Sección 2 Shell
Descargar git bash para Windows o seguir las instrucciones de Software carpentries para otros sistemas operativos. Basado en la lección de The carpentries
2.1 Navegar en archivos y directorios
Cuando abrimos una terminal por primera vez, vamos a ver un prompt (usualmente es $) que nos indica que esta esperando los comandos. Después de teclear los comandos, debemos siempre presionar Enter.
Para listar lo que hay en un directorio usamos el comando ls.
Documents Downloads Music Pictures VideosAl comando ls le podemos agregar unos adjetivos para hacer más comprensible su lectura. Por ejemplo, la opción -F nos indica si es una carpeta, un archivo, un link, etc.
ej.txt Git/ PBI/ Python/ R/ Shell/ SQL/Con la opción --help podemos acceder a la ayuda del comando.
Otras opciones que nos ayudan a entender la información que tenemos en el archivo son -lh, nos muestra los permisos del archivo o carpeta, tamaño, propietario, fecha, nombre. La opción ls -a nos muestra los archivos ocultos.
Ejercicio: ¿Qué hace la opción -l? ¿Cómo podemos listar en orden de creación e inverso?
Con el comando ls también podemos listar los archivos de cualquier otro directorio, solo debemos indicarle el directorio después del comando:
El comando ls solo nos esta listando lo que hay en los directorios. Si nos queremos mover a otro directorio, lo podemos hacer con el comando cd y especificando el directorio.
data/ ej1.txt ejercicios/El comando pwd nos da la ruta en la que estamos.
/d/Users/hayde/Documents/Curso_Comp_Cien/ShellPara movernos a un directorio arriba, colocamos después de cd dos puntos.
Si no colocamos los dos puntos, el comando cd nos lleva al /home/.
Otra forma de movernos de un directorio a otro es especificando la ruta absoluta, es decir la ruta completa de a donde queremos movernos.
Ejercicio: ¿Qué es una ruta relativa?
Otro opción útil que podemos usar con el comando cd es -.
Ejercicio: ¿A donde nos lleva cd -? y si volvemos a colocar cd - ¿a donde nos lleva? ¿Cuál es la diferencia entre cd .. y cd -?
La tilde ~, shell la interpreta como el home del usuario, entonces si colocamos cd ~/directorio sería lo mismo que /home/directorio. Por ejemplo:
es lo mismo que
Ejercicio: Supongamos que tenemos el siguiente árbol de datos en nuestra computadora y que estamos en /Users/thing/. ¿Si colocamos en la terminal ls -F ../backup que nos mostrará?
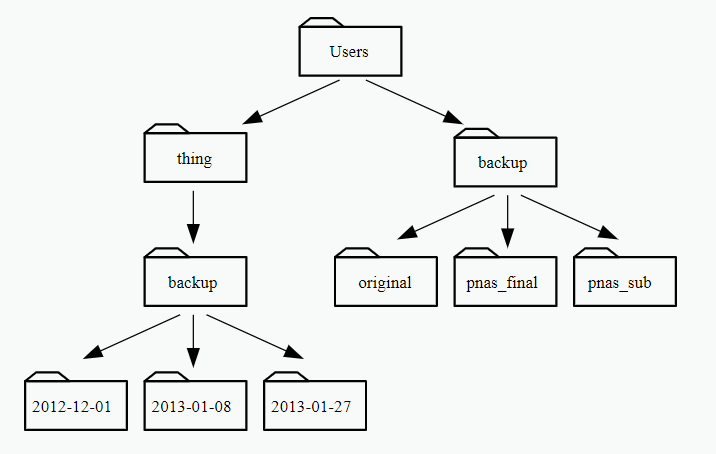
Ejercicio: Explora las opciones -s y -S. ¿Hay diferencia entre mayúsculas y minúsculas?
La tecla Tab nos ayuda a completar los comando/rutas. Si la presionamos dos veces nos mostrará todas las posibles opciones.
2.2 Manipulación de archivos y directorios
Para crear directorios/carpetas desde la línea de comandos usamos el comando mkdir nombre. Vamos a crear la carpeta del curso. Es recomendable no usar espacios en nombres de carpetas ni archivos.
El comando mkdir nos permite crear más de un directorio y directorios anidados usando la opción -p.
Para listar toda la estructura de nuestras carpetas podemos usar la opción -FR en el comando ls.
Otra opción útil para listar toda la estructura de nuestro directorio es la opción tree, no viene instalado por default en los sistemas operativos. En Windows, si se instalo git/bash se puede usar con tree.com.
Nota: Para descargar tree y que podamos ver la estructura de árbol con archivos y carpetas hacer lo siguiente:
Ir a la página y descargar la versión que dice binaries.
Extraer lo que hay en la carpeta bin.
Copiar el archivo tree.exe a la carpeta
/c/Program_files/Git/usr/bin/.Para probarlo, solo colocar en la terminal
tree ruta.
Para crear un archivo usando el editor nano (si fue el que configuraron), se usa el comando nano nombre.extension.
Vamos a crear un archivo de prueba en la carpeta ejercicios y escribamos algo en el archivo.
Para guardar y salir del editor, usamos los comandos Ctrl+O o Ctrl+X seguido de Yes y enter.
Si en el archivo no guardaron nada, entonces no se creara. Una forma de crear archivos sin abrirlos es con el comando touch.
Si checamos con ls -l los archivos o rutas que creamos, veremos que no tienen ningún tamaño.
Para mover archivos o renombrarlos, usamos el comando mv seguido del archivo que queremos mover/renombrar y la ruta a donde lo moveremos o el nuevo nombre del archivo.
Lo anterior esta cambiándole el nombre al archivo ej2.txt por ejercicio2.txt.
Si estamos en un directorio y queremos mover un archivo de otro directorio al directorio actual, podemos hacerlo especificando como primer argumento la ruta y nombre del archivo a mover y como segundo argumento un punto ..
O especificando la ruta completa.
Para copiar archivos, usamos el comando cp seguido por la ruta del archivo a copiar y la ruta del archivo a donde se copiará. Movámonos a la carpeta Shell/ejercicios.
Si usamos la opción -r (recursivo) en el comando cp podemos copiar un directorio completo y todos sus elementos.
Si el último parámetro de cp es un directorio que ya existe, entonces copiará todos los archivos que se indiquen a ese directorio. Por ejemplo:
De igual forma para mv, si el último parámetro es un directorio movera todos los archivos a ese directorio.
Ejercicio: ¿Cual es el output de la siguiente colección de comandos?
/Users/haydee/Cursoarchivo.txt carpeta/$ mkdir carpeta2
$ mv archivo.txt carpeta2/
$ cd carpeta2
$ cp archivo.txt ../carpeta/archivo_respaldo.txt
$ cd ..
$ ls -FRPara borrar archivos usamos el comando rm, hay que tener cuidado cuando lo usemos ya que borra definitivamente los archivos o carpetas.
Una forma segura de borrar archivos es usando la opción -i, con esto nos saldrá un mensaje preguntando si en verdad deseamos borrar el archivo. Para confirmar debemos colocar y.
rm: remove regular empty file 'ej3.txt'?Si queremos borrar una carpeta, debemos hacerlo con la opción -r, de lo contrario obtendremos un error.
Otra opción para borrar directorios es rmdir.
Para mover/copiar/eliminar multiples archivos a la vez, podemos enumerarlos todos o usar comodines/patrones que sigan estos elementos. Supongamos que tenemos una lista de archivos todos con terminación .txt, entonces para borrarlos podemos usar rm *.txt. El * nos indica todo lo que este antes de .txt.
Otro comodín que podemos usar es ?, pero este denota solo 1 espacio. Por ejemplo:
Ejercicio: Supon que en el directorio data tienes dos archivos. ¿Cuál de los siguientes comandos te daría como resultado: ethane.pdb methane.pdb.
ls *t*ane.pdbls *t?ne.*ls *t??ne.pdbls ethane.*
Dos comodines más que existen son los siguientes:
[...]: busca coincidencias con exactamente cada caracter dentro de los corchetes, por ejemplo[12]coincidiria contexto1.txt,texto2.txpero no contexto3.txt.{...}: busca coincidencias con cada uno de los elementos separados por comas dentro de las llaves, por ejemplo{*.txt, *.csv}buscaría todos los archivos con terminaciones.txty.csvpero no con los que sean.pdf.
2.3 Tuberías y filtros
Vamos a usar los archivos de prueba de la lección de Shell de Software Carpentry. Descargarlos en el directorio que creamos que se llama Shell.
Vamos a explorar los archivos que están en la carpeta excercise-data/alkanes. Para contar cuantos palabras, líneas o caracteres tiene un archivo, usamos el comando wc que viene de word count.
cubane.pdb ethane.pdb methane.pdb octane.pdb pentane.pdb propane.pdb20 156 1158 cubane.pdbEl primer número es el número de líneas del archivo, el segundo la cantidad de palabras y el tercero la cantidad de caracteres.
Si usamos alguna de los comodines, por ejemplo *.pdb con el comando wc, nos va a regresar la información de todos los archivos.
Notemos que en la última fila tenemos los totales de todos los archivos. Accedamos a la ayuda del comando con help.
Ejercicio: ¿Cuál opción nos permite extraer solo la cantidad de líneas del archivo?
Si por error olvidamos colocar el nombre del archivo o cualquier otra cosa después del comando, la consola se quedará esperando una instrucción, para salir de esto basta presionar Ctrl+C.
Ya sabemos como extraer cierta información de nuestros archivos, pero supongamos que queremos guardarlo ahora en algún otro archivo para después analizarlo. El símbolo > redirige el resultado de los comandos usados a algún archivo.
Para solo visualizar el contenido de un archivo sin entrar al editor de texto, podemos usar el comando cat seguido del nombre del archivo.
Otro comando que puede resultar más útil para mostrar el contenido de un archivo es less, la diferencia con cat es que este último muestra todo el contenido en la pantalla, lo cual puede dificultar su lectura e inspección, mientras que less muestra una parte del contenido y de forma ordenada, si queremos seguir viendo el contenido podemos usar la tecla de espacio, b y para salir usamos la letra q.
Ya guardamos la información de la cantidad de líneas, pero supongamos que queremos saber cual archivo tiene la mayor cantidad de líneas o menor. Para hacer esto nos sirve el comando sort.
Si a sort le agregamos la opción -n, nos los ordena en numericamente en lugar de alfabeticamente.
Ejercicio: De los archivos que están en la carpeta alkane, ¿cuál tiene la menor cantidad de líneas?
También podemos redirigir esta información a otro archivo y de ahí extraer la información.
El comando head nos ayuda a extraer las primeras n líneas de nuestro archivo. Por ejemplo, para extraer la primera línea del archivo lineas_ordenadas.txt y así saber cual archivo tenía la menor cantidad de líneas usaríamos head -n 1.
El comando echo nos ayuda a imprimir en la consola caracteres.
Ejercicio: Realiza las siguientes instrucciones dos veces cada una. Explora las diferencias. ¿Qué hace el operador >>?
El comando tail es similar al comando head, nos muestra las últimas n filas del archivo.
Ejercicio: Considera el archivo /exercise-data/animal-counts/animals.csv. Después de aplicar los siguientes dos comandos, ¿qué hay en el archivo animals-subset.csv?
2.3.1 Tuberías
Además de redirigir los output de los comandos que hemos ocupado, también podríamos anidarlos y al final mandarlo a un archivo. Para hacer esto se usan tuberías y su símbolo es |. Por ejemplo:
En esta instrucción le estamos diciendo a la consola que primero nos ordene lo que hay en el archivo líneas en orden númerico y después que nos muestre la primera línea. De esta forma nos evitamos por ejemplo el haber creado el archivo lineas_ordenadas.txt.
Podemos anidar varias instrucciones a la vez. Por ejemplo, podríamos pedirle a la consola la cantidad de líneas de los archivos *.pdb, pedirle que las ordene numericamente y después que extraiga la primera línea.
Ejercicio: De los archivos que están en la carpeta alkanes, obten los 3 archivos con la menor cantidad de líneas.
Ejercicio: Explora el archivo exercise-data/animals-counts/animals.csv. ¿Cuál será el resultado de la siguiente instrucción?
El comando cut nos ayuda a extrar/cortar ciertas columnas de nuestros archivos. Por ejemplo, cut -d , -f 2 archivo nos está indicando que del archivo queremos cortar por caracteres , (eso hace -d ,) y que queremos extraer la segunda columna (-f 2).
Si quisieramos extraer los animales únicos de ese archivo, podemos usar el comando uniq.
También se puede colocar por ejemplo -f 2-5,8 para indicar que se deben seleccionar las columnas 2 a la 5 y la 8.
Ejercicio: ¿Porqué se necesita colocar el sort antes del uniq?
Ejercicio: Si quisiéramos ver cuantos animales hay de cada tipo, ¿que instrucción tendríamos que usar?
2.4 Ciclos
Los ciclos nos ayudan a repetir comandos o un conjunto de comandos para cada elemento de una lista. La estructura del ciclo for es como sigue:
La palabra for indica el comienzo del ciclo, la palabra do nos indica que es lo que se va a ejecutar y su comienzo y la palabra done indica el fin del ciclo.
Exploremos lo que hay en la carpeta ~/Shell/shell-lesson-data/exercise-data/creatures. Listemos las primeras 5 filas de cada archivo.
Supongamos que queremos ver la clasificación de cada especie que se encuentra en la segunda línea de cada archivo. Una forma de hacerlo es con head -n 2, pero de esta forma también estamos viendo su nombre común, entonces vamos a hacerlo con un ciclo. Lo primero que tendríamos que hacer es usar justo head -n 2 y al resultado de esto, si le pedimos la última línea ya solo veríamos la clasificación, entonces usamos un tail -n 1.
Notemos que cuando empezamos a teclear nuestro ciclo, el prompt cambia de $ a >, esto indica que está esperando que continuemos el ciclo. También podemos usar ; para continuar las instrucciones en una misma fila.
Dentro de los ciclos, las variables las mandamos a llamar con $, en el ejemplo, cuando ocupamos $filename estamos mandando a llamar la variable filename que definimos al inicio del ciclo. Es muy usual también encerrar entre llaves los nombres de las variables para delimitar el nombre, en el ejemplo, $filename sería equivalente a ${filename}.
Ejercicio: Crea un ciclo que muestre en pantalla (echo) todos los números del 0 al 9.
Ejercicio: Ve a la carpeta shell-lesson-data/exercise-data/alkanes y lista lo que hay.
1) ¿Cuál es el output del siguiente código?
- ¿Y de este código?
Explica las diferencias.
Ejercicio: En el directorio shell-lesson-data/exercise-data/alkanes, ¿cuál sería el output del siguiente código?
Y si en lugar de c* usamos c?
Dentro de un ciclo también podemos pedir guardar archivos.
Ejercicio: Explora el siguiente código. ¿Cuál es el efecto de guardar en este ciclo?
¿Cuál sería la diferencia si usamos ahora >>?
Ejercicio: Crea un ciclo que muestre las últimas 20 líneas de cada archivo en la carpeta creatures.
Como ya mencionamos, no es recomendable usar espacios ni caracteres especiales en nombres de archivos o carpetas. Si fuera el caso de que nuestros archivos tienen espacios, entonces deberíamos pasarlos al ciclo for encerrados entre comillas los nombres. Por ejemplo, supongamos que tenemos los archivos archivo 1.txt y archivo 2.txt. Para leerlos en el ciclo for tendríamos que usar la siguiente sintaxis.
Supongamos que queremos modificar nuestros archivos que se encuentran en la carpeta creatures pero que antes queremos respaldarlos en otros archivos llamados original-basilisk.dat, original-unicorn.dat y original-minotaur.dat. Una forma de hacerlo sería copiarlos a nuevos archivos con esos nombres, pero si no lo queremos hacer manualmente, ¿qué pasa si usamos el siguiente código?
Esto nos va a dar un error porque el comando cp estaría esperando que original- sea una carpeta y no lo es, no existe esa carpeta. Entonces lo que podemos hacer es usar un ciclo.
Ejercicio: Crea un ciclo for que copie los dos archivos a dos nuevos archivos llamados original-basilisk.dat, original-unicorn.dat y original-minotaur.dat.
El comando cp no nos muestra en pantalla ningún output. Si quisieramos ver que en efecto se esta realizando la copia de estos archivos podemos usar el comando echo y pedir que nos diga como “se copio el archivo $filename”. Usar echo de esta forma es una buena práctica de realizar lo que se llama debugging.
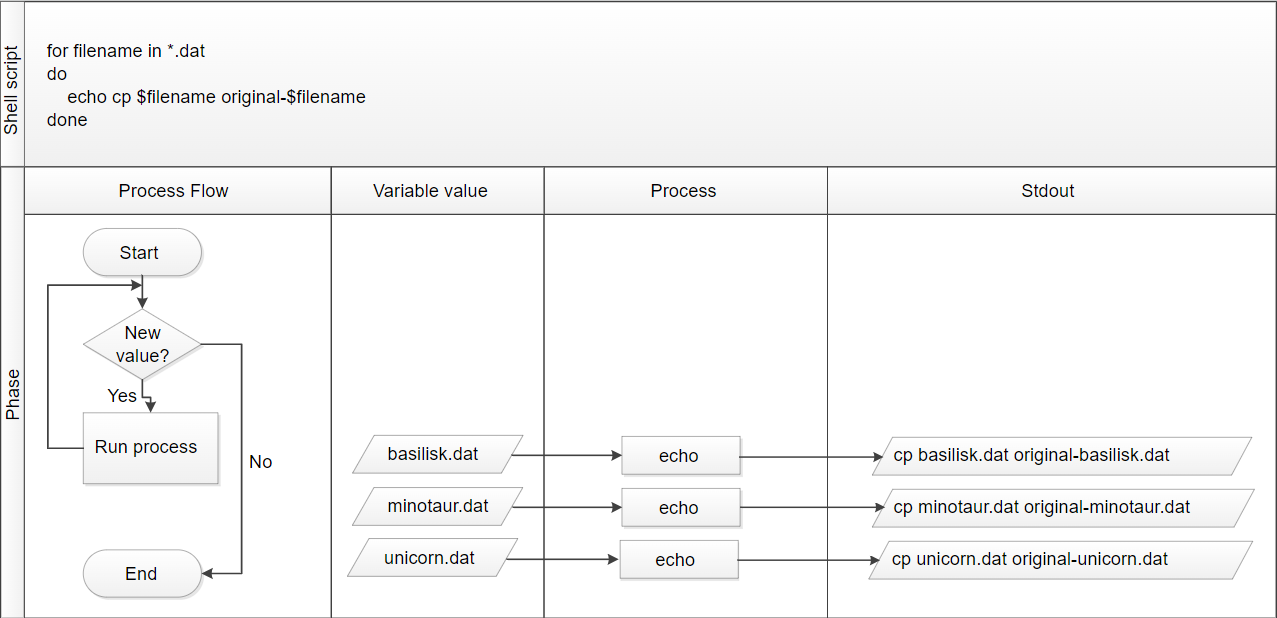
Ejercicio: Supongamos que queremos previsualizar los comandos que el siguiente ciclo va a realizar en lugar de correrlo primero para asegurarnos de que está haciendo lo que queremos.
¿Cuál de los siguientes dos códigos sería el correcto para revisar los comando a ejecutarse con el ciclo?
Corre los dos códigos y explora el contenido del archivo all.pdb.
Supongamos que queremos crear una estructura de directorios como sigue, para cada compuesto y cada temperatura queremos una carpeta para ir guardando ahí sus resultados, y que cada carpeta se llame compuesto-temperatura, ¿cómo podemos hacer esto? Una opción son los ciclos anidados.
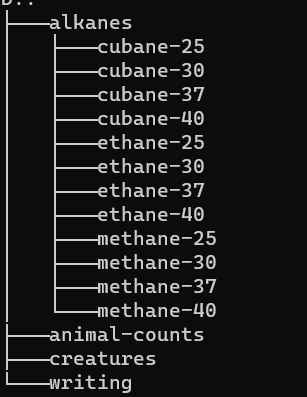
$ for species in cubane ethane methane
> do
> for temperature in 25 30 37 40
> do
> mkdir $species-$temperature
> done
> doneAlgunos comandos útiles para ver el historial de comadnos.
historynos muestra el historial de comandos.Ctrl+R nos muestra la leyenda
reverse-i-search, esto indica que está esperando que nosotros coloquemos una palabra y buscará por el último comando con esa palabra.history+!123nos repetirá el comando!123del historial.!!nos muestra el último comando usado.!$nos regresa la última palabra del último comando.
Ejercicio: En la carpeta norht-pacific-gyre se encuentran dos scripts (.sh) y una lista de archivos. Esta lista de archivos tiene terminaciones A, B y en el caso de que la terminación sea Z significa que el archivo está corrupto.
- ¿Cómo podrías darte cuenta que los archivos con terminación Z están corruptos?
Supongamos que queremos ejecutar el script llamado goostats.sh, este script necesita recibir dos cosas, el archivo de entrada y el nombre del archivo de salida. Supongamos que queremos correr este script para todos los archivos con terminación A y B y que queremos que los archivos de salida se llamen stats-$datafile.
Crea un ciclo que te muestre en pantalla el nombre del archivo a usar como input.
Crea un ciclo que te muestre en pantalla el nombre del archivo de salida con el formato indicado. Pero quieres asegurarte que para el archivo input sea el nombre correcto el del archivo de salida.
Crea un ciclo que muestre los comandos a usarse para correr el script con los archivos de entrada y de salida del paso 2 y 3. Para correr un script como se indica, se usa el comando
bash nombre_archivo.sh input output.Agrega un
echo $datafilepara saber en que archivo va tu ciclo.
2.5 Scripts
Los scripts nos ayudan a repetir los comandos sobre listas de archivos. Supongamos que existen ciertos comando que siempre repetimos, vamos a guardarlos en un archivo para con un solo comando ejecutar esa lista de comandos.
Vamos al directorio alkanes. Supongamos que siempre queremos extraer las líneas de la 11 a la 15 de cada archivo. Por ejemplo, una forma en la que lo hacemos es:
Vamos a escribir eso en un archivo:
Guardemos eso. Para ejecutarlo bastaría correr lo siguiente:
Supongamos que queremos las líneas de la 11 a la 15 pero de cualquier otro archivo. Vamos a modificar el archivo que creamos.
En el script, cuando colocamos "$1" se refiere al primer argumento/archivo en la línea de comandos, por ejemplo cuando colocamos en la línea de comandos:
Lo que estamos diciéndole a la consola es que reemplace dentro del script “$1” por el archivo octane.pdb. De esta forma nuestro script ahora lo podemos correr sobre cualquier archivo.
Nuestro script por el momento funciona solo con las líneas de la 11 a la 15. Supongamos que queremos modificar esto de tal forma que cuando vayamos a ejecutar el script le indiquemos las líneas que queremos extraer. Así como usamos $1 para indicarle que era la primera variable en la línea de comandos, podemos usar las variables $2 y $3 para indicarle la segunda y tercera variable.
Entonces podemos ejecutar el script como sigue:
Y podemos cambiar las líneas a mostrar, por ejemplo:
Lo único que falta en el script, es describir que hace, de esta forma cualquier otra persona (o nosotros más adelante), cuando queramos abrir el script podamos recordar y entender que argumentos pide y cual es su uso.
# Selecciona líneas intermedias de un archivo.
# Uso: bash middle.sh nombre_archivo linea_final linea_inicial
head -n "$2" "$1" | tail -n "$3"Ahora, supongamos que queremos ordenar los archivos .pdb por cantidad de líneas. Sin un script eso lo hacemos así:
Si queremos poner esto en un script pero queremos correrlo sobre varios tipos de archivos, digamos los .pdb y los .dat, no podemos colocar en nuestro script *.pdb, y si usamos como en los ejemplos anteriores "$1" o "$2, eso limitaría la cantidad de archivos que podemos pasarle después en la consola. Una forma de no depender de eso es con la variable $@, esto indica que pueden ser cualquier cantidad de argumentos en la línea de comandos.
Ejercicio: El archivo animals.csv ya vimos que es un archivo separado por comas que indica las especies y la cantidad de cada uno. Crea un script que se pueda aplicar a cualquier cantidad de archivos con ese formato y que te diga las especies únicas de cada archivo.
Crea 3 archivos similares al animals.csv (copia y modifica) y prueba tu script.
Ejercicio: Corre el siguiente comando:
¿Qué contiene ese archivo? ¿Observa la última línea del archivo? ¿Porqué guarda esa línea?
Ejercicio: En la carpeta alkanes supongamos que tenemos un script.sh que contiene lo siguiente:
Dentro del directorio alkanes, corre lo siguiente:
¿Qué esperas obtener?
Ejercicio: Crea un script llamado longest.sh que reciba como argumentos un directorio y una extensión de archivos y que te devuelva el archivo en el directorio, que tenga esa extensión, con el mayor número de líneas.
Ejercicio: Considera los archivos que están en la carpeta alkanes. Explica que hace cada uno de los siguientes scripts al correrlos como bash script1.sh *.pdb, bash script2.sh *.pdb y bash script3.sh *.pdb.
Ejercicio: (Debugging) Supongamos que tienen el siguiente script do-errors.sh en la carpeta north-pacific-gyre:
# Calcular estadisticas para los archivos
for datafile in "$@"
do
echo $datafile
bash goostats.sh $datfile stats-$datafile
doneCorre en la línea de comandos:
No muestra ninguna salida. Para ver porque, vamos a correrlo de nuevo con la opción -x:
¿Cuál es el output? ¿Cuál es la línea responsable del error?
Otra asignación de variables es #@, esto nos indica cuantos objetos hay de la variable.
Tres conceptos usados en bash son los siguientes:
STDIN: estándar input
STDOUT: estándar output
STDERR: estándar error
Para redirigir el error y el output automáticamente a archivos, usamos las opciones:
O dentro de un script:
Al inicio de un script se suele colocar #!/usr/bash para que el interprete sepa que es un script de bash y use el bash que se encuentra en usr/bash. Si no está ahí se coloca la ruta correspondiente, para saber donde está usamos which bash.
2.6 Buscando y encontrando cosas
La función grep (global/regular expression/print) nos ayuda a encontrar e imprimir líneas de archivos que contengan un patrón especificado.
Vamos a la ruta excercise-data/writing.
Para buscar las líneas que contienen la palabra not, la instrucción sería la siguiente:
El comando grep es sensible a mayúsculas y minúsculas. Si buscáramos por ejemplo Not no nos encontraría ninguna coincidencia.
Observemos que ahora nos está regresando una palabra que contiene The en su estructura: Thesis. Para restringir a que solo sean coincidencias exactas, usamos la bandera -w.
En el caso de querer buscar frases, debemos encerrarlas entre comillas.
Si agregamos la opción -n, esto nos mostrará también la línea en la que se encuentra la coincidencia.
Las banderas se pueden combinar, por ejemplo -nw (-wn o -n -w) nos buscaría coincidencias exactas y los números de líneas.
Para que no nos importe mayúsculas o minúsculas, usamos la opción -i.
La opción -v es para invertir nuestra búsqueda, es decir para mostrarnos las líneas que no contienen esa palabra/frase.
La opción -r busca recursivamente por la coincidencia en un conjunto de archivos indicados.
Ejercicio: ¿Cómo obtendrían solo lo siguiente del archivo haiku.txt?
Dentro del comando grep también podemos usar comodines (expresiones regulares), por ejemplo:
El ^ se refiere al inicio de la línea, el . se refiere a un carácter (análogo a ?), entonces estaría buscando todas las líneas una palabra donde su segunda letra sea la letra o.
Ejercicio: El archivo que se encuentra en la carpeta animal-counts/animals.csv contiene una lista de animales, con su fecha de observación y cuantos animales se observaron.
2012-11-05,deer,5
2012-11-05,rabbit,22
2012-11-05,raccoon,7
2012-11-06,rabbit,19
2012-11-06,deer,2
2012-11-06,fox,4
2012-11-07,rabbit,16
2012-11-07,bear,1Supongamos que queremos crear un script que tome como primer argumento la especie del animal y como segundo argumento el directorio. El script nos debe regresar un archivo llamado <especie>.txt que contenga una lista de fechas y el número de veces que se observo esa especie. Por ejemplo, rabbit.txt tendría que contener la siguiente información:
Usa las opciones de ayuda de los comandos cut y grep (puedes usar man grep o man cut también para pedir ayuda de esos comandos, la palabra man se refiere a manual.)
Ejercicio: En la carpeta exercise-data/writing se encuentra el texto completo de Mujercitas LittleWomen.txt. Usando un for encuentra que hermana aparece más veces: Jo, Meg, Beth, Amy.
No solo podemos buscar una sola palabra, podríamos buscar dos palabras o buscar entre dos palabras:
Ejercicio: ¿Cómo podrías mostrar en color lo que estás buscando? Explora la ayuda de grep.
Para buscar entre directorios, usamos el comando find. Por ejemplo, el siguiente comando nos encontrará todo lo que este en directorio actual
La opción -type d nos mostrará solo carpetas.
Y con la opción -type f nos mostrará todos los archivos.
Si queremos encontrar algo que concuerde con algún nombre:
Hay que tener cuidado con esta instrucción, find expande los comodines antes de correr los comandos, en el caso de tener más de un archivo veremos un mensaje de error. Para prevenir esto y que si busque todos los archivos, debemos encerrar el patrón entre comillas.
Podemos hacer tuberías también con este comando, por ejemplo si quisieramos contar cuantas líneas tienen todos los archivos con terminación txt, podríamos hacer lo siguiente:
Otro ejemplo:
Ejercicio: La opción -v en grep busca todo lo que no concuerde con el patrón indicado. En la carpeta creatures, ¿cómo listarías todos los archivos que terminen en .dat menos el que se llama unicorn?
2.7 if, while y for
Ya vimos que la sintaxis del ciclo for es como sigue:
Una forma de crear una lista es como sigue:
Usando esta sintaxis, el código para listar todos los números del uno al 9 quedaría:
Otra forma de escribir la lista sería con la sintaxis ((x=1;x<=9;x+=1)).
La estructura del ciclo if es como sigue:
También se puede usar la estructura ((condicion)).
Los operadores aritméticos en el condicional if que se pueden usar son los siguientes:
\(>\), \(<\), \(==\), \(!=\)
-eq,-ne: igual y no igual a (equal to, not equal to).-lt,-le: para menor que o menor o igual que (less than,less than or equal to).-gt,-ge: para mayor que o mayor o igual que (greater than, greater than or equal to).
Otros banderas para los condicionales las pueden encontrar en el siguiente link.
La notación && es para un Y y la notación || para un O, las cuales nos sirven para verificar más de una condición:
También podemos usar la siguiente estructura: [[ $x -gt 5 && $x -lt 10]].
Dentro de un if podemos pedir que nos busque en algún archivo combinandolo con grep, dentro de la carpeta animal-count:
El mismo resultado lo podemos obtener como sigue:
El ciclo while tiene la misma estructura del ciclo for y los operadores aritméticos son los mismos que en el if. Siempre recuerden poner un fin al ciclo para que no sea infinito.
Aparte de estos ciclos, existen los CASE Statements, los cuales pueden llegar a ser más útiles que los if cuando se tienen condiciones muy complicadas. Su estructura es la siguiente:
$ case 'String' in
> patron1)
> comando1;;
> patron2)
> comando2;;
> *)
> comando por default;;
> esacPor ejemplo:
#!/bin/bash
#Control de flujo: case
echo "Escribe una frase"
read frase
case $frase in
a*)
echo "La frase empieza con a"
;;
c*t)
echo "La frase empieza con c y termina con t"
;;
*com)
echo "La frase termina con la cadena com"
;;
*)
echo "La frase no cumple con ninguna de las condiciones"
;;
esacSi corremos este script en la terminal con bash case_ejemplo.sh veremos que dependiendo de la frase que coloquemos en la terminal, nos arrojará una de las opciones.
Ejercicio: Crea un case statement para adivinar tu edad. Debes pedirle al usuario que introduzca el número correspondiente a tu edad y que los casos o patrones obtengan por resultado una frase referente a si adivinaron o no su edad. Realiza lo mismo con un if.
2.8 Descarga y limpieza de bases de datos
wget: es una herramienta de línea de comandos para descargar archivos desde servidores web mediante HTTP, HTTPS y FTP.
Por ejemplo:
wget https://raw.githubusercontent.com/HaydeePeruyero/Computo_Cientifico/main/data/charactersStats.csvcurl: es otra herramienta de línea de comandos para transferir datos desde o hacia un servidor. Es muy versátil y puede manejar varios protocolos.
Por ejemplo:
curl -O https://raw.githubusercontent.com/HaydeePeruyero/Computo_Cientifico/main/data/charactersStats.csvftp: Si el archivo está disponible a través de FTP, puedes usar el cliente FTP de la línea de comandos para descargarlo.
Por ejemplo:
scp: Si el archivo está en un servidor remoto al que tienes acceso SSH, puedes usarscppara descargarlo de forma segura.
Por ejemplo:
rsync: Si necesitas sincronizar archivos o directorios entre sistemas,rsynces una opción muy poderosa.
Por ejemplo: