Sección 4 Bases de datos en R
El manejo de bases de datos es uno de los puntos clave o principales al momento de realizar un análisis de datos. En ocasiones, lo más díficil es tener una base de datos que sea posible manipular. El primer paso es tener una base de datos, después importarla a R y manipularla de tal forma que podamos trabajar con ella. En la primera parte del curso, comenzamos a trabajar con objetos data.frame, otro tipo de objetos son los data.table que tienen mejor poder de procesamiento y los tibbles que incorporan otras características a los datos y que pueden ser de ayuda.
4.1 Manejo de bases de datos
Para importar un archivo .csv recordemos que usamos read.csv(), esta función nos permite indicarle si tiene encabezados con header= TRUE, el tipo de delimitadores con sep=";" entre otras opciones.
Para exportar un data frame usamos la función write.csv().
Otros tipos de archivos que podemos cargar son .txt, .dat, .tsv y podemos usar las funciones read.table() o read.delm().
Otro paquete que se puede usar es library(readr). En este, se encuentran funciones como read_csv() para leer archivos delimitados por ,, está la función read_csv2() para leer archivos delimitados por ;, la función read_tsv() para archivos separados por tabulador y read_delim() para especificar los delimitadores. La función read_csv() nos imprime en pantalla el tipo de columnas de la base de datos, a esta función le podemos pasar un archivo csv o podemos darle línea por línea el archivo, y por default considerará la primera línea como los nombres de las columnas.
## # A tibble: 2 × 3
## x y z
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 6Si queremos evitar las primeras líneas, podemos usar el argumento skip = n o indicarle que lo que está con # es un comentario y no va en la base de datos.
## Rows: 2 Columns: 3
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (3): a, b, c
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## # A tibble: 2 × 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 6## Rows: 2 Columns: 3
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (3): a, b, c
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## # A tibble: 2 × 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 6El paquete data.table nos ayuda a optimizar el guardar e importar grandes bases de datos. Las funciones para importar o guardar las bases de datos en este paquete son fread() y fwrite. Estas funciones se pueden usar con varios tipos de archivos no solo con .csv, además por lo general reconoce los separadores que usan.
library(data.table)
iris_table <- fread("~/R_sites/Seminario_Estadistica/data/iris.csv", header = TRUE)En el caso de archivos .xlsx, usamos el paquete readxl y la función para importar archivos es read_excel().
4.1.1 tibbles
Los tibbles son otro tipo de objetos de R del paquete tidyverse. Vamos a convertir el data frame iri en un objeto tibble usando la función as_tibble
## # A tibble: 150 × 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ℹ 140 more rowsEn estos objetos, cada columna ya tiene especificado de que tipo de datos se trata, además solo nos despliega las primeras 10 filas.
Para crear un tibble es similar a como creamos dataframes.
## # A tibble: 5 × 3
## x y z
## <int> <int> <int>
## 1 1 6 6
## 2 2 7 14
## 3 3 8 24
## 4 4 9 36
## 5 5 10 50Por default, coloca los nombres de las columnas y nunca le pone nombres a las filas. En estos objetos, es posible colocar nombres no válidos para R como símbolos, números, etc.
## # A tibble: 1 × 3
## `:)` ` ` `3c`
## <chr> <chr> <chr>
## 1 sonrisa espacio númerosOtra forma de crear estos objetos es con la función tribble, con esta función se puede especificar por renglón las entradas del objeto, se comienza escribiendo con ~ nombre el nombre de las columnas y después se especifican las entradas separadas por coma:
## # A tibble: 2 × 3
## A B C
## <chr> <dbl> <dbl>
## 1 x 1 1.5
## 2 y 2 2.5La forma en la que se accede a columnas es igual que en los data.frame, usando $ o [[nombre]].
4.2 Prepocesamiento de bases de datos
4.2.1 Paquete plyr
Muchas veces, tenemos nuestros datos y queremos agregar columnas o cambiar la forma de presentarlos.
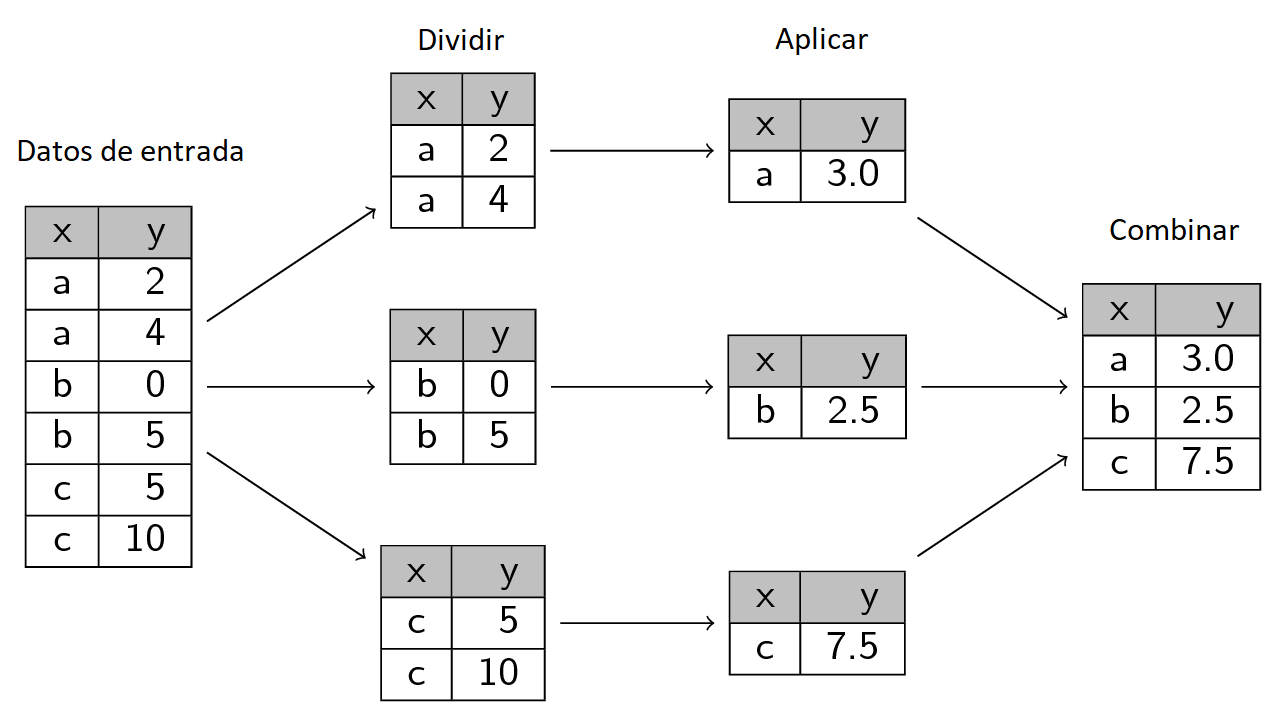
El paquete plyr contiene varias funciones que nos ayudan a resolver el problema de dividir, aplicar y combinar las bases de datos. Funciona con listas, data frames y arreglos.
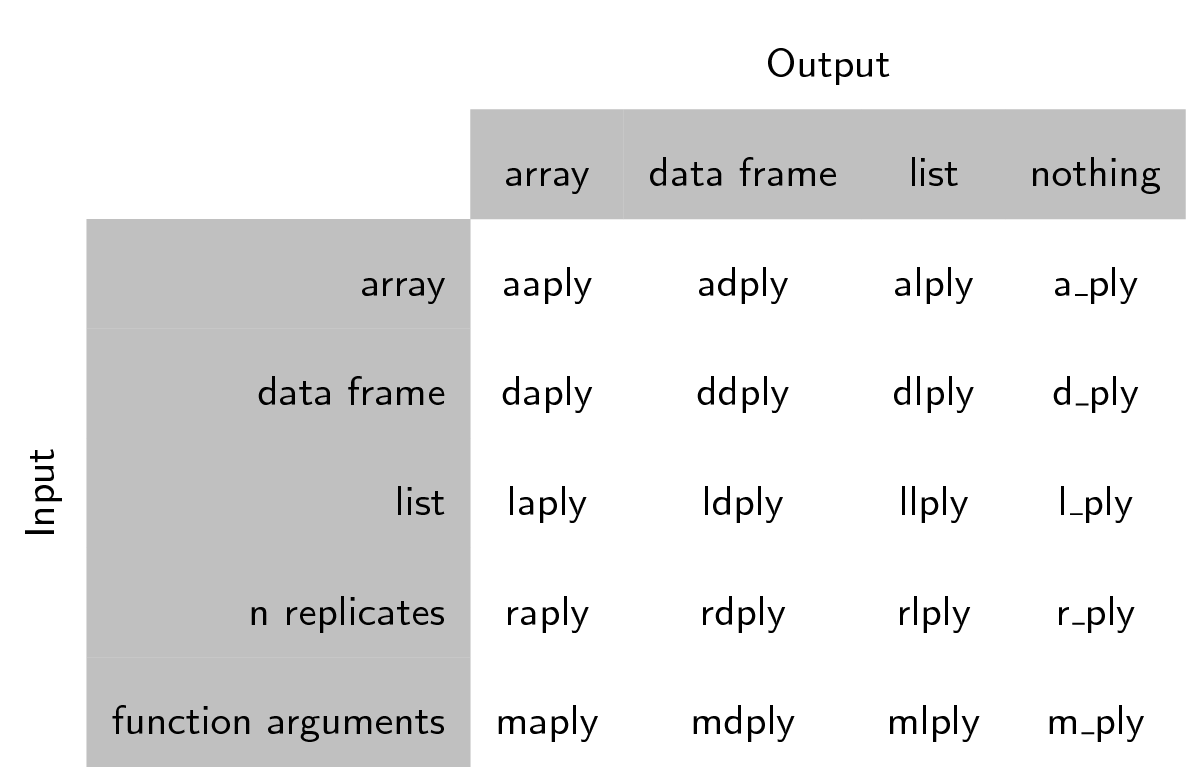
La estructura de estas funciones es como sigue:
Supongamos que en la base de datos gapminder y queremos calcular la media de la columna gdp que se optiene con la función calcGDP.
calcGDP <- function(dat, year=NULL, country=NULL) {
if(!is.null(year)) {
dat <- dat[dat$year %in% year, ]
}
if (!is.null(country)) {
dat <- dat[dat$country %in% country,]
}
gdp <- dat$pop * dat$gdpPercap
new <- cbind(dat, gdp=gdp)
return(new)
}## ------------------------------------------------------------------------------## You have loaded plyr after dplyr - this is likely to cause problems.
## If you need functions from both plyr and dplyr, please load plyr first, then dplyr:
## library(plyr); library(dplyr)## ------------------------------------------------------------------------------##
## Attaching package: 'plyr'## The following objects are masked from 'package:dplyr':
##
## arrange, count, desc, failwith, id, mutate, rename, summarise,
## summarize## The following object is masked from 'package:purrr':
##
## compact## continent V1
## 1 Africa 20904782844
## 2 Americas 379262350210
## 3 Asia 227233738153
## 4 Europe 269442085301
## 5 Oceania 188187105354## continent V1
## 1 Africa 20904782844
## 2 Americas 379262350210
## 3 Asia 227233738153
## 4 Europe 269442085301
## 5 Oceania 188187105354¿Si queremos el resultado como lista, que función deberíamos usar?
En las variables, puede ser que a veces queramos agrupar por no solo una, en ese caso colocamos todas las variables como vector.
ddply(.data = calcGDP(gapminder),
.variables = c("continent","year"),
.fun = function(x) mean(x$gdp))## continent year V1
## 1 Africa 1952 5992294608
## 2 Africa 1957 7359188796
## 3 Africa 1962 8784876958
## 4 Africa 1967 11443994101
## 5 Africa 1972 15072241974
## 6 Africa 1977 18694898732
## 7 Africa 1982 22040401045
## 8 Africa 1987 24107264108
## 9 Africa 1992 26256977719
## 10 Africa 1997 30023173824
## 11 Africa 2002 35303511424
## 12 Africa 2007 45778570846
## 13 Americas 1952 117738997171
## 14 Americas 1957 140817061264
## 15 Americas 1962 169153069442
## 16 Americas 1967 217867530844
## 17 Americas 1972 268159178814
## 18 Americas 1977 324085389022
## 19 Americas 1982 363314008350
## 20 Americas 1987 439447790357
## 21 Americas 1992 489899820623
## 22 Americas 1997 582693307146
## 23 Americas 2002 661248623419
## 24 Americas 2007 776723426068
## 25 Asia 1952 34095762654
## 26 Asia 1957 47267432088
## 27 Asia 1962 60136869012
## 28 Asia 1967 84648519224
## 29 Asia 1972 124385747313
## 30 Asia 1977 159802590186
## 31 Asia 1982 194429049919
## 32 Asia 1987 241784763369
## 33 Asia 1992 307100497486
## 34 Asia 1997 387597655323
## 35 Asia 2002 458042336179
## 36 Asia 2007 627513635079
## 37 Europe 1952 84971341466
## 38 Europe 1957 109989505140
## 39 Europe 1962 138984693095
## 40 Europe 1967 173366641137
## 41 Europe 1972 218691462733
## 42 Europe 1977 255367522034
## 43 Europe 1982 279484077072
## 44 Europe 1987 316507473546
## 45 Europe 1992 342703247405
## 46 Europe 1997 383606933833
## 47 Europe 2002 436448815097
## 48 Europe 2007 493183311052
## 49 Oceania 1952 54157223944
## 50 Oceania 1957 66826828013
## 51 Oceania 1962 82336453245
## 52 Oceania 1967 105958863585
## 53 Oceania 1972 134112109227
## 54 Oceania 1977 154707711162
## 55 Oceania 1982 176177151380
## 56 Oceania 1987 209451563998
## 57 Oceania 1992 236319179826
## 58 Oceania 1997 289304255183
## 59 Oceania 2002 345236880176
## 60 Oceania 2007 403657044512Tal vez, esta forma de visualizar esa información no es adecuado y nos conviene visualizarlo como un data.frame ¿qué función usaríamos?
Si queremos hacer algun loop for, usar las funciones del paquete que tienen _ puede ser mucho más rápido.
d_ply(.data = calcGDP(gapminder),
.variables = "continent",
.fun = function(x){
media <- mean(x$gdpPercap)
print(paste(
"La media de GDP per capita de" , unique(x$continent), "es",
format(media, big.mark=",")
))
}
)## [1] "La media de GDP per capita de Africa es 2,193.755"
## [1] "La media de GDP per capita de Americas es 7,136.11"
## [1] "La media de GDP per capita de Asia es 7,902.15"
## [1] "La media de GDP per capita de Europe es 14,469.48"
## [1] "La media de GDP per capita de Oceania es 18,621.61"4.2.1.1 Ejercicios
Calcula la media la esperanza de vida por continente y año y preséntala como un data.frame. ¿Cuál continente tuvo la mayor y menor esperanza de vida en el año 1952 y 2007?
Carga la base de datos
iris, y crea un data.frame con la media, el valor máximo y mínimo de cada una de las variables agrupado por especie.Explora la página y busca una base de datos donde puedas aplicar las funciones anteriores y que tenga sentido lo que estás presentando de resultados.
4.2.2 Paquete dplyr
El paquete dplyr contiene varias funciones que nos ayudan a realizar operaciones en los data.frames de tal forma que reduce el repetir estas operaciones o cometer errores al momento de combinar los resultados. Algunas de las funciones de este paquete son:
filter()select()count()arrange()group_by()mutate()summarize()transmute()ungroup()slice_min()slice_max()left_join()
Instalamos el paquete dplyr y lo cargamos.
Nota: Este paquete tiene algunos conflictos con el paquete plyr dependiendo de cual se carga primero o algunas funciones que tienen en común y que sus argumentos son diferentes. Para evitar esta confusión se puede usar la sintaxis dplyr::funcion.
Vamos a trabajar con el set de datos de Marvel vs DC, ve a la página y descarga las bases de datos en formato csv.
Cargamos las 3 bases de datos de Marvel vs DC. Vamos a usar la instrucción na.strings = c("-", "-99") para sustituir los valores - y 99 por NA.
infoHeroes <- read.csv("data/heroesInformation.csv", na.strings = c("-", "-99", "-99.0"))
infoPowers <- read.csv("data/superHeroPowers.csv")
infoStats <- read.csv("data/charactersStats.csv", na.strings = "")Unificamos el nombre de la columna en las 3 bases de datos del nombre de los personajes a Name.
4.2.2.1 filter()
El verbo filter nos permite filtrar las columnas por una o más condiciones. Por ejemplo, si queremos seleccionar de la base de datos infoHeroes solo los personajes de DC o Marvel, realizariamos lo siguiente:
Si exploramos la base de datos, vamos a ver que existen personajes duplicados. Esto también lo podemos obtener con la siguiente instrucción.
Usando el mismo verbo de filter podemos eliminar los personajes duplicados como sigue.
4.2.2.2 select()
El verbo select nos permite seleccionar columnas de nuestro dataframe.
Ejercicio: ¿Qué otras columnas son de tu interés de la base de datos o de las otras dos bases de datos? ¿Como las seleccionarías?
Ejercicio: Busca la ayuda de ?select_helpers. ¿Cómo podrías usar alguno de estos en la base de datos?
4.2.2.3 count()
El verbo count nos permite contar cuantos elementos de cada tipo hay en las columnas que indiquemos. Por ejemplo, si volvemos a cargar la base de datos inicial de DC_Marvel, con la siguiente instrucción podríamos obtener de nuevo cuales son los personajes que están repetidos.
Si queremos saber cuantos personajes hombres y mujeres hay en la base de datos, realizariamos lo siguiente.
También podemos especificar más de una columna. Por ejemplo, para saber cuantos personajes hay de cada compañía y de que géndero son.
¿Qué pasa si intercambiamos el orden de las variables en el verbo count?
Ejercicio: De la base de datos infoStats, como encontrarías cuántos personajes son buenos y cuántos son malos? ¿Y de cada compañía?
4.2.2.4 arrange()
El verbo arrange nos permite ordenar la base de datos de acuerdo a alguna varible ya sea en orden ascendente o descendente indicando la opción desc.
Seleccionaremos primero las columnas Name, Gender, Race, Height, Publisher.
Para odernarlos en orden ascendente por la columna Height hacemos lo siguiente.
Los verbos los podemos anidar usando el operador pipe %>%. Por ejemplo podemos realizar las dos instrucciones anteriores de una sola vez.
Algunos operadores no importa el orden en que los usemos.
4.2.2.5 group_by()
El verbo group_by nos permite agrupar por alguna variable.
Este verbo nos devuelve en realidad una lista donde cada elemento es un data.frame en el que las filas corresponden a la variable por la que se agrupo.
Este verbo visualmente no hace nada, tiene efecto cuando agregamos algún otro verbo. Por ejemplo, vamos a contar cuantos personajes son Humanos de cada compañía.
4.2.2.6 sumarize()
El verbo sumarize() nos permite realizar alguna operación sobre las variables y/o agregarlas a la base de datos. Algunas de las operaciones que se pueden usar son:
mean()max()min()sum()median()n()
La opción na.rm=TRUE se usa para eliminar los NA que aparecen en esa columna.
4.2.2.7 mutate()
El verbo mutate() nos permite crear nuevas variables o agregar columnas al data.frame. De la base de datos infoStats vamos a calcular una nueva variable que relacione Poder y Combate.
infoStats %>%
mutate(resistencia = Power/Combat) %>%
group_by(Alignment) %>%
summarize(resistencia_p = mean(resistencia), resistencia_max = max(resistencia),
resistencia_min =min(resistencia))Dentro del verbo mutate se pueden incluir condicionales.
4.2.2.9 left_join()
Existen varios verbos que nos ayudan a unir bases de datos dependiendo de las columnas o filas.
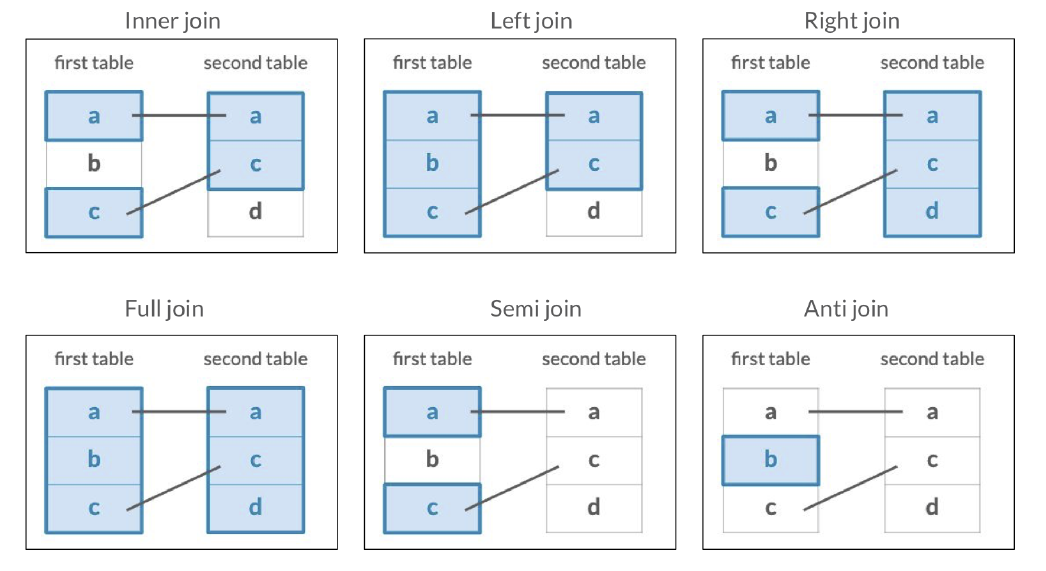 Vamos a realizar dos uniones, primero vamos a unir la base de datos filtrada
Vamos a realizar dos uniones, primero vamos a unir la base de datos filtrada DC_Marvel_s con la información de infoStats por Name.
Ahora, vamos a unir esta nueva base con la de infoPowers
4.2.2.10 Ejercicios
- Usa la base de datos
full_DC_Marvel. Usa los verbos que acabamos de ver para responder las siguientes preguntas.
- ¿Cuántos personajes hay?
- ¿Cuántos personajes hay de cada compañía?
- ¿Cuántos personajes hay de cada género en cada compañía?
- ¿Cual es la raza predominante en cada compañía?
- ¿Cuántos son villanos y cúantos son héroes?
- ¿Quién es el personaje más fuerte?
- ¿Quién es el personaje más inteligente?
- ¿Quién es la mujer más poderosa y malvada? ¿De que compañía es?
- ¿Quién es el hombre más poderoso y bueno? ¿De que compañía es?
- Selecciona a
SupermanyIron Man, compara sus Stats, ¿Quién tiene mejor Stats?
- Explora los verbos
ungroup(),slice_min(),slice_max(). ¿Cómo los podrías usar en la base de datos. Crea un ejemplo con cada uno.