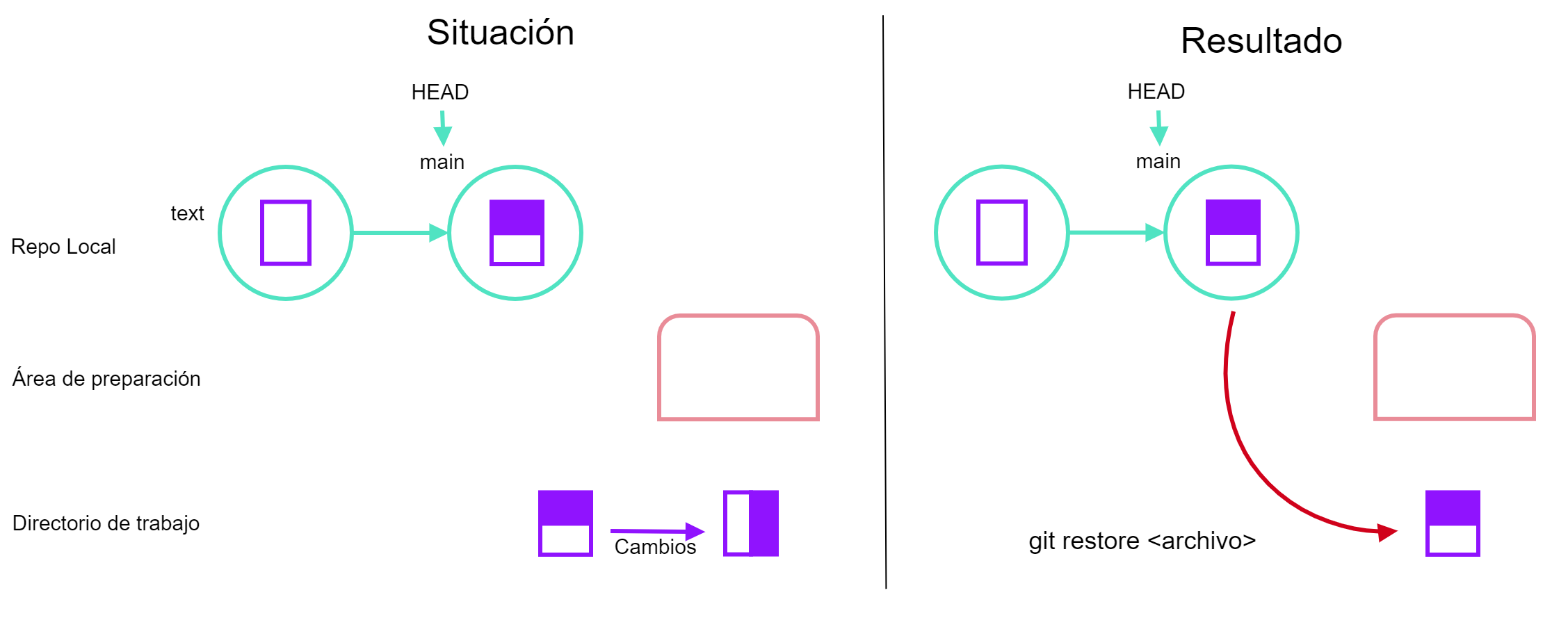
git restore <archivo>, basado en ASSPAhora, supongamos que hicimos un cambio y lo mandamos al área de preparación, entonces para sacarlo de esa área usamos:
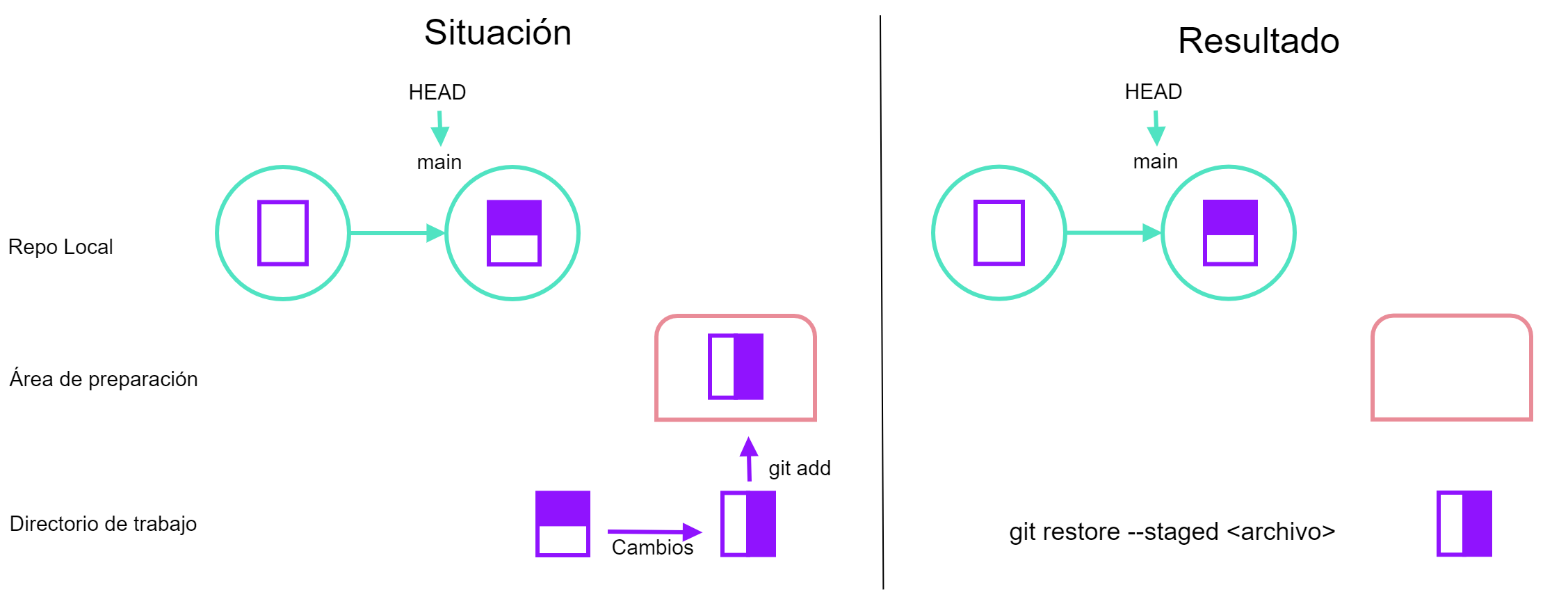
git restore --staged <archivo>, basado en ASSPTambién se pueden restaurar todos los archivos de un proyecto con:
Para restaurar a un commit anterior usamos el identificador del commit, por ejemplo:
Si ahora revisamos el estado del proyecto veremos que si hay cambios.
Agreguemos una línea al archivo prueba.txt y añadamos el cambio al área de preparación. Usen git checkout para ver si podemos revertir el cambio. Veamos que nos dice el estado git status. Si usamos git checkout -- prueba.txt ya no veremos errores pero tampoco se restaurará el archivo.
Para hacerlo debemos usar reset:
Y si usamos ahora:
Nos indica que ya podemos realizar la modificación con checkout:
Con reset tenemos tres posibles situaciones.
- Situación 1:
reset --soft HEAD~1: si realizamos un cambio en nuestro archivo y lo añadimos al área de preparación, al realizar elreset softal commitHEAD~1lo que estamos haciendo es como regresar a un commit anterior pero sin perder los cambios que ya tenemos en el área de preparación, entonces lo que va a resultar es que nuestro historial va a cambiar de un commit anterior hasta el cambio que tenemos ahora. Congit statusvemos que no cambio nuestra área de preparación y después congit logpodemos ver el cambio en el historial de commits.
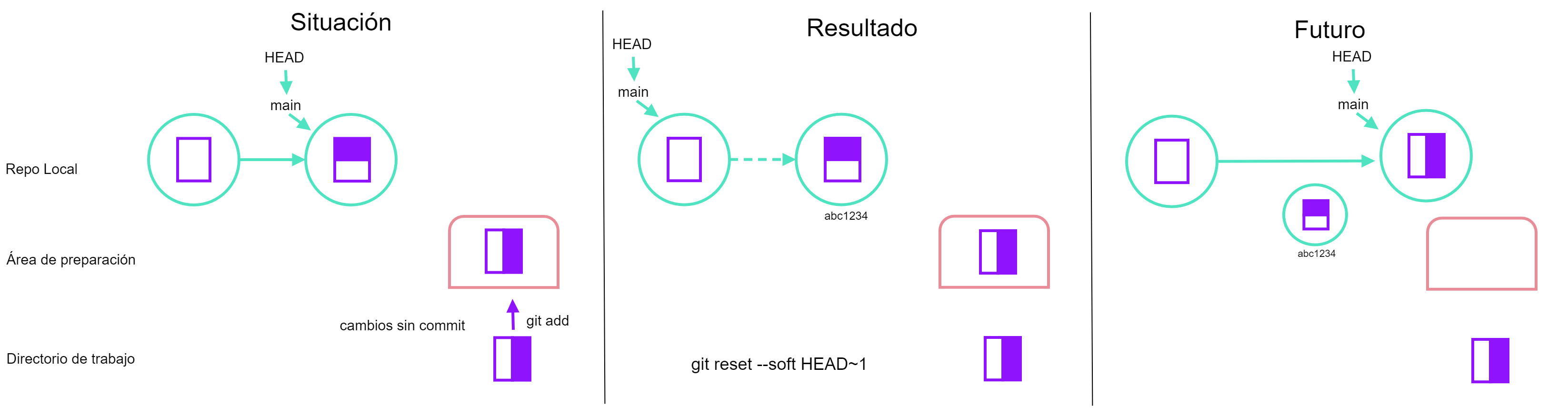
git reset --soft HEAD~1, basado en ASSP- Situación 2:
reset --mixed HEAD~1: si realizamos un cambio en nuestro archivo y lo añadimos al área de preparación, al realizar elreset mixedal commitHEAD~1lo que estamos haciendo es como regresar nuestra área de preparación a como estaba antes de ese commit, no perdemos el cambio realizado en el archivo pero nuestro historial cambiará, pasará del commit anterior hasta el próximo commit que realicemos. Congit statusvemos que nuestra área de preparación si cambio y congit logvemos que nuestro último commit desapareció.
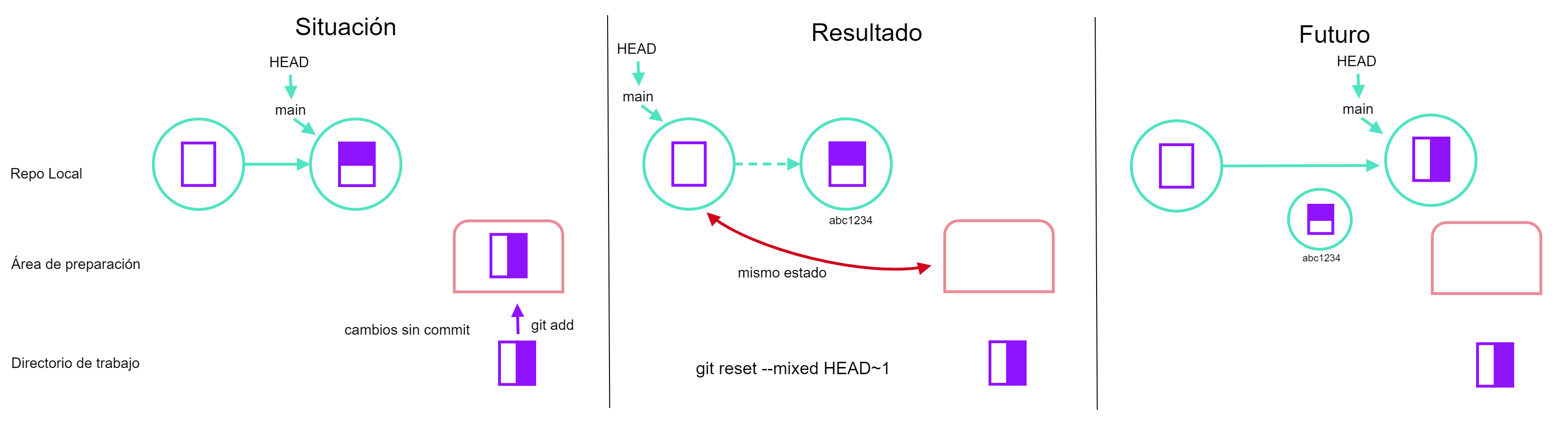 - Situación 3:
- Situación 3: reset --hard HEAD~1: si realizamos un cambio en nuestro archivo y lo añadimos al área de preparación, al realizar el reset hard al commit HEAD~1 lo que estamos haciendo es como regresar a un commit anterior pero perdiendo los cambios que ya tenemos en el área de preparación y en nuestro archivo actual, entonces lo que va a resultar es que estaríamos regresando hasta el commit anterior todo nuestro historial y a partir de ahí comenzarían nuestros cambios.
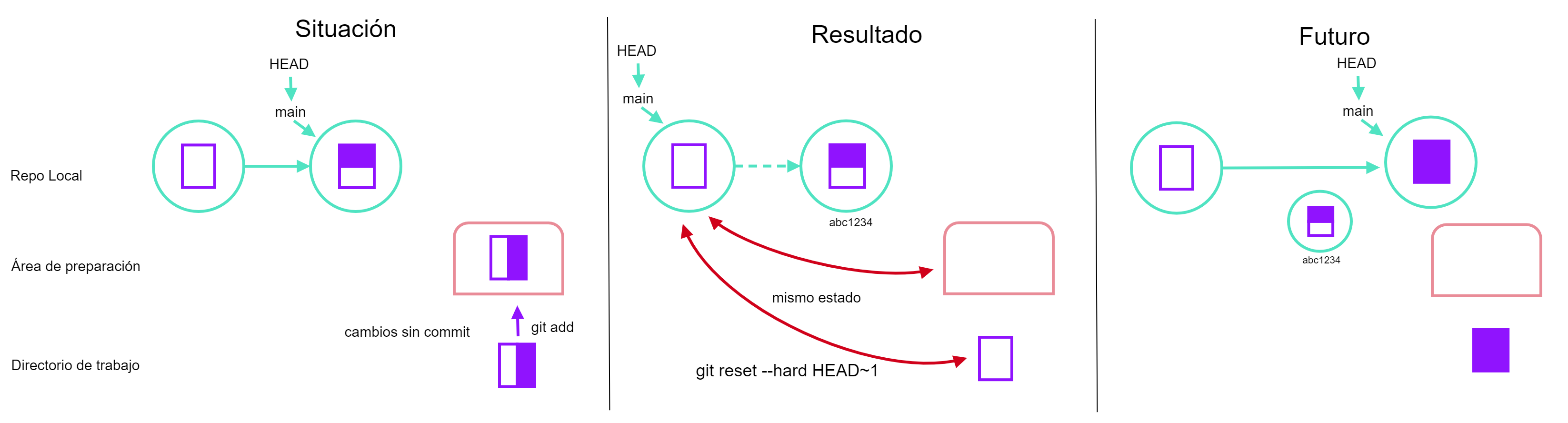
git reset --hard HEAD~1, basado en ASSP3.5 Ignorar archivos/carpetas
Es muy usual tener un archivo llamado .gitignore donde se pueden colocar los nombres de archivos o carpetas que no queremos llevar registro.
Creemos unos archivos de prueba.
Si preguntamos el estado veremos los cambios no registrados en el historial.
Estos archivos por el momento no nos sirven de nada y guardarlos o registrarlos sería una perdida de tiempo/espacio. Para ignorarlos, creamos el archivo .gitigno y añadimos los nombres a ese archivo:
Estos patrones le están diciendo a Git que ignore todos los archivos .csv y todo lo que hay en la carpeta resultados, si después añadimos algo a la carpeta lo seguirá ignorando. Y si alguno de esos archivos ya se le dijo a Git que llevará su registro lo seguirá registrando.
Si nos fijamos, el único documento que ahora nos menciona Git es el archivo .gitignore. Lo que nos falta es añadirlo y hacer el commit.
$ git add .gitignore
$ git commit -m "Creamos el archivo gitignore e ignoramos todo lo que hay en resultados y archivos csv"
$ git statusEl archivo .gitignore nos ayuda a no cometer el error de accidentalmente tratar de registrar y rastrear algo que se le dijo que no lo hiciera.
Si realmente queremos agregarlo, tendríamos que usar la opción -f:
Para ver el estado de los archivos ignorados usamos la siguiente instrucción:
Ejercicio: Supongamos que tenemos las siguientes subcarpetas:
¿Qué tenemos que hacer si queremos ignorar solamente lo que hay en datos y no lo que hay en plots?
Para ignorar por ejemplo todos los archivos que terminan en .csv excepto uno en específico (b.csv) podemos indicarlo en el archivo .gitignore como:
Ejercicio: Supongamos ahora que tenemos la siguiente estructura de carpetas:
Y que queremos ignorar todo excepto lo que hay en datos. ¿Cómo lo harían?
Ejemplo: Supongamos que tenemos la siguiente estructura de archivos:
¿Cómo le indicas a Git que ignore todos los csv de la carpeta rdatos menos el que se llama info.txt?
Ejercicio: Supongamos que tenemos la siguiente estructura de datos:
resultados/a.csv
resultados/analisis1/b.csv
resultados/analisis2/c.csv
resultados/analisis2/sub_1/d.csv¿Cómo le indicamos a Git que ignore todos los archivos .csv sin indicar manualmente todos los directorios?
Ejercicio: Si en el archivo .gitignore escribimos lo siguiente, ¿qué está ignorando?
3.6 Github
El valor del control de versiones se hace evidente al comenzar a colaborar con otros. Contamos con la mayor parte de las herramientas necesarias para ello; lo único que resta es transferir cambios de un repositorio a otro.
Sistemas como Git posibilitan el traslado de trabajo entre cualquier par de repositorios. No obstante, en la práctica, resulta más conveniente utilizar una copia como punto central y mantenerla en la web en lugar de en la computadora portátil de alguien.
Vamos a comenzar por crear un repositorio remoto, pero para eso necesitamos configurar nuestra cuenta de Github también.
3.6.1 Paso 1: Crear un repositorio remoto
Lo primero que vamos a hacer es crear un repositorio remoto. Entra a tu cuenta de Github y dale click en Nuevo.

Ponle de nombre Mi_primer_repo (o el nombre que hayas usado en las secciones anteriores). Deja marcada la opción de público y no añadas un README ni una licencia.
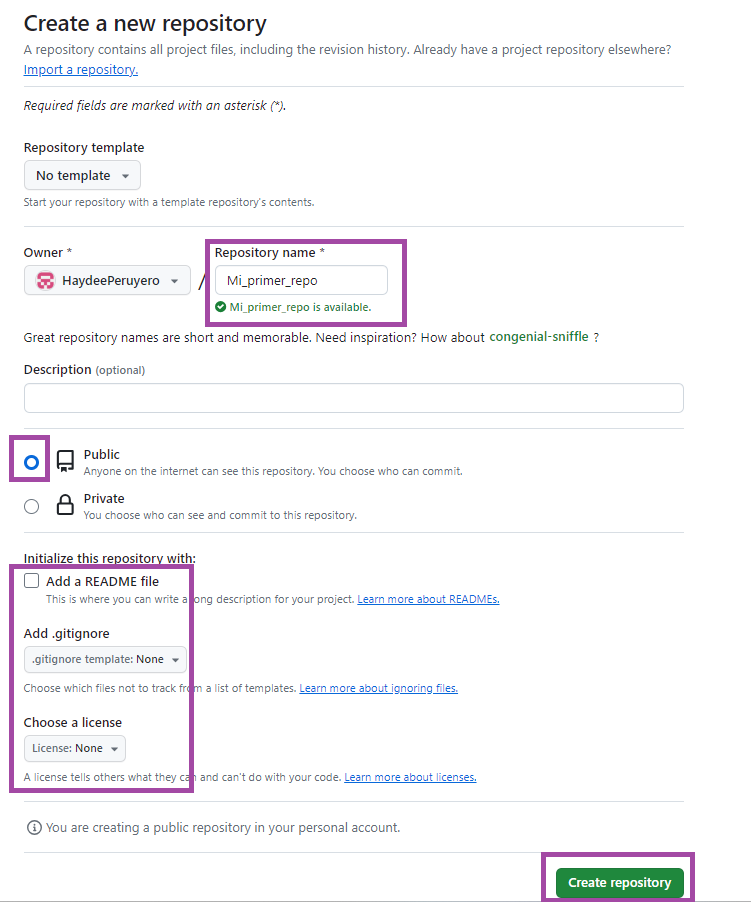
Al darle click en crear repositorio, la página nos mostrará la siguiente información que es la que usaremos para configurar nuestro local con el remoto.
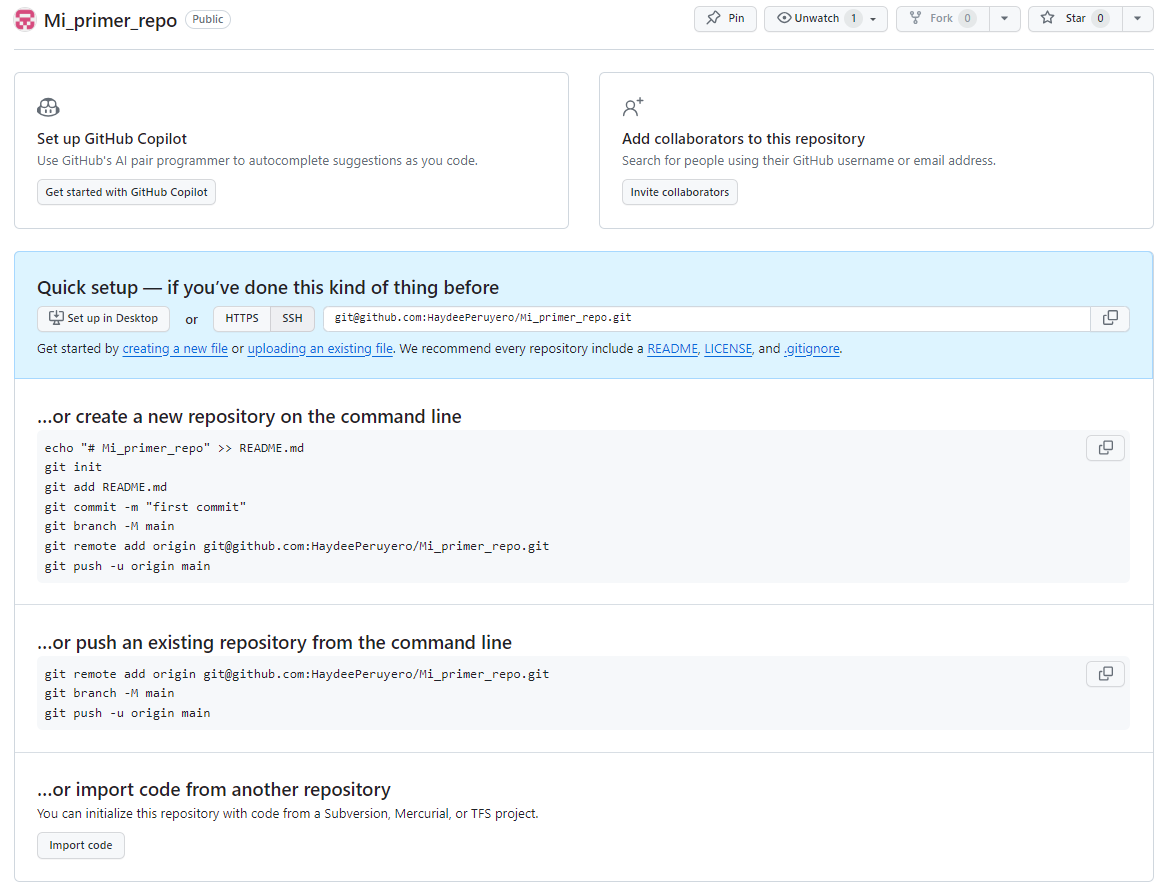 Lo que acabamos de hacer es como si en nuestra terminal hubiéramos realizado lo siguiente:
Lo que acabamos de hacer es como si en nuestra terminal hubiéramos realizado lo siguiente:
3.6.2 Paso 2: Conectar local a remoto
La página principal del repositorio remoto muestra una serie de información que necesitamos usar para conectar el repositorio remoto en Github con el repositorio local de nuestra computadora. Vamos a usar el protocolo de conexión SSH, da click en donde dice SSH y a continuación en el icono de copiar.

Ahora, dentro de nuestra carpeta del repositorio local, abrir una terminal y correr lo siguiente:
Para revisar que si se haya realizado correctamente procedemos a usar lo siguiente:
3.6.3 Paso 3: Conexión mediante SSH
Primero verificamos si ya tenemos algún par de llaves:
Si ya tienen algún par de llaves configuradas las van a ver listadas, si no tiene ninguna les saldrá una leyenda como la siguiente:
ls: cannot access '/c/Users/User/.ssh': No such file or directory3.6.3.1 Paso 3.1: Crear un par de llaves SSH
Para crear el par de llaves usamos el siguiente comando, la opción -t se refiere al tipo de algoritmo usado y la opción -C indica un comentario para la llave, en este caso el comentario es nuestro correo.
Si tu sistema operativo no lo permite, usa ssh-keygen -t rsa -b 4096 -C "your_email@example.com".
Como queremos usar el archivo default, solo damos Enter. Ahora nos pedirá una contraseña, tecleala, no vas a ver nada en la pantalla. Una vez creada verás en pantalla algo como lo siguiente:
Your identification has been saved in /c/Users/user/.ssh/id_ed25519
Your public key has been saved in /c/Users/user/.ssh/id_ed25519.pub
The key fingerprint is:
SHA256:SMSPIStNyA10KPxuYu94KpZg9AYjgt9g46A4kFy3g1o user@domain
The keys randomart image is:
+--[ED25519 256]--+
|^B== o. |
|%*= *.+ |
|+=.E =.+ |
| .=.+.o.. |
|... . S |
|.+ o |
|+ = |
|.o.o |
|oo+. |
+----[SHA256]-----+Lo que dice identification ser refiere a la llave privada la cual no debes compartir nunca y la cadena de caracteres que dice fingerprint se refiere a parte de tu llave pública.
Si repetimos el comando siguiente, verán ahora ya sus dos claves pública y privada.
Ahora que ya tenemos las claves, debemos decirle a GitHub cuales son.
Copia la cadena de caracteres, ve a la configuración de tu perfil de GitHub y da clic en “SSH and GPG Keys”.
Una vez ahí da clic en “Nueva llave SSH”.

Después coloca un título que te permita identificar que será la clave con la que usarás la computadora y pega tu llave pública.
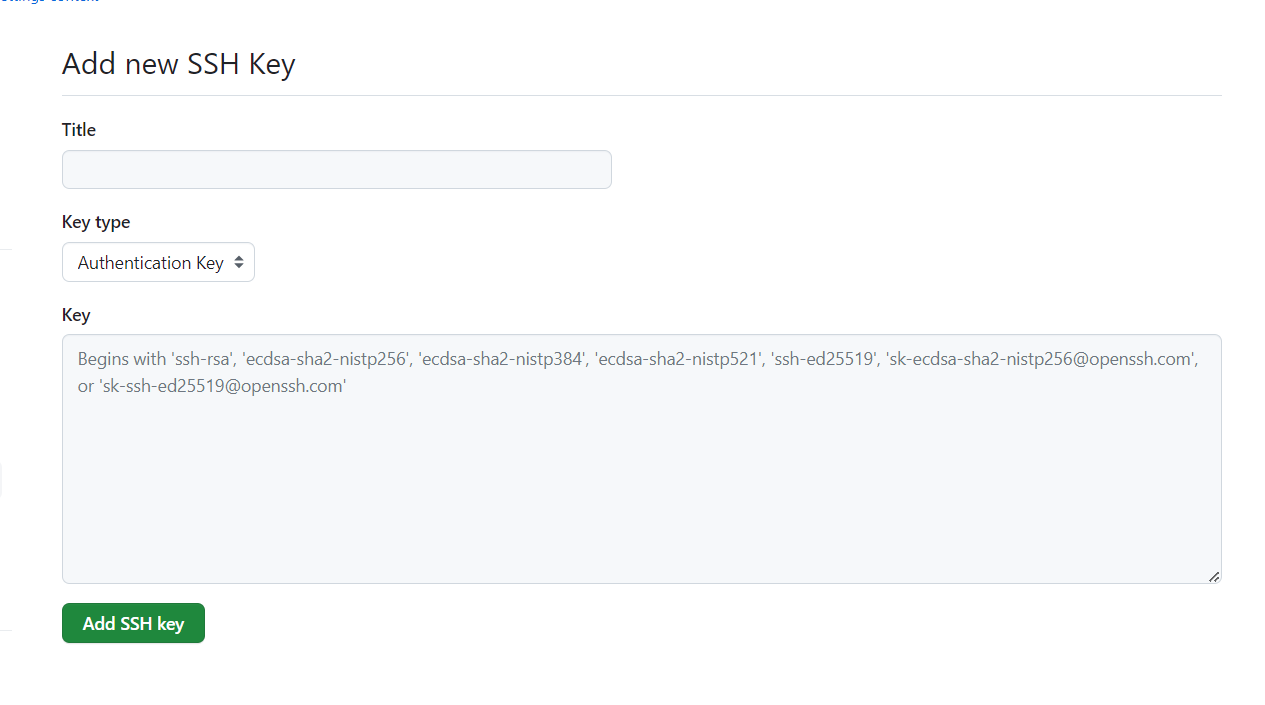
Ahora solo falta revisar la conexión desde la terminal.
Si vez un mensaje similar al siguiente, significa que quedo completa la autenticación.
3.6.4 Paso 4: Push and pull
Una vez que ya tenemos configurado todo, solo falta enviar todo lo que tenemos en el repo local al remoto. Si se establecio la contraseña nos la va a pedir en la terminal o una ventana aparte.
En esa instrucción, origin se refiere al repositorio remoto y main al local (las ramas que estamos intentando poner en el mismo contenido).
La situación en la que estamos es la siguiente:
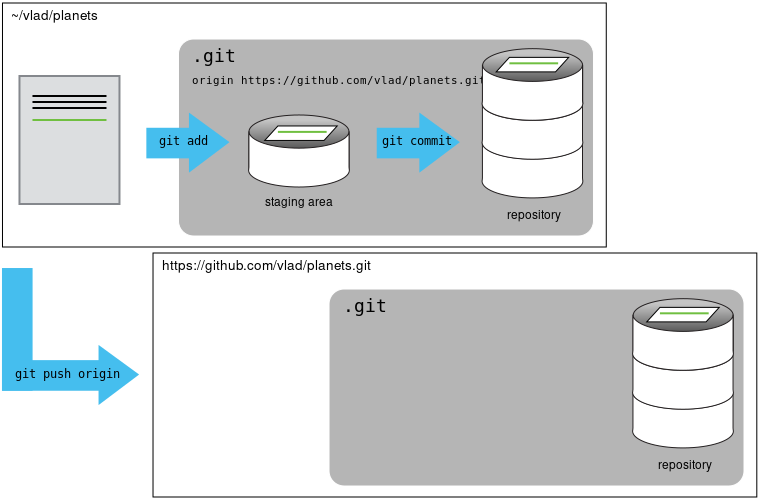
git push origin mainPara actualizar nuestro repositorio local, lo que debemos hacer es lo siguiente:
Como no hemos realizado ningún cambio en el remoto, no veremos nada nuevo en el local. En el remoto también podemos añadir archivos directamente.
Ejercicio: Añade un archivo nuevo desde el repositorio remoto y actualiza tus cambios en el local.
3.7 Colaboradores
Para esta parte, vamos a trabajar en parejas (si no es posible pueden abrir una segunda terminal para la realizar la parte de su equipo).
Vamos a ir a nuestro repositorio que creamos en GitHub y vamos a ir a la configuración y después en donde dice colaboradores.
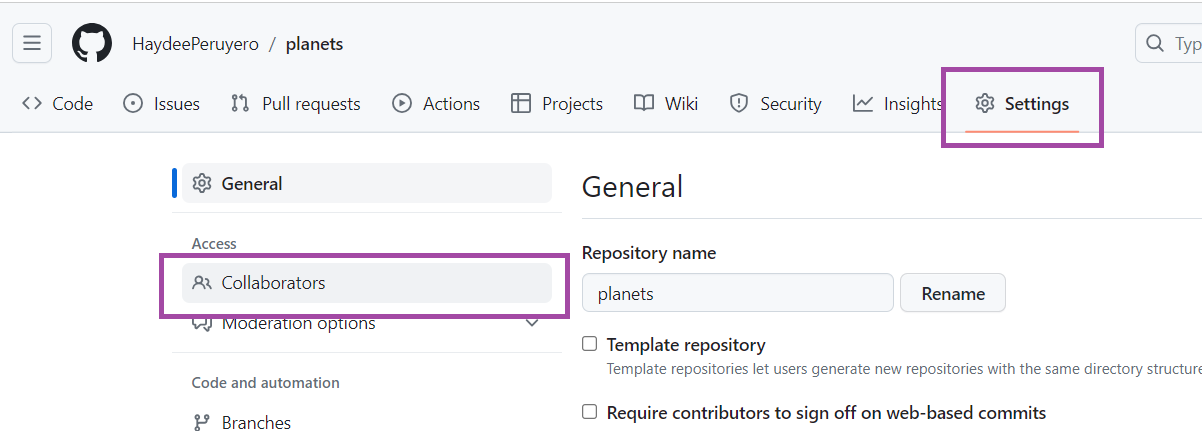
Una vez en esa ventana, den clic en añadir colaboradores. Van a buscar con el nombre de usuario de su compañero y dan enter.
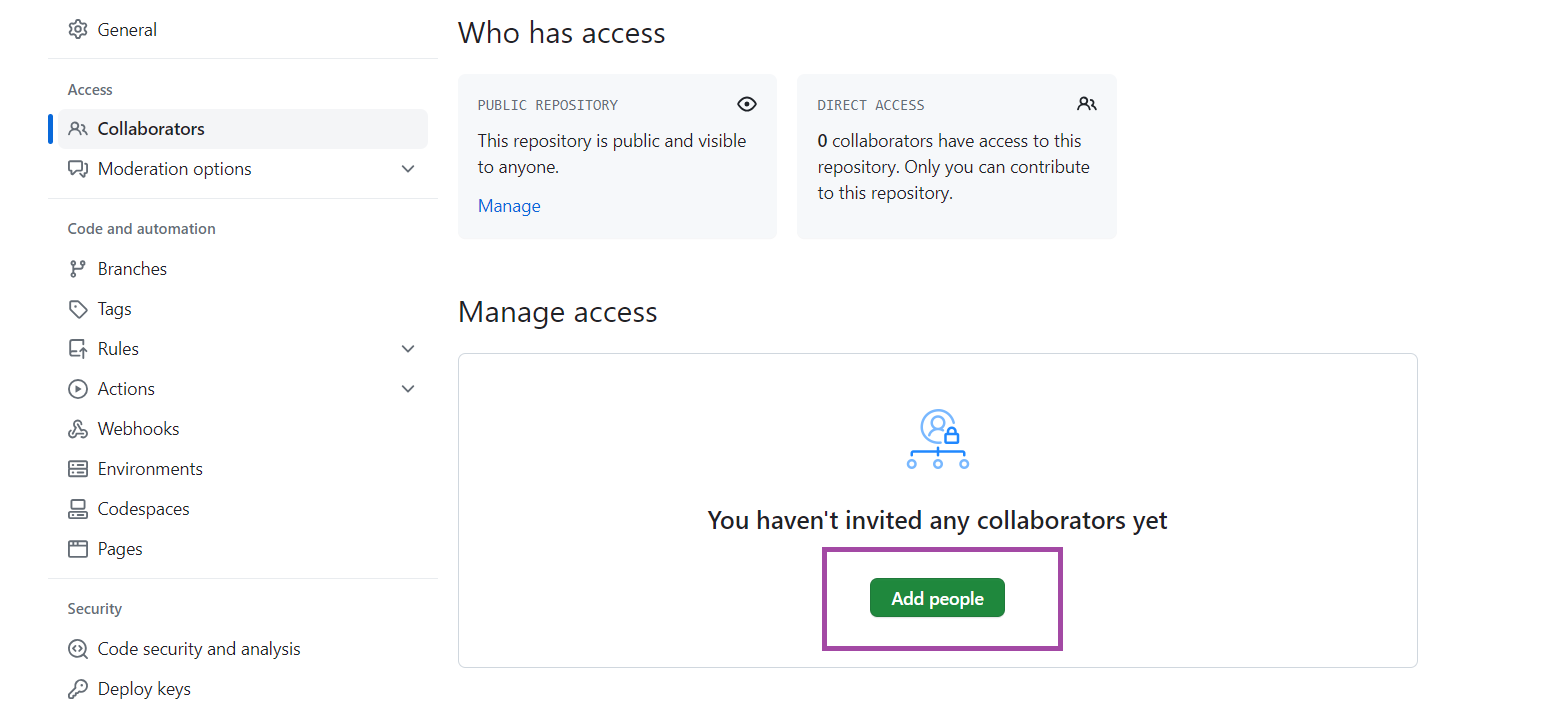
En su correo o cuenta de github, deben ir a notificaciones y aceptar la invitación. También pueden usar el link.
Ahora, su colaborador debe descargar el repositorio a su computadora, a este paso se le llama clonar un repositorio. Para esto, abran una terminal y realicen lo siguiente:
La última parte de esa instrucción es la dirección de su computadora donde se clonara el repositorio de su colaborador.
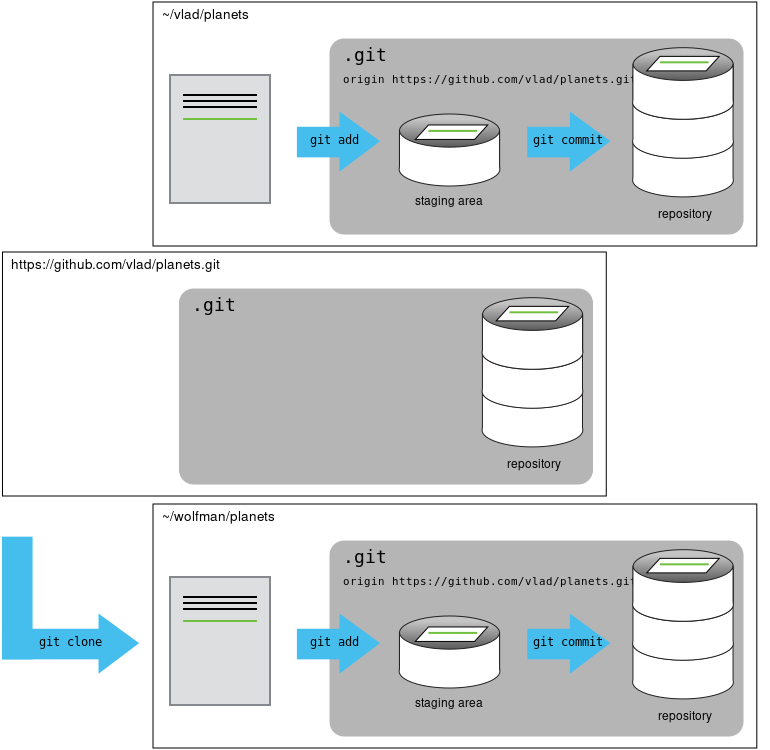
Ahora, el colaborador realizará un cambio en el repositorio. Para esto, creará un archivo, lo añadirá al área de preparación, hará el commit correspondiente y enviará los cambios al remoto.
$ nano notas.txt
$ git add notas.txt
$ git commit -m "Añadimos archivo de colaborador"
$ git push origin mainSi revisamos en la página de Github, veremos ahora un cambio en el repositorio, junto con el commit y quien lo realizo. Finalmente, actualizaremos el repositorio original local con los cambios del colaborador.
Una buena practica cuando se trabaja con colaboradores es realizar la siguiente serie de pasos:
Antes de comenzar a trabajar, siempre actualizar nuestro repositorio local con
git pull origin mainRealizar cambios y añadirlos al área de preparación con
git addRealizar el commit con un mensaje apropiado que nos permita detectar que cambio se realizó.
Actualizar el repositorio remoto con los cambios usando
git push origin main.
Otra buena practica es trabajar con ramas, este sería un paso antes del 2.
Ejercicio: Replicar lo que se hizo en esta sección cambiando roles de quien es el colaborador y quien el dueño del repositorio local.
3.8 Conflictos
Cuando comenzamos a trabajar con colaboradores, es usual que generemos conflictos si no se trabaja de forma adecuada.
Vamos a crear un conflicto para después resolverlo.
El colaborador va a modificar el notas.txt añadiendo algo. Luego lo añadirá al área de preparación, realizará el commit correspondiente y finalmente actualizará el repositorio remoto.
$ nano notas.txt
$ git add notas.txt
$ git commit -m "Modificamos el archivo notas para crear un conflicto"
$ git push origin mainAhora, el dueño del repositorio realizará un cambio también al archivo notas (sin antes actualizar con los últimos cambios del colaborador) y realizará todos los pasos hasta poder actualizar el repositorio remoto.
$ nano notas.txt
$ git add notas.txt
$ git commit -m "Cambios en el archivo notas por el dueño del repositorio"
$ git push origin main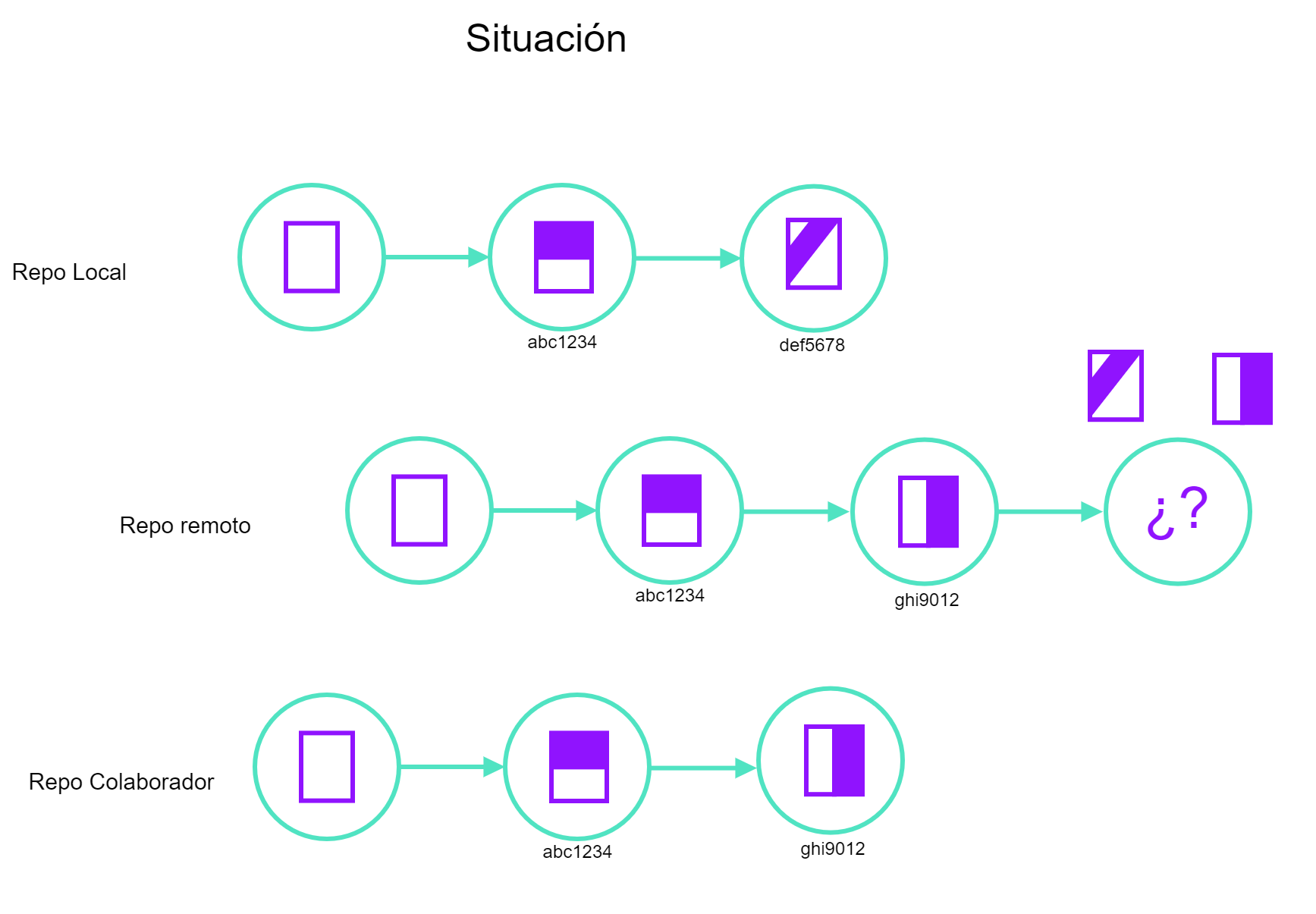
git pushGit no autorizo hacer el push porque había cambios en el remoto que no habíamos actualizado en el local, entonces vamos a actualizar el local primero, hacer un merge en la copia en la que estamos trabajando y después ya hacer un push.
Vamos a ver un mensaje de que hay un merge que no pudo resolver porque se trabajo en la misma línea en el mismo archivo. Si abrimos el archivo vamos a ver algo como lo siguiente:
texto aqui
<<<<<<< HEAD
cambios locales aqui
=======
cambios del colaborador aqui
>>>>>>> dabb4c8c450e8475aee9b14b4383acc99f42af1dAhora lo que tenemos que hacer es decidir que cambios queremos conservar, para eso, podemos borrar nuestros cambios, los del colaborador, ambos, o cambiar todo por algo nuevo (y borrar los identificadores de los conflictos).
Una vez finalizado el merge/resolver conflicto, ya podemos añadirlo al área de preparación, realizar el commit y enviarlo al remoto.
$ git add notas.txt
$ git status
$ git commit -m "Resolvimos el conflicto en el archivo notas"
$ git push origin mainCuando el colaborador intente hacer un git pull no verá ningún conflicto ya que git conservo el registro de que se resolvió y a la copia del colaborador se actualizará sin ningún problema.
Una forma de evitar algunos conflictos es trabajando en ramas, o distribuyendo el trabajo y que cada quien trabaje sobre archivos diferentes.
También se puede dar el caso de que los conflictos sean por archivos con el mismo nombre pero con contenidos totalmente diferentes, por ejemplo con imágenes.
Vamos a crear de nuevo un conflicto con una imagen y vamos a tratar de resolverlo. Tanto el colaborador como el dueño del proyecto va a crear una imagen con el nombre imagen_prueba.jpg, guardará los cambios y realizará todo hasta mandarlo al repositorio remoto.
Lo añadimos al área de preparación, realizamos commit y lo enviamos al repositorio remoto.
El colaborador realizará un push de su imagen al repositorio remoto.
Ahora el dueño del repositorio tratará de hacer un push también al repositorio.
Lo primero que nos va a pasar y decir git, es que no actualizamos nuestro repositorio con los cambios como en el ejercicio anterior. Vamos a hacer un pull.
Nos va a marcar que hay conflictos y que no puede hacer auto merge y nos dirá adicionalmente un mensaje similar al siguiente:
warning: Cannot merge binary files: imagen_prueba.jpg (HEAD vs. 439dc8c08869c343538f6dc4a2b615b05b93c76e)Esto se debe a que como es un archivo que no es de texto no puede empalmar los cambios. Entonces las opciones que tenemos es decidir quedarnos con solo una de las dos imágenes o renombrarlas para quedarnos con ambos.
- Quedarnos con la imagen del dueño del repo:
La imagen del dueño del repo es el HEAD y la del colaborador tiene un id de commit. Entonces procedemos a lo siguiente.
$ git checkout HEAD imagen_prueba.jpg
$ git add imagen_prueba.jpg
$ git commit -m "Usar la imagen del dueño del repo en lugar de la del colaborador"- Quedarnos con la imagen del colaborador del repo:
La imagen del colaborador tiene un id de commit, buscarlo. Entonces procedemos a lo siguiente.
$ git checkout 439dc8c0 imagen_prueba.jpg
$ git add imagen_prueba.jpg
$ git commit -m "Usar la imagen del colaborador del repo en lugar de la del dueño"- Quedarnos con ambas imágenes:
git checkout HEAD imagen_prueba.jpg
$ git mv imagen_prueba.jpg imagen_prueba-dueño.jpg
$ git checkout 439dc8c0 imagen_prueba.jpg
$ mv imagen_prueba.jpg imagen_prueba-colaborador.jpgY finalmente para remover la imagen de prueba y añadir las dos nuevas versiones:
3.9 Trabajando con Ramas
Trabajar con ramas en Git es una parte fundamental del flujo de trabajo colaborativo. Los siguientes pasos son los básicos para trabajar de esta manera.
3.9.1 1. Crear una rama
Cuando trabajas en un proyecto, es una buena práctica crear una rama separada para cada nueva función o corrección de errores que estés desarrollando. Para crear una nueva rama en Git, utiliza el comando:
Este comando crea una nueva rama y te cambia a ella al mismo tiempo.
Otra opción es la siguiente:
3.9.2 2. Trabajar en la rama
Después de crear la rama, puedes comenzar a trabajar en tus cambios. Realiza tus modificaciones en los archivos como lo harías normalmente.
3.9.3 3. Agregar y confirmar cambios
Una vez que hayas realizado cambios que desees incluir en la rama, añádelos al área de preparación con:
Luego, confirma los cambios con un mensaje descriptivo:
3.9.4 4. Empujar la rama al repositorio remoto
Si estás trabajando en un repositorio remoto compartido con otros colaboradores, es posible que desees compartir tus cambios. Para esto, hay dos formas de hacerlo. La primera es enviar los cambios a una rama remota y después confirmarlos y unirlos, para eso utiliza el comando:
Esto enviará la nueva rama y los cambios asociados al repositorio remoto.
3.9.5 5. Fusionar cambios
Una vez que hayas completado tus cambios y estés listo para incorporarlos al proyecto principal, puedes fusionar tu rama con la rama principal (generalmente main o master). Para hacerlo, primero cámbiate a la rama principal:
Otra opción:
Luego, fusiona tu rama con la rama principal:
NOTA: Los pasos 4 y 5 se pueden intercambiar de orden, es decir primero hacer el merge local cambiandonos a la rama principal y después enviando los cambios al remoto. Es importante primero hacer un git pull para actualizar nuestro local en la rama principal.
3.9.6 6. Resolver conflictos (si los hay)
Es posible que ocurran conflictos durante el proceso de fusión si otros colaboradores han realizado cambios en las mismas partes de los archivos. Git te indicará los conflictos y te permitirá resolverlos manualmente.
3.9.7 7. Eliminar la rama (opcional)
Una vez que hayas fusionado tus cambios en la rama principal y ya no necesites la rama de la función, puedes eliminarla:
3.9.8 8. Actualizar y sincronizar
Es importante mantener tu repositorio local actualizado con los cambios de otros colaboradores. Para hacerlo, utiliza:
Esto traerá los últimos cambios de la rama principal del repositorio remoto y los fusionará con tu rama local.
Siguiendo estos pasos, podrás trabajar de manera efectiva con ramas en Git en un entorno colaborativo. Recuerda comunicarte con tus colaboradores y mantener un flujo de trabajo ordenado para evitar conflictos y errores.
3.10 Conectar con overleaf
Lo primero es crear el documento en Overleaf que nos interesa. Después se clona el archivo con la dirección que da Overleaf. Esa será la ruta de la carpeta. De manera local podemos cambiar el propio archivo .tex por uno que ya tengamos (parece que es más fácil hacer esto que intentar crear un nuevo documento en Overleaf a partir un repositorio existente, pero falta hacer más pruebas); también, es posible cambiar el nombre de la carpeta en la cual se generó el repositorio (parece que no hay problemas con Overleaf pero hay que hacer más pruebas).
A continuación los pasos para trabajar localmente una vez que ya se tiene el repositorio creado.
cd ruta_de_la_carpetagit branch nombre_rama_localgit switch nombre_rama_local(o master)git status(para ver cambios)git add .(para añadir los cambios-todos)`git commit -m “nombre del mensaje”``
git switch mastergit pullgit merge nombre_rama_local
git switch nombre_rama_local(b)git merge master(para actualizar ahora rama local) (c) seguir trabajando sobre la misma rama local (d) repetir de 4 a 9
git pushgit branch -d nombre_rama_local